glob.glob(pathname) 返回所有匹配的文件路径列表。它只有一个参数 pathname,定义了文件路径匹配规则,这里可以是绝对路径,也可以是相对路径。
如当前路径下有文件如下:
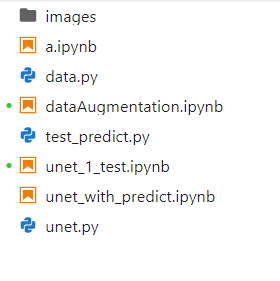
* 返回当前路径下的所有文件路径
files = glob.glob('*')
files
'''['a.ipynb','data.py','dataAugmentation.ipynb','images','test_predict.py','unet.py','unet_1_test.ipynb','unet_with_predict.ipynb'] '''files = glob.glob('*.py')
''' ['data.py', 'test_predict.py', 'unet.py'] '''若想在上级目录中搜索文件,可使用 ../
f = glob.glob('../*') # 当前路径为 /images/
''' ['..\\a.ipynb','..\\data.py','..\\dataAugmentation.ipynb','..\\images','..\\test_predict.py','..\\unet.py','..\\unet_1_test.ipynb','..\\unet_with_predict.ipynb'] '''
另外,在使用 glob.glob 时遇到了一个问题:这个函数返回的路径好像会自己加上一个 \ 反斜杠,因此与文件路径有冲突,导致无法正确读取文件(一般文件路径为 /path/xxx/...)
比如想读取图片时:
path = "images/merge"
img_type = 'tif'
train_imgs = glob.glob(path+"/*."+ img_type)
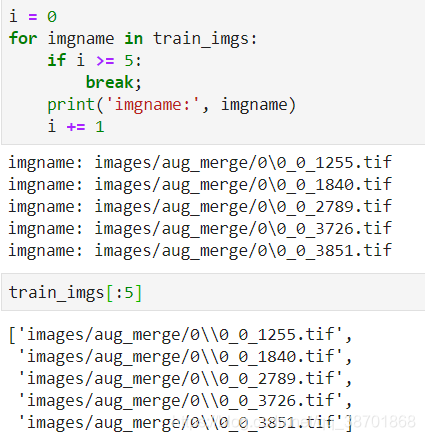
然后这两种方式打印出的反斜杠数量还不一样…
对于第一种遍历方式取文件路径来读取图片,我是这样处理反斜杠的:
for imgname in train_imgs:#print('0000:',imgname) --> 0000: images/aug_merge/0\0_0_1255.tifimgname = eval(repr(imgname).replace('\\', '/'))#print('1111:',imgname) --> 1111: images/aug_merge/0//0_0_1255.tifimgname = imgname.replace('//','/')#print('2222:',imgname) --> 2222: images/aug_merge/0/0_0_1255.tifimg = cv2.imread(imgname) # 然后就能正常的读取图片了
对于 glob.glob 的一些实现细节我也没去关注,可能这是一种很笨的处理方式吧,总之能暂时满足我的需求。