Guava Cache简介
优点
- Guava Cache很好的封装了get、put操作。如:get数据时,获取缓存-如果没有-查询DB(get-if-absent-compute),再把查询结果放入缓存中
- Guava Cache是线程安全的缓存,内部实现与ConcurrentMap相似,但增加了更多的元素失效策略。
- Guava Cache提供了三种基本的缓存回收方式:基于容量回收、定时回收和基于引用回收。定时回收有两种:按照写入时间,最早写入的最先回收;按照访问时间,最早访问的最早回收。
- Guava Cache提供了缓存加载命中情况的统计功能。
适用场景
缓存在很多场景下都是相当有用的。例如,计算或检索一个值的代价很高,并且对同样的输入需要不止一次获取值的时候,就应当考虑使用缓存。
相对于频繁的IO操作,使用缓存效率更高速度更快;相对于Redis等分布式缓存,Guava Cache等本地缓存减少了网络传输的消耗。
高效存储&访问黄金搭档 = Guava Cache + Redis + DB
Guava Cache适用于以下场景:
- 你愿意消耗一些内存空间来提升速度。
- 你预料到某些键会被查询一次以上。
- 缓存中存放的数据总量不会超出内存容量。
基本用法
- CacheLoader 提供合理的默认方法来加载或计算与键关联的值,从LoadingCache查询的正规方式是使用get(K)方法。这个方法要么返回已经缓存的值,要么使用CacheLoader向缓存原子地加载新值。
LoadingCache<String, Integer> cache = CacheBuilder.newBuilder().maximumSize(10) // 最多存放10个数据.expireAfterWrite(10, TimeUnit.SECONDS) // 缓存10秒,从上一次数据更新开始计算.expireAfterAccess(10, TimeUnit.SECONDS) // 缓存10秒,从上一次数据访问(读、写、更新)开始计算.recordStats() // 开启数据统计功能.build(new CacheLoader<String, Integer>() {// 数据加载,默认返回0,此处可自定义处理逻辑(如:查询DB)@Overridepublic Integer load(String key) throws Exception {return 0;}});@Test
public void test() throws ExecutionException {Integer value = cache.get("key");System.out.println(value);
}
- Callable 所有类型的Guava Cache,不管有没有自动加载功能,都支持get(K, Callable)方法。这个方法返回缓存中相应的值,或者用给定的Callable运算并把结果加入到缓存中。
Cache<String, Integer> cache2 = CacheBuilder.newBuilder().maximumSize(10).build();
cache2.get("test", new Callable<Integer>() {@Overridepublic Integer call() throws Exception {// 这里可以做一些复杂的操作,或者针对不同key进行不同的操作return 0;}
});
- Cache.put使用cache.put(key, value)方法可以直接向缓存中插入值,这会直接覆盖掉给定键之前映射的值。
缓存回收
基于容量的回收
- 如果要规定缓存项的数目不超过固定值,只需使用CacheBuilder.maximumSize(long)。缓存将尝试回收最近没有使用或总体上很少使用的缓存项
注:采用LRU算法回收缓存
定时回收
- expireAfterAccess(long, TimeUnit):缓存项在给定时间内没有被读/写访问,则回收。请注意这种缓存的回收顺序和基于大小回收一样。
- expireAfterWrite(long, TimeUnit):缓存项在给定时间内没有被写访问(创建或覆盖),则回收。如果认为缓存数据总是在固定时候后变得陈旧不可用,这种回收方式是可取的。
注:使用CacheBuilder构建的缓存不会"自动"执行清理和回收工作,也不会在某个缓存项过期后马上清理,也没有诸如此类的清理机制。相反,它会在写操作时顺带做少量的维护工作,或者偶尔在读操作时做(如果写操作实在太少)
基于引用的回收
- CacheBuilder.weakKeys():使用弱引用存储键。当键没有其它(强或软)引用时,缓存项可以被垃圾回收。
- CacheBuilder.weakValues():使用弱引用存储值。当值没有其它(强或软)引用时,缓存项可以被垃圾回收。
- CacheBuilder.softValues():使用软引用存储值。软引用只有在响应内存需要时,才按照全局最近最少使用的顺序回收。
显示清除
- 个别清除:Cache.invalidate(key)
- 批量清除:Cache.invalidateAll(keys)
- 清除所有缓存项:Cache.invalidateAll()
数据结构
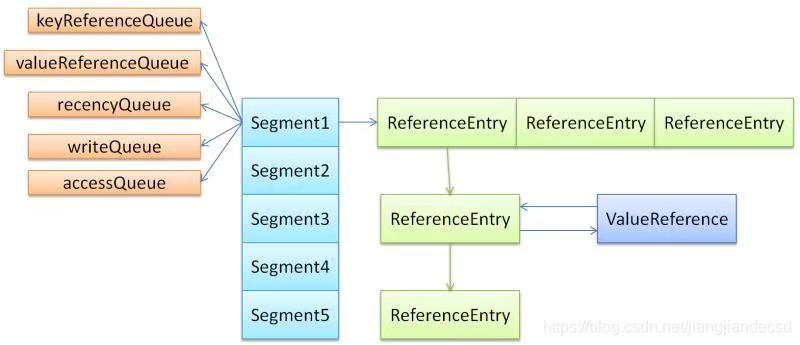
缓存回收策略实现
GuavaCache会维护两个队列,一个writeQueue、一个accessQueue,用这两个队列来实现最近读和最近写的清除操作。AccessQueue的实现如下:
static final class AccessQueue<K, V> extends AbstractQueue<ReferenceEntry<K, V>> {// implements Queue@Overridepublic boolean offer(ReferenceEntry<K, V> entry) {// unlink// 将entry和它的前节点后节点的关联断开connectAccessOrder(entry.getPreviousInAccessQueue(), entry.getNextInAccessQueue());// add to tail// 将新增节点加入到队列的尾部connectAccessOrder(head.getPreviousInAccessQueue(), entry);// entry的后节点设置为headconnectAccessOrder(entry, head);return true;}@Overridepublic ReferenceEntry<K, V> peek() {ReferenceEntry<K, V> next = head.getNextInAccessQueue();return (next == head) ? null : next;}@Overridepublic ReferenceEntry<K, V> poll() {ReferenceEntry<K, V> next = head.getNextInAccessQueue();if (next == head) {return null;}remove(next);return next;}@Override@SuppressWarnings("unchecked")public boolean remove(Object o) {ReferenceEntry<K, V> e = (ReferenceEntry) o;ReferenceEntry<K, V> previous = e.getPreviousInAccessQueue();ReferenceEntry<K, V> next = e.getNextInAccessQueue();connectAccessOrder(previous, next);nullifyAccessOrder(e);return next != NullEntry.INSTANCE;}}AccessQueue重写了队列的offer 、 poll 、 peek等操作。重点关注offer()实现:
- 将entry和它的前节点后节点的关联断开,并且建立前节点与后节点直接的关联。
- 将新增entry节点加入到队列的尾部。head节点的前一个节点即尾节点。
- 建立尾节点与entry节点的关系,entry的后节点设置为head
如上代码中的offer操作,可以发现,AccessQueue是一个环形队列,最近更新的节点一定是在尾部的,head后面的节点一定是最不活跃的,在每一次回收数据时首先清除head后面的节点数据。
缓存设置了最大数量清除策略CacheBuilder.maximumSize(long),会触发如下代码:
根据权重计算数量,权重可自定义实现,默认1个缓存项的权重是1,当权重超过设置的最大值则进行缓存清除。。
@GuardedBy("this")void evictEntries(ReferenceEntry<K, V> newest) {if (!map.evictsBySize()) {return;}drainRecencyQueue();// If the newest entry by itself is too heavy for the segment, don't bother evicting// anything else, just thatif (newest.getValueReference().getWeight() > maxSegmentWeight) {if (!removeEntry(newest, newest.getHash(), RemovalCause.SIZE)) {throw new AssertionError();}}while (totalWeight > maxSegmentWeight) {ReferenceEntry<K, V> e = getNextEvictable();if (!removeEntry(e, e.getHash(), RemovalCause.SIZE)) {throw new AssertionError();}}}// 从accessQueue获取下一个应该被清理的对象@GuardedBy("this")ReferenceEntry<K, V> getNextEvictable() {for (ReferenceEntry<K, V> e : accessQueue) {int weight = e.getValueReference().getWeight();if (weight > 0) {return e;}}throw new AssertionError();}
每次写操作之前都会触发preWriteCleanup清理操作,如下:
@GuardedBy("this")// 写操作之前执行清理操作void preWriteCleanup(long now) {runLockedCleanup(now);}// 清理之前,先进行锁定void runLockedCleanup(long now) {if (tryLock()) {try {// 清理弱引用已经被回收的key value数据drainReferenceQueues();// 清理已经过期的数据expireEntries(now); // calls drainRecencyQueuereadCount.set(0);} finally {unlock();}}}/*** Drain the key and value reference queues, cleaning up internal entries containing garbage* collected keys or values.*/@GuardedBy("this")void drainReferenceQueues() {if (map.usesKeyReferences()) {// 清理弱引用keydrainKeyReferenceQueue();}if (map.usesValueReferences()) {// 清理弱引用valuedrainValueReferenceQueue();}}@GuardedBy("this")void drainKeyReferenceQueue() {Reference<? extends K> ref;int i = 0;while ((ref = keyReferenceQueue.poll()) != null) {@SuppressWarnings("unchecked")ReferenceEntry<K, V> entry = (ReferenceEntry<K, V>) ref;map.reclaimKey(entry);if (++i == DRAIN_MAX) {break;}}}@GuardedBy("this")void drainValueReferenceQueue() {Reference<? extends V> ref;int i = 0;while ((ref = valueReferenceQueue.poll()) != null) {@SuppressWarnings("unchecked")ValueReference<K, V> valueReference = (ValueReference<K, V>) ref;map.reclaimValue(valueReference);if (++i == DRAIN_MAX) {break;}}}
定时回收策略,首先读写操作时都会把对应的entry加入到accessQueue 、 writeQueue两个队列。
if (map.recordsAccess()) {entry.setAccessTime(now);}if (map.recordsWrite()) {entry.setWriteTime(now);}accessQueue.add(entry);writeQueue.add(entry);
过期操作时遍历accessQueue 、 writeQueue两个队列,判断已经过期则执行removeEntry操作
@GuardedBy("this")void expireEntries(long now) {drainRecencyQueue();ReferenceEntry<K, V> e;while ((e = writeQueue.peek()) != null && map.isExpired(e, now)) {if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {throw new AssertionError();}}while ((e = accessQueue.peek()) != null && map.isExpired(e, now)) {if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {throw new AssertionError();}}}
根据设置的expireAfterAccess() expireAfterWrite()来判断是否过期
/*** Returns true if the entry has expired.*/boolean isExpired(ReferenceEntry<K, V> entry, long now) {checkNotNull(entry);if (expiresAfterAccess()&& (now - entry.getAccessTime() >= expireAfterAccessNanos)) {return true;}if (expiresAfterWrite()&& (now - entry.getWriteTime() >= expireAfterWriteNanos)) {return true;}return false;}
所有缓存过期的清理策略正常是在写操作之前进行的,但是防止很久时间没有写操作,偶尔在读的时候执行清理策略,如下读的finally执行postReadCleanup()
V get(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {checkNotNull(key);checkNotNull(loader);try {if (count != 0) { // read-volatile// don't call getLiveEntry, which would ignore loading valuesReferenceEntry<K, V> e = getEntry(key, hash);if (e != null) {long now = map.ticker.read();// 获取有效的没有过期的值V value = getLiveValue(e, now);if (value != null) {recordRead(e, now);statsCounter.recordHits(1);// refresh的逻辑return scheduleRefresh(e, key, hash, value, now, loader);}ValueReference<K, V> valueReference = e.getValueReference();if (valueReference.isLoading()) {// 已经有一个线程在load,同步等待返回的新值return waitForLoadingValue(e, key, valueReference);}}}// at this point e is either null or expired;return lockedGetOrLoad(key, hash, loader);} catch (ExecutionException ee) {Throwable cause = ee.getCause();if (cause instanceof Error) {throw new ExecutionError((Error) cause);} else if (cause instanceof RuntimeException) {throw new UncheckedExecutionException(cause);}throw ee;} finally {postReadCleanup();}}/*** Performs routine cleanup following a read. Normally cleanup happens during writes. If cleanup* is not observed after a sufficient number of reads, try cleaning up from the read thread.*/void postReadCleanup() {// DRAIN_THRESHOD = 0x3f 也就是应该读192次触发一次清理,单个segment中if ((readCount.incrementAndGet() & DRAIN_THRESHOLD) == 0) {cleanUp();}}
注意上面的scheduleRefresh()方法,这个方法的实现决定了expireAfterWrite和refreshAfterWrite两种过期策略的区别。
两个策略都能保证在本地缓存过期时,只有一个线程去穿透缓存加载后端资源。区别是在加载资源时expireAfterWrite会让所有的线程阻塞等待新值返回,然后返回加载好的新值;而refreshAfterWrite在一个线程去拿新值的同时,其他线程先直接返回旧值,不阻塞。
V scheduleRefresh(ReferenceEntry<K, V> entry, K key, int hash, V oldValue, long now,CacheLoader<? super K, V> loader) {if (map.refreshes() && (now - entry.getWriteTime() > map.refreshNanos)&& !entry.getValueReference().isLoading()) {// 如果没有线程在load则去加载,如果已经在load则返回旧值V newValue = refresh(key, hash, loader, true);if (newValue != null) {return newValue;}}return oldValue;}