摘要
恶意软件攻击已经开始渗透到很多的信息系统中。传统的基于签名的恶意检测算法只能检测到已知在库中的恶意软件,并且可以做诸如二进制混淆的规避攻击,但是基于行为的方法在很大程度上依赖于恶意的训练样本,并且会有很高的训练成本。为了解决现有技术的局限性,作者提出了MatchGNet,一种异质图匹配网络可以学习图表示和相似性度量。作者还提出了一种对于模型的系统性评估手段,可以以较小的FP值来检测恶意攻击。MatchGNet比现有的SOTA算法都要好,在保证FN值为0的同时将FP值降低了50%。
Introduction
随着信息系统在诸如金融服务和零售商服务的很多现代工业中扮演了重要的角色,网络安全在日常的系统管理中起着重要的作用。现在的网络攻击有很多,包括金融损失,泄漏消费者的敏感信息等。在这些攻击中,恶意攻击是最为广泛的,在很多的公司和组织都有存在。一项研究表明,在2016年到2017年之间,98%的公司都有遭受过恶意攻击。并且这些公司的的攻击成本平均都在2.4百万美元左右。
对于恶意攻击的检测主要包括如下两种方法:一种是基于签名的,一种是基于行为的。基于签名的方法是通过对于已有的恶意数据库中的签名做查询从而判断是属于哪种恶意攻击。基于签名的方法被广泛用于抗病毒的软件,因为这种方法的耗时很低。但是这种方法只能检测出来已有的数据库中的恶意攻击行为。现在,这种基于签名的检测不能解决zero-day恶意攻击(也就是0 day攻击),这种攻击的特点是几乎没有签名。
基于行为的方法是基于依赖性来学习行为特征。但是基于行为的方法需要很高的训练成本。为了学习到恶意行为,我们必须要收集足够多的恶意样本,并且在一个可控的环境下观察他们的行为。样本不够多或者是恶意行为的观察不充分都会使得检测结果不好,并且这种恶意攻击还可以通过对抗学习来不断的演化从而规避检测。
这些恶意检测算法都是关注于检测已有的恶意行为,这篇文章的目的是设计一种有效的数据驱动的方法来检测未知的恶意事件。作者首先定义了一个未知的恶意program,这个恶意的program跟现有的正常program是不一样的。给定一个目标的program,作者会做相似性学习,然后看这个program的行为是否和已有的正常program的行为类似。
对于未知的恶意program的检测是很难的,会有如下几个挑战:(1)不同的系统实体之间会有非线性和层级式的关系和依赖,并且这些实体会以一种复杂的行为来work。忽视这些依赖的简单方法最后会导致很高的FP率。(2)缺乏内在的距离/相似性度量。在真实的计算机系统中,已知两个program以及很多相关的系统事件,度量这两个program之间的距离/相似性是很难的。(3)指数级别的事件空间。在每一个主机上,每一秒都会产生超过10000个事件。(4)很多program还会有别名。同一个program在不同的版本或者是更新下会有不同的签名,也会有不同的执行名称。所以,一个简单的对于所有program id/签名的白名单是有问题的。
为了解决这个问题,作者提出了MatchGNet,一个数据驱动的图匹配网络,可以学习program的表示,并且基于图神经网络做相似性的度量。具体来说,作者首先设计了一个变分的图模型来捕捉不同的系统实体对之间的异质依赖。为了从一个结构化的异质变分图中学习program的表示,作者提出了一个层次化的注意力图神经编码器。最后,作者提出了一个使用孪生网络的相似性学习模型来对于参数进行训练,并且计算未知的program和数据库中已有的正常program之间的相似性分数。MatchGNet是基于已有的正常program来训练模型。所以,它可以通过相似性匹配算法来确定那些行为表示和已有的数据库中的正常program不同的program,并且确定这些program是异常的。作者执行了一个实验的扩展集来对于模型的表现做评估。实验结果表明MatchGNet可以很准确的检测恶意的program。具体来说,它对于恶意的program和未知的program分别可以获得97%和96%的平均准确率。作者也将MatchGNet用于检测真实的恶意攻击,实验结果表明这种方法可以在保持FP为0的同时将FP值降低50%左右。
相关工作
在一个网络诱骗邮件攻击中,为了从一个电脑的数据库中偷取敏感数据,可以利用Mircosoft Office的脆弱性,通过向受害者发送一个带有恶意的doc文件的钓鱼邮件。受害者在打开这个doc文件后,就可以部署一个恶意的宏指令。这个恶意的宏指令就可以创建并且执行一个恶意的东西,它会把自己伪装成Java.exe可执行文件。然后这个可执行文件就会打开一个后门,从而可以从目标数据库中读取数据。
