当前位置:
代码迷
>>
Java相关
>> htmlparser中文乱码有关问题
详细解决方案
htmlparser中文乱码有关问题
热度:
99
发布时间:
2016-04-22 21:33:07.0
htmlparser中文乱码问题
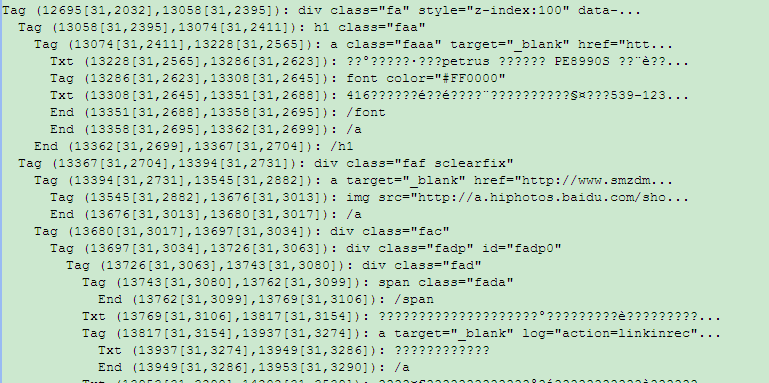
我在得到html信息的时候从一个网页得到的节点列表中中文是乱码,如图:
求大神帮忙解决一下,怎么设置编码就不会出现乱码了?
htmlparser
乱码
分享到:
------解决方案--------------------
获取下html页面的编码。用html的编码解析
查看全文
相关解决方案
org.htmlparser.util.EncodingChangeException: character
哪位高手知道org.htmlparser.StringNode在哪个版本的jar包
【HtmlParser】提取网页的meta信息解决方法
使用ASIHTTPRequest 编译提示找不到libxml/HTMLparser.h的解决方法