�������������windows����������ͨ��mvn+eclipse����hadoop��Ŀ������
�ر�����
- windows7����ϵͳ
- eclipse-4.4.2
- mvn-3.0.3����mvn������Ŀ�ܹ�(����http://blog.csdn.net/tang9140/article/details/39157439)
- hadoop-2.5.2��ֱ����hadoop����http://hadoop.apache.org/����hadoop-2.5.2.tar.gz����ѹ��ij��Ŀ¼��
windows7�»�������
1������hadoop��������
���ӻ�������HADOOP_HOME=E:\doc_api\ebook\hadoop-2.5.2
�ӻ�������path���ݣ�%HADOOP_HOME%\bin
2��bin������hadoop.dll,winutils.exe�ļ�
��https://github.com/srccodes/hadoop-common-2.2.0-bin��ӡ�������hadoop.dll,winutils.exe�����õ�${HADOOP_HOME}\binĿ¼��
����hadoop��Ŀ
�����Ծ����WordCountΪ�����������ǵ�һ��hadoop��Ŀ��
- ����
pom�ļ��м���������
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.5.2</version></dependency><dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.5.2</version></dependency><dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.5.2</version></dependency><dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-common</artifactId> <version>2.5.2</version></dependency>- ��дWordCount������
import java.io.IOException;import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.conf.Configured;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;import org.apache.hadoop.util.Tool;import org.apache.hadoop.util.ToolRunner;/** * @version 1.0 * @author tangqian */public class WordCount extends Configured implements Tool { public static void main(String[] args) throws Exception { int result = ToolRunner.run(new Configuration(),new WordCount(), args); System.exit(result); } @Override public int run(String[] args) throws Exception { Path inputPath, outputPath; if(args.length == 2){ inputPath = new Path(args[0]); outputPath = new Path(args[1]); }else{ System.out.println("usage <input> <output>"); return 1; } Configuration conf = getConf(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, inputPath); FileOutputFormat.setOutputPath(job, outputPath); return job.waitForCompletion(true) ? 0 : 1; } public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); @Override public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum += value.get(); } result.set(sum); context.write(key, result); } }}Ȼ���ڸ������Ҽ�Run As->Run Configurations->Arguments��ǩ��Program arguments��ָ������·�������·�����£�
file:///e:/word.txt file:///e:/hadoop/result2��Run�������и��࣬��ʱ����Console���������Ϣ������ɺɵ�e:/hadoop/result2��������ļ�part-r-00000��������
is 1test 2this 1two 1˵�����������ڱ���hadoop����ģʽ�����У��ʲ��ñ����ļ�ϵͳ����file://��ͷָ���������·������
��
hadoop-2.5.2��Ⱥ��װָ��(����http://blog.csdn.net/tang9140/article/details/42869531)
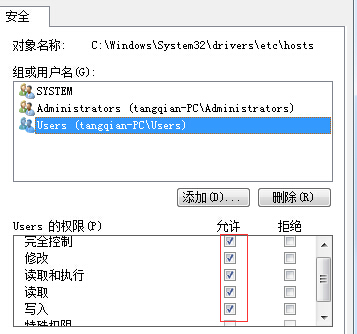
�����Windows7�µ�hosts�ļ���
hosts�ļ�һ����C:\Windows\System32\drivers\etcĿ¼�£���windows7��������ǹ���Ա���ݵ�¼��������Ȩ���ģ���ʱ���Ҽ�hosts�ļ�->����->��ȫ->�༭��ѡ��ǰ��¼�û���������Ȩ���ɣ������������ͼ��