我真的见识了什么叫压缩,22M文本解压后是560M。
==================================================
500wM的大数据,这个怎么处理呢,用我的V1.0很明显就不行啊,光跑个TopN_IP就得半天。
只能推翻1.0,重新架构2.0了。
一.想法
(1)把这个大文件分为n份,因为是500M,我觉得分成100+份,每一份是5M,也就是5242880。
import os.path# To change this template, choose Tools | Templates# and open the template in the editor.__author__="ouyang, blog.csdn.net/xihuanqiqi"__date__ ="$2012-11-6 10:28:45$"from time import ctimeimport osif __name__ == "__main__": #把文件分成100+份小文 infile = "D:/20_u_ex120317.log"#待处理文件 if False == os.path.exists("D:/outputs_log_2012"): os.makedirs("D:/outputs_log_2012") f = file(infile,"r") blocksize = 5242880 length = 0 fcnt = 0 buffer = [] while True: tmpline = f.readline() if tmpline == "": break if (length + len(tmpline)) > blocksize: buffer.append(tmpline) ftmp = file("D:/outputs_log_2012/"+str(fcnt)+".txt","w") ftmp.writelines(buffer) ftmp.close() print "处理 "+str(fcnt)+".txt at "+str(ctime()) fcnt += 1 length = 0 buffer = [] else: buffer.append(tmpline) length += len(tmpline) f.close() print "结束了:共"+str(fcnt)+"个文件!"处理结果:
(2)开n个线程跑出各自的TopN_IP,然后写到文件b中
Ps:尼玛啊,追加文件不是神马“w+”,而是“a”啊!!!
Ps:尼玛啊,out_of_memory啊。。。内存不够用啊。。。
实验证明:当线程数达到40就会:java.lang.OutOfMemoryError: Java heap space,内存不够用!!
所以只能开30个线程,然后分成4次去跑脚本了,为了能够分四次,还新加了些变量如fcnt,cnt等
import os.pathimport osfrom time import ctimeimport threading#没办法。。因为线程太多了,内存跑不动,。就分四次跑完,然后outfile要设定文件numberb1,b2..4fcnt = 90 #这个数字根据分割大文件后的fcnt而设定,从90开始cnt = 24 #这个是线程数outfile = "D:/b5.txt"infile = "D:/outputs_log_2012/"IP_INDEX = 8 #这个数字是根据在log中IP排在第几个位置来填写的,毕竟IIS的日志很规范mutex = threading.Lock() #创建线程锁,毕竟读文件存在竞争def getTopN_IP(i,n,infile,outfile): IPs = [] isRegetIP = False try: if False == isRegetIP: f = file(infile,"r") while True: tmpLine = f.readline() if tmpLine == "": break tmpList = tmpLine.split(' ') #print tmpList IPs.append(tmpList[IP_INDEX]) f.close() except: print tmpLine print "尼玛,楼上那行出错了,应该是格式错误..." #去重这句话好简单时尚啊~ singleIP = {}.fromkeys(IPs).keys() IPDict = {} for tmp in singleIP: IPDict[tmp] = 0; for tmp in IPs: IPDict[tmp] += 1 #对字典进行排序key=lambda e:e[1]表示对value排序。key=lambda e:e[0]对key排序 #IPDict.items()把字典搞成元祖集合的形式 #lambda就是匿名函数中,语句中冒号前是参数,可以有多个,用逗号隔开,冒号右边的返回值。 sortIP=sorted(IPDict.items(),key=lambda e:e[1],reverse=True) #以上排序完毕了,我们已经根据topN的N来写入到文件中,记得加锁 index = 0 topN_IP= [] for tmp in sortIP: index += 1 if index > n : break #因为元组(IP,个数),所以就是这么获取ip topN_IP.append(str(tmp[0])+"\r\n") out = open(outfile,'a') if mutex.acquire(5): out.writelines(topN_IP) mutex.release() out.close() print "处理完毕,文件:"+str(i)+".txt at "+str(ctime())if __name__ == "__main__": if True ==os.path.isfile(outfile): #文件存在则删除。。避免重复追加 os.remove(outfile) th=[] for i in range(fcnt,fcnt+cnt): print "正在处理文件:"+str(i)+".txt at "+str(ctime()) tmpth = threading.Thread(target = getTopN_IP,args = (i,10,infile+str(i)+".txt",outfile)) th.append(tmpth) tmpth.start() for i in range(0,cnt): th[i].join() print "恭喜你,处理完毕~~"处理结果:
