今天来讨论一下C# list<T> 的一些机制,有什么不对的错误的地方请各位即使支出,不甚感激。。
List<T> 简介
一,List<T> 是非线程安全集合
我在看List<T>源码时找到SynchronizedList这个类,从这个名字上及从他的代码实现来看其就是一个线程安全的集合,但是不清楚这个SynchronizedList和List<T> 是如何配合实现线程安全的,或是这个方法只是给FCL类库使用? 哪位知道的话可以解惑一下。。


[Serializable()] internal class SynchronizedList : IList<T> { private MyList<T> _list; private Object _root; internal SynchronizedList(MyList<T> list) { _list = list; _root = ((System.Collections.ICollection)list).SyncRoot; } public int Count { get { lock (_root) { return _list.Count; } } } public bool IsReadOnly { get { return ((ICollection<T>)_list).IsReadOnly; } } public void Add(T item) { lock (_root) { _list.Add(item); } } public void Clear() { lock (_root) { _list.Clear(); } } public bool Contains(T item) { lock (_root) { return _list.Contains(item); } } public void CopyTo(T[] array, int arrayIndex) { lock (_root) { _list.CopyTo(array, arrayIndex); } } public bool Remove(T item) { lock (_root) { return _list.Remove(item); } } System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator() { lock (_root) { return _list.GetEnumerator(); } } IEnumerator<T> IEnumerable<T>.GetEnumerator() { lock (_root) { return ((IEnumerable<T>)_list).GetEnumerator(); } } public T this[int index] { get { lock (_root) { return _list[index]; } } set { lock (_root) { _list[index] = value; } } } public int IndexOf(T item) { lock (_root) { return _list.IndexOf(item); } } public void Insert(int index, T item) { lock (_root) { _list.Insert(index, item); } } public void RemoveAt(int index) { lock (_root) { _list.RemoveAt(index); } } }
2,List<T>内部数据结构比较简单,没有hashtable和Dictionary那样用到哈希算法,其内部默认的数组长度是4,最大支持长度为2146435071,List<T>没有类似Hashtable的装载因子概念,也可以理解为List<T>的装载因子是1,当执行add方法时,都要判断当前list容量和已使用的容量是否相等,如果相等则进行扩容,扩容的规则是当前容量的两倍。
3,list内部添加的元素是顺序的,内部有一个_size变量,每次执行add时,_size加一。
二,关于List<T>和Dictionary 的性能比较。
虽然他们之前可比性不是太强,但这里还是就常用的添加,查找,删除方法做一个比较。
1) 添加新元素
从理论上来说List<T>的ADD()要比Dictionary快,因为List<T>少了hash计算。从实际试验上来看也确实这样。
static void Main(string[] args) { for (int i = 0; i < 10; i++) { List<int> myList = new List<int>(); Dictionary<int, int> myDict = new Dictionary<int, int>(); Stopwatch swatch = new Stopwatch(); swatch.Restart(); for (int j = 0; j < 100000; j++) { myList.Add(j); } swatch.Stop(); Console.WriteLine("myList:" + swatch.ElapsedTicks); swatch.Restart(); for (int j = 0; j < 100000; j++) { myDict.Add(j, j); } swatch.Stop(); Console.WriteLine("myDict:" + swatch.ElapsedTicks); Console.WriteLine("------------------------------"); } Console.ReadKey(); }
执行结果:
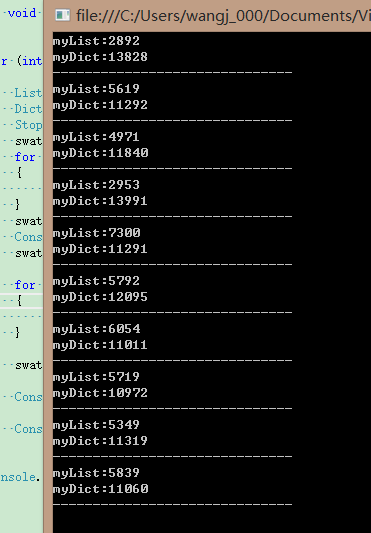
从上图可知,List<T> 要比Dictionary快一个数量级。
2)查找元素
Dictionary的查找要比list快多了,极端情况下会快几个数量级,
通过前面的文章我们知道Dictionary是先计算key的hash值,然后通过hash值进行索引定位,而list是先for循环,然后在与传入的表达式值进行比较,如下代码:
