вЛЁЂв§бд
ЁЁЁЁЙХгягадЦЃК“ЛюЕНРЯбЇЕНРЯ”ЁЃБэДяГівЛжж“ЩњУќВЛжЙЃЌбЇЯАВЛжЙ”ЕФбЇЯАНјШЁОЋЩёЃЌЪЧвЛжжРжЙлЕФМЄРјЃЁзїЮЊГЬађдБИќгІИУШчДЫЃЌЗёдђОЭЛсБЛЬдЬЁЃНёЬьЮвЫљвЊНВЕФВЛЪЧШчКЮШЅбЇЯАЃЌЖјЪЧдѕУДдкЭјЩЯевЕНЮвУЧЫљашЧѓЕФзЪдДЁЃ
ЖўЁЂАйЖШЭјХЬЫбЫїЗНЗЈ
ЁЁЁЁевзЪдДЕФЗНЗЈгаКмЖрЃЌШчЃКАйЖШЃЌЙШИшЫбЫїЁЃЖјЮвНВЕФЪЧШчКЮЫбЫї“АйЖШЭјХЬ”РяУцЕФзЪдДЁЃ
ЁЁЁЁОпЬхЗНЗЈЃКдкЫбЫїв§ЧцжаЫбЫїЃКsite:pan.baidu.com ЙиМќДЪЃЌШчЯТЭМЁЃЧзВтБигІЃЌЙШИшПЩвдЁЃ
ЁЁЁЁ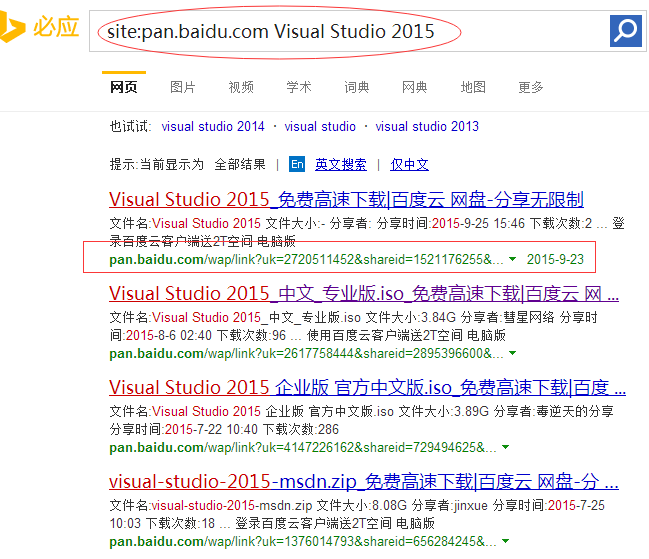
Ш§ЁЂаДСЫвЛИіГЬађ
ЁЁЁЁЮЊСЫздМКЫбЫїЗНБуЃЌЫїадаДСЫвЛИіГЬађШЅХРШЁБигІЕФЫбЫїНсЙћЃЌШчЯТЭМЁЃбнЪОЕижЗЃКhttp://139.129.12.162/ResourcesCrawl
ЁЁЁЁ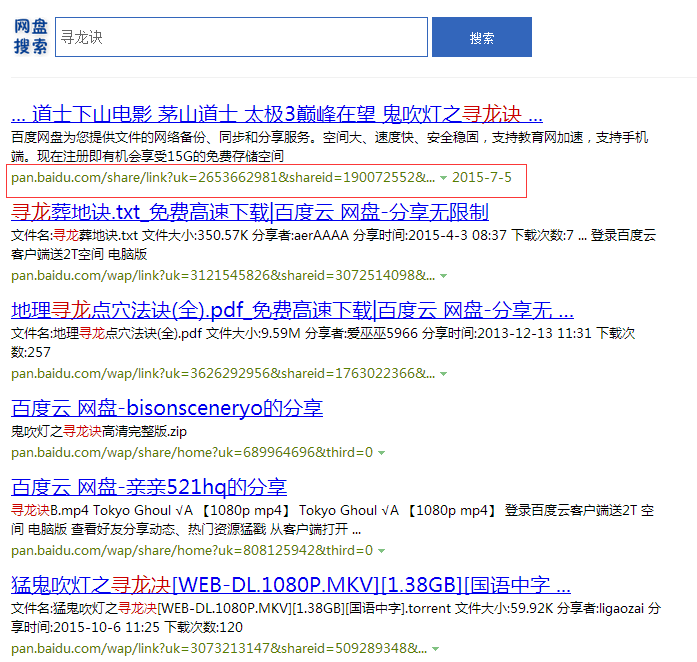
ЫФЁЂГЬађНщЩм
ЁЁ 1ЁЂЭЈЙ§зЅАќЙЄОпЃЌЗжЮіБигІЫбЫїЕФurlЃЌШчЯТЭМЁЃЮвУЧзюжеПЩвдЛёШЁЕНЃКhttp://cn.bing.com/search?q=ЙиМќДЪ&first=ЕкМИЬѕПЊЪМ
ЁЁ ЁЁЁЁ2ЁЂЯђДЫurlЃЈhttp://cn.bing.com/search?q=site:pan.baidu.com ЙиМќДЪ&first=ЕкМИЬѕПЊЪМЃЉЗЂЦ№HttpЧыЧѓЃЈGETЗНЪН)ЃЌЕУЕНhtmlЃЌЭЈЙ§е§дђБэДяЪНКЭxPathНтЮідДДњТыЃЌЬсШЁаХЯЂЁЃ
ЁЁЁЁ2ЁЂЯђДЫurlЃЈhttp://cn.bing.com/search?q=site:pan.baidu.com ЙиМќДЪ&first=ЕкМИЬѕПЊЪМЃЉЗЂЦ№HttpЧыЧѓЃЈGETЗНЪН)ЃЌЕУЕНhtmlЃЌЭЈЙ§е§дђБэДяЪНКЭxPathНтЮідДДњТыЃЌЬсШЁаХЯЂЁЃ
ЁЁЁЁ3ЁЂДњТыИХРРЁЃ
ЁЁЁЁ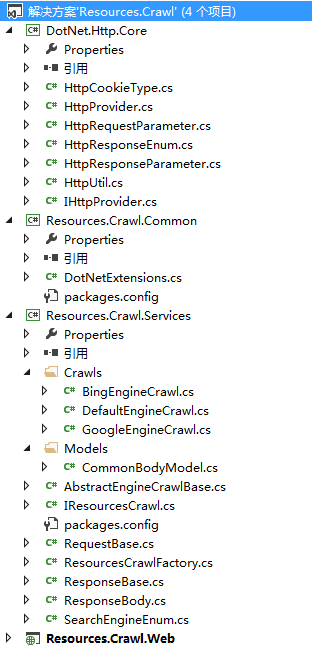
*DotNet.Http.CoreЃКHttpЧыЧѓзЈгУПтЁЃ
*Resouces.Crawl.CommonЃКвЛаЉ.NetРЉеЙЗНЗЈЁЃ
*Resource.Crawl.ServicesЃКНтЮіHtmlдДДњТыЃЌВЂЗЕЛиаХЯЂЕФПтЁЃ
*Resource.Crawl.WebЃКеЙЪОВуЁЃ
ЮхЁЂдДТыЯТдиЃЈVisual Studio 2013ЃЉ
ЁЁЁЁАйЖШЭјХЬЫбЫїГЬађ
- 2ТЅasos
- ЫйЖШгаЕуТ§
- Re: ЧрЗчзЙ
- @asosЃЌЙКТђЕФЗўЮёЦїХфжУгаЕуЕЭ
- 1ТЅЩБЪПБШбЧ
- ФЄАнДѓЩёЃЌЯёЧыНЬЯТВЉжїЃЌХРГцГЬађЪЧгУЪВУДгябдаДЕФЃЌБОШЫЪЧвЛИіИеШыааЕФjavaГЬађдБЃЌЖдХРГцЗНУцЕФжЊЪЖКмИааЫШЄЃЌЯыжЊЕРвЊбЇЛсаДХРГцГЬађвЊгаЪВУДжЊЪЖЃЌЛђепгаЪВУДЪщПЩвдНщЩмЯТТ№ЃПИааЛВЉжїЗжЯэ
- Re: ЧрЗчзЙ
- @ЩБЪПБШбЧЃЌHttpЧыЧѓавщЃЌе§дђБэДяЪН