(3)对b中文件再一次进行排序,把最终的TopN_IP写到文件c中
from time import ctimeinfile = "d:/outputs_b/all_b.txt"outfile = "d:/ouputs_c.txt"n = 10if __name__ == "__main__": IPs = [] f = file(infile,"r") while True: tmpline = f.readline() if tmpline == "": break IPs.append(tmpline) f.close() #去重这句话好简单时尚啊~ singleIP = {}.fromkeys(IPs).keys() IPDict = {} for tmp in singleIP: IPDict[tmp] = 0; for tmp in IPs: IPDict[tmp] += 1 #对字典进行排序key=lambda e:e[1]表示对value排序。key=lambda e:e[0]对key排序 #IPDict.items()把字典搞成元祖集合的形式 #lambda就是匿名函数中,语句中冒号前是参数,可以有多个,用逗号隔开,冒号右边的返回值。 sortIP=sorted(IPDict.items(),key=lambda e:e[1],reverse=True) index = 0 topN_IP= [] for tmp in sortIP: index += 1 if index > n : break #因为元组(IP,个数),所以就是这么获取ip topN_IP.append(str(tmp[0])) out = open(outfile,'a') #if mutex.acquire(5): out.writelines(topN_IP) #mutex.release() out.close() print "处理完毕文件 at "+str(ctime()) 最终结果: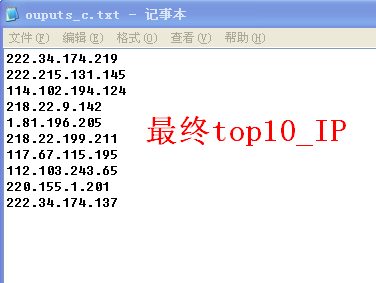
至此我们通过半自动化的脚本得到了我们要的前10个IP,这些IP在这段时间内的访问量特别惊人,那么就不怪我们把这些IP当成扫描器了!
二.想法之后的实践--获取TOP10_IP的字典
from re import searchfrom time import ctimeinfile = "d:/outputs_c.txt"outfile = "d:/outputs_d.txt"datafile = "d:/20_u_ex120317.log"KEYWORD_INDEX = 4if __name__ == "__main__": #装载TOPN_IP topN_IP = [] f = file(infile,"r") while True: tmpline = f.readline() if tmpline == "": break if tmpline != "\n": topN_IP.append(tmpline[0:len(tmpline)-2]) #减去末尾的/r/n这两个字符 f.close() print topN_IP print "begin at "+str(ctime) f2 = file(datafile,"r") keywords = [] while True: tmpline = f2.readline() if tmpline == "": break for i in topN_IP: if search(i,tmpline): tmplist = tmpline.split(' ') if tmplist[KEYWORD_INDEX] == "/": continue keywords.append(tmplist[KEYWORD_INDEX]+"\r\n") print tmplist[KEYWORD_INDEX] break f2.close() out = file(outfile,"w") out.writelines(keywords) out.close() print "恭喜您,处理完毕! at ~"+str(ctime)提取出来得字典部分如下:
/css/style.css/yszgks/style-ks.css/images/banner.gif/images/pic-wsbm.gif/images/body-bg.gif/images/pic-cjcx.gif/images/pic-kwgl.gif/frame/bf/images/pixviewer.swf/images/list_square.gif/images/fm.gif/images/dot-bg.gif/images/bottom-bg.gif/frame/images/common.js/frame/images/Scrollwindow.js/frame/images/check.js/frame/images/style.css/frame/images/clock.js/images/image014.jpg一点用都没有!白费了一天的功夫去提取!!!
这说明了TOPN_IP这个想法提取的字典,对一些正常不被攻击的IIS来说,起到的作用小,提取到的都是些普通的URI。
我现在甚至不想去用dirty keyword方法去提取字典了,因为TOPN_IP都提不出来(注意:扫描器的访问量绝对是远大于普通用户的访问量)。
不过呢,总算是完成了字典开发的2,.0版本。思想就是统计TOPN_IP扫描过的URI。