public T Find(Predicate<T> match) { if( match == null) { ThrowHelper.ThrowArgumentNullException(ExceptionArgument.match); } Contract.EndContractBlock(); for(int i = 0 ; i < _size; i++) { if(match(_items[i])) { return _items[i]; } } return default(T); }
接下来我们来测试两种极端情况下的性能比较:
情况一:
static void Main(string[] args) { for (int i = 0; i < 10; i++) { List<int> myList = new List<int>(); Dictionary<int, int> myDict = new Dictionary<int, int>(); Stopwatch swatch = new Stopwatch(); for (int j = 0; j < 10000000; j++) { myList.Add(j); } swatch.Start(); var myListResult = myList.Find(p => { return p == 9999999; }); swatch.Stop(); Console.WriteLine("myList:" + swatch.ElapsedTicks); for (int j = 0; j < 10000000; j++) { myDict.Add(j, j); } swatch = new Stopwatch(); swatch.Start(); var myDictResult = myDict[9999999]; swatch.Stop(); Console.WriteLine("myDict:" + swatch.ElapsedTicks); Console.WriteLine("------------------------------"); } Console.ReadKey(); }
结果: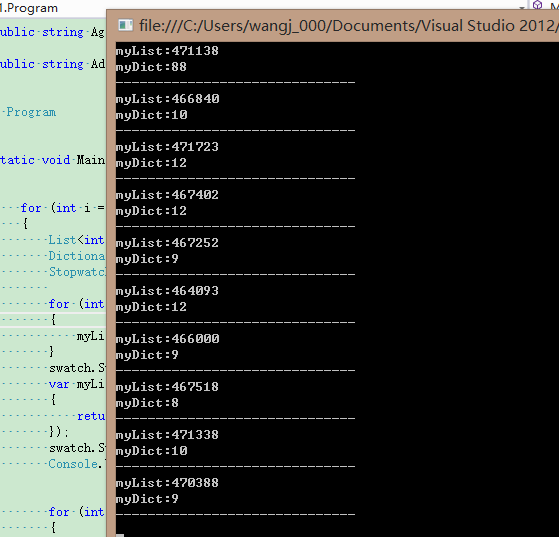
情况二:
static void Main(string[] args) { for (int i = 0; i < 10; i++) { List<int> myList = new List<int>(); Dictionary<int, int> myDict = new Dictionary<int, int>(); Stopwatch swatch = new Stopwatch(); for (int j = 0; j < 10000000; j++) { myList.Add(j); } swatch.Start(); var myListResult = myList.Find(p => { return p == 0; }); swatch.Stop(); Console.WriteLine("myList:" + swatch.ElapsedTicks); for (int j = 0; j < 10000000; j++) { myDict.Add(j, j); } swatch = new Stopwatch(); swatch.Start(); var myDictResult = myDict[0]; swatch.Stop(); Console.WriteLine("myDict:" + swatch.ElapsedTicks); Console.WriteLine("------------------------------"); } Console.ReadKey(); }
结果: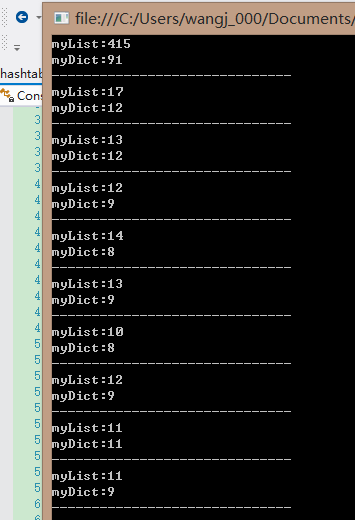
我们看到第二种极端情况下 List<T> 反而比Dictionary快,结合前面的文章,想必各位已经知道的其中的原因,
3)移除元素
List<T>的Remove 方法在移除元素时先计算元素的索引值,然后把索引值传给RemoveAt方法移除元素。所以通过这个就知道移除元素时也是Dictionary完爆List<T>,其他的不多说了,直接上源码上图。
static void Main(string[] args) { for (int i = 0; i < 10; i++) { MyList<int> myList = new MyList<int>(); Dictionary<int, int> myDict = new Dictionary<int, int>(); Stopwatch swatch = new Stopwatch(); for (int j = 0; j < 10000000; j++) { myList.Add(j); } swatch.Start(); myList.Remove(55555); swatch.Stop(); Console.WriteLine("myList:" + swatch.ElapsedTicks); for (int j = 0; j < 10000000; j++) { myDict.Add(j, j); } swatch = new Stopwatch(); swatch.Start(); var myDictResult = myDict.Remove(55555); swatch.Stop(); Console.WriteLine("myDict:" + swatch.ElapsedTicks); Console.WriteLine("------------------------------"); } Console.ReadKey(); }
运行结果:
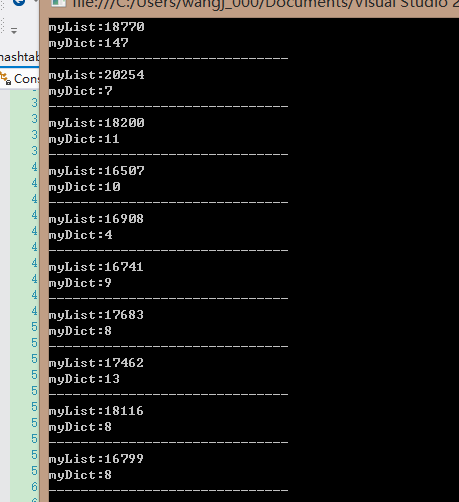
我个人认为导致他们在插入和删除元素的性能相差如此之大的最根本原因是:Dictionary用到的hash,而List没有,即使Dictionary的hash计算有一定的性能损耗,但整体性能还是完爆List.
下一节来介绍ArrayList的实现,实际上ArrayList和list可比性更强些。