基于签名和基于行为的恶意检测方法在我们的案例中都不能很好的检测恶意的program。基于签名的方法不能对未知的恶意program做检测,基于行为的方法需要把所有的恶意样本都放到训练集中去训练。
异质图匹配网络
(1)Overview
本文的MatchGNet中包括三个关键模块:Invariant Graph Modeling(IGM,变分图模型),层次化的注意力图神经编码器(HAGNE),相似性度量学习(SL)。IGM模块可以对于系统的事件数据做建模,将其表示成异质变分图,可以捕捉program的行为profile。然后将这个问题当作是异质图匹配问题。
给定两个图G1和G2,HANGE可以产生相关的两个图嵌入hG(1)h_{G(1)}hG(1)?和hG(2)h_{G(2)}hG(2)?,使用的方法是层次化的注意力方法,然后使用两个图嵌入,计算二者的相似分数。这样的话,在恶意检测阶段,未知的program和已有的正常program之间的距离会被最大化,从而可以学习到一个相似性度量。
(2)不变图模型
在一个企业环境中,从单个的计算机系统中收集到的数据在1个小时的监测后就可以达到十亿字节。对于这类大型数据的表示学习是费时费空间的。最近有人提出来不变图这个概念。这个不变图可以发现实体对之间的重要依赖性。
作者受到这个不变图的启发,对于系统的事件数据建模成异质图,从而可以学习到不同实体之间的相互依赖关系(这些实体包括进程,文件和因特网socket。)实体之间的依赖关系包括一个进程对于文件作处理,一个进程fork出另一个进程,一个进程连接到一个因特网的socket上。给定好几个机器在一天内的事件数据U,每一个目标program都是一个异质图G。作者考虑到了如下三种类型的关系:(1)一个进程fork出另一个进程(P->P)。(2)一个进程处理一个文件(P->F)。(3)一个进程访问到因特网(P->I)。每个图都有一个邻接矩阵A。在 不变图模型中,可以得到一个全局的program依赖的profile。
(3)层次化的注意力图神经编码器
上面得到的结构化的不变图就是一个有着不同类型实体和关系的异质图。因此,很难直接应用传统的对于同质图的方法例如GCN和GraphSage来学习图的表示。为了解决这个问题,作者提出了一个层次化的注意力图神经编码器(HANGE)来学习得到program的图嵌入,这个方法考虑到了node-wise,layer-wise和path-wise的上下文信息。具体来说,作者提出了异质aware的上下文搜索从而找到了邻居的路径相关集。之后作者引入了node-wise的注意力神经聚合,基于随机行走产生的分数随机的对每一个path-relevant的实体进行聚合,从而产生了顶点嵌入。之后,作者设计了一个layer-wise的稠密连接神经聚合器,从而可以对不同layer的顶点嵌入做聚合。最后,作者使用了一个path-wise的注意力神经聚合器来学习不同的元路径的注意力权重,从而计算整个的图嵌入。
(4)异质的上下文搜索
在前面的聚合层,传统的GNN需要对目标节点的所有的one-hop的邻居节点都做搜索。作者的不变图是异质的,仅仅对于这些邻居做聚合是无法得到不同类型节点的语义和结构依赖性的。为了解决这个问题,作者提出了一个基于上下文搜索的元路径。这个元路径是将不同类型的实体连接起来。在一个计算机系统中,一个元路径可以是:一个进程fork出来另一个进程(P->P),两个进程处理相同的文件(P<- F -> P),两个进程打开相同的因特网(P <- I -> P)。这些元路径定义了两个program之间独特的关系。从一个不变图G中,可以得到很多的元路径。对于每一个元路径都可以定义一个path-relevant的邻居集合如下:
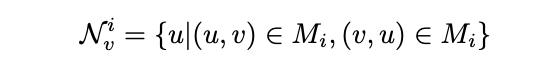
(5) node-wise注意力神经聚合器
在构建了path-relevant的邻居集后,作者可以通过对邻居节点做聚合从而得到这些的上下文信息。但是因为邻居节点也存在很多噪声,不同的邻居节点会对目标节点产生不同的影响。所以,将所有的邻居节点同等对待是不对的。为了解决这个问题,作者提出了一个node-wise的注意力神经聚合器可以对于每个节点都计算一个注意力权重。这个模块是基于random walk随机行走方法,这个可以计算同构图的节点对之间的相似性分数。随机行走就是从一个目标program的节点v开始行走,每次都只会行走到邻居节点NviN_v^iNvi? 集合中。在随机行走结束后,每一个被访问的邻居都会获得visiting count+1的结果。作者对于得到的visiting count做一次L1正则化,并将它作为node-wise的注意力权重。
 其中的k指的是layer的下标,其中的hv(i)(k)h_v^{(i)(k)}hv(i)(k)? 表示的是第k个layer,第i个元路径,第v个program的特征向量。其中的?(k)\epsilon^{(k)}?(k) 是一个可训练参数,可以对于周围的节点的特征向量和当前节点上一层的特征向量之间做一个trade off。在得到聚合表示(也就是上面的AGG)之后,后面再加一个MLP可以将聚合表示转换到隐藏非线性空间中。通过node-wise的注意力神经聚合器,作者将对上下文信息收敛出来,可以考虑到不同邻居的重要性。
其中的k指的是layer的下标,其中的hv(i)(k)h_v^{(i)(k)}hv(i)(k)? 表示的是第k个layer,第i个元路径,第v个program的特征向量。其中的?(k)\epsilon^{(k)}?(k) 是一个可训练参数,可以对于周围的节点的特征向量和当前节点上一层的特征向量之间做一个trade off。在得到聚合表示(也就是上面的AGG)之后,后面再加一个MLP可以将聚合表示转换到隐藏非线性空间中。通过node-wise的注意力神经聚合器,作者将对上下文信息收敛出来,可以考虑到不同邻居的重要性。
(6)layer-wise全连接神经聚合器
使用GNN模型会遇到一个问题,那就是,这个GNN模型可能到后面不会再提高了,因为添加很多层后,很容易把噪声信息反向传播回去。在残差网络出现后,有人提出了skip-connection跳跃连接。但是,就算是有跳跃连接,在很多图数据上,有更多层的GCN网络的表现还是比2层的GCN网络差。为了解决已有工作的局限性,作者提出了layer-wise的全连接聚合器,它是受DenseNet的启发而提出来的。更具体来说,这里的layer-wise聚合器,每一个聚合器都可以捕捉到子图结构。所有的表示都可以在MLP中以连接的方式做聚合。这样的话,最后得到的嵌入就可以选择不同的子图结构。layer-wise的全连接神经聚合器如下所示(感觉就是把当前层的前面所有层的特征向量都聚合到当前层中,所以确实是受到DenseNet的启发):
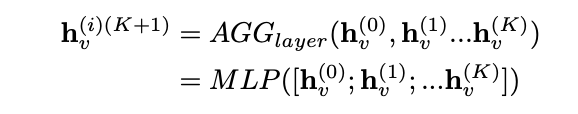
(7)path-wise注意力神经聚合器
在node-wise和layer-wise的聚合之后,产生了对于不同的元路径的嵌入。但是,不同的元路径也不应该被同等对待。例如,勒索软件通常在处理文件的时候会很活跃,但是在一个进程fork出来另一个进程或者是一个进程打开因特网的时候是不容易发生的,VPNFilter则通常是在访问因特网的时候会比较活跃,但是在其他两个元路径下就不容易发生。因此,需要对于不同的元路径不同的对待。为了解决这个问题,作者提出了path-wise的注意力神经聚合器来对于不同的path相关的邻居集做聚合。这里的path-wise聚合器可以自动学习对于不同元路径的注意力权重。在给定一个program的嵌入hv(i)(K+1)h_v^{(i)(K+1)}hv(i)(K+1)? ,可以定义如下的path-wise注意力权重:
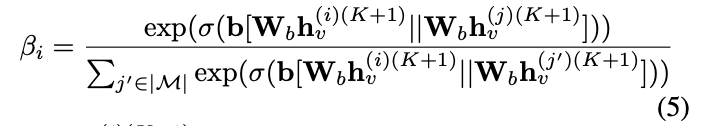 其中的||指的是连接操作。
其中的||指的是连接操作。
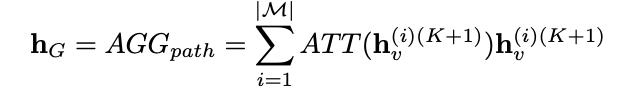 上式就是对所有的元路径做求和操作,但是对于不同的元路径有不同的权重。
上式就是对所有的元路径做求和操作,但是对于不同的元路径有不同的权重。
(8)相似性度量
为了更好的完成图匹配的过程,作者提出了相似性学习(SL),一个基于学习模型的孪生网络,它可以用于对层次化的注意力图神经编码器(HANGE)的参数进行训练。孪生网络是一个包含两个或者是更多相同子网络组件的神经网络,可以用于很好的区分相似或者是不相似的物体。这里,作者使用SL来学习相似准则,同时学习program的图表示从而更好的实现未知的program和已知正常program之间的图匹配。
更加具体来说,作者使用的孪生网络中有两个相同的HANGE可以分别独立计算各自program的图表示。每个HANGE都可以将对于program的图作为输入,然后输出相应的图嵌入hGh_GhG?。然后使用一个神经网络来融合两个图嵌入。最后的输出是两个program嵌入的相似度分数。在设置标签的时候,是这样的,如果两个图是属于相同的program,那么ground truth的标签就是1,否则这个标签就是-1.对于每一对的program,都会计算一个余弦分数从而衡量两个program嵌入的相似度,并且输出SL的结果如下:
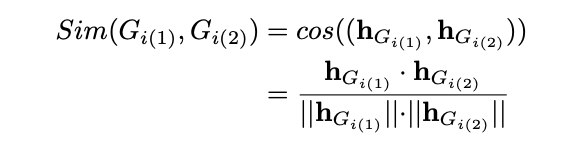 最后的目标函数就是如下形式:
最后的目标函数就是如下形式:
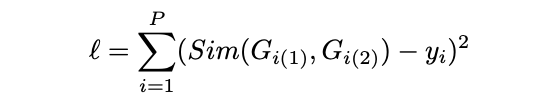 因为作者是直接优化两个program之间的距离,所以这个模型可以用于检测未知的恶意软件。给定一个未知的program,作者首先构建它的不变图,然后将这个不变图输入到HANGE中来获得program的嵌入。之后,作者会计算两个program的嵌入图之间的余弦距离。如果对于某一个program,产生了一个以上的图嵌入,作者只会取跟未知的program之间的相似度分数最大的那个。最后可以保存前k个分数最大的program作为最后的结果。
因为作者是直接优化两个program之间的距离,所以这个模型可以用于检测未知的恶意软件。给定一个未知的program,作者首先构建它的不变图,然后将这个不变图输入到HANGE中来获得program的嵌入。之后,作者会计算两个program的嵌入图之间的余弦距离。如果对于某一个program,产生了一个以上的图嵌入,作者只会取跟未知的program之间的相似度分数最大的那个。最后可以保存前k个分数最大的program作为最后的结果。
实验
(1)实验步骤
1)数据:作者从一个由109个主机组成的真实企业网络中收集了为期20周的数据(其中有87个windows主机和22个linux主机),其中整个数据集的大小接近3万亿字节。统计了上面说到的三个事件,发现也有3亿的事件,其中有2000个进程,600000个文件和18000个因特网socket。作者基于系统事件数据为每一天的每一个program构建了一个不变图。
2)Baseline:作者将自己提出的MatchGNet和以下的几个SOA算法做对比:LR,SVM,MLP,GCN和GraphSage。
3)评估指标:准确率,F1-score和AUC分数
(2)恶意program检测
作者将恶意program定义为使用了另外一个program的id的program,这个是攻击者常用的隐藏他们攻击的方法。为了产生恶意program的数据集做测试,作者手动的随机产生了1000个恶意的program。并且作者将这些program的id替换成其他已知program的id,从而可以达到隐藏攻击的目的。所以,相当于是,每一个恶意的program都有一个已知的program的id作为自己的伪造id。
超参数的选择:在MatchGNet中有两个超参数,一个是layer层的数目,一个是隐藏神经元的数目。参数的调节过程及结果如下所示:

整个的对于这几个算法模型的结果如下所示:
(3)未知的program的检测
整个的对于这几个算法模型的结果如下所示:

(4)对于恶意攻击的检测
作者用MatchGNet来检测企业环境中真实的恶意攻击。作者从VirusTotal中随机的下载了145个恶意软件,其中包含9个真实的攻击case包括WannaCry蠕虫病毒,Genasom,Sorikrypt,Shinolocker,钓鱼邮件,ShellShock,Netcat Backdoor,Passing the Hash和Trojan Attack。作者将这些攻击应用在他们的两台测试机器上,得到数据。为了评估MatchGNet的有效性,作者将一个SOTA的实体-嵌入作为一个baseline。
Conclusion
作者在这篇文章中提出了MatchGNet,一个可以用来未知恶意program的图匹配网络。MatchGNet第一次将program的执行行为看作是一个异质不变图。基于这个program的图,它学习到了图的表示以及相似度度量方法,可以区分正常的program和恶意的program。
补充
MatchGNet是在已有的正常程序上学习和训练模型,并没有在任何的异常程序上训练