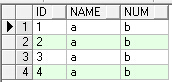
字段1 字段2 字段3
1 a b
2 a b
3 a b
------解决思路----------------------
delete from T T1
WHERE EXISTS (SELECT 1 FROM T
WHERE 字段2=T1.字段2
AND 字段3=T1.字段3
AND ROWID<T1.ROWID)
------解决思路----------------------
1、利用分析函数 ROW_NUMBER、ROWID
2、重复数据很多的话,可以导入到中间表,然后删除原表?最后RENAME,重建约束和索引
------解决思路----------------------
把不重复的行导到一张新表中,再清空原表,再导回来
注意备份。。
------解决思路----------------------
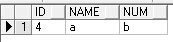
delete from test_del a where rowid !=(select max(rowid) from test_del b where a.name=b.name and a.num=b.num)
------解决思路----------------------
DELETE FROM temp WHERE ROWID IN (
SELECT MAX(ROWID) FROM temp
GROUP BY name,num
HAVING COUNT(*)>=2);
COMMIT;
------解决思路----------------------
这个方法不错的。
------解决思路----------------------
推荐4楼。
不过感觉建中间表更快
------解决思路----------------------
4#的这种写法子查询每次都要遍历全表的,而exists 的写法找到一条就直接返回了
只能说4#这种写法比较直观容易理解,执行效率就不好说了
如果数据量不大,用哪种都可以,差别不大,大数据量的话推荐exists的写法
------解决思路----------------------
我不太同意。如果只是找出,exists效率高呢。
这个感觉效率相差不是很多,这里是要删除重复行,所以要找到,然后剔除。一行找到之后并不返回,要继续往下查找下一个是否重复;有多行呢,还是要一一找出,全部剔除的。
------解决思路----------------------
delete
from (select b.name,
b.id,
row_number() over(partition by b.id, b.name order by b.id) nums,
rowid as rid
from BAS_PRODUCTMODEL_TEST b) t
where t.nums > 1
把表替换下,b.id,b.name是重复依据。
------解决思路----------------------
数据量多大?几百万?还是几千万?