
Matching the Blanks: Relation Learning
Matching the Blanks: Distributional Similarity for Relation Learning
Abstract
���Զ������ϵ���н�ģ��ͨ�ù�ϵ��ȡ������Ϣ��ȡ�ĺ��ļ����������Ѿ����Խ���ͨ�õij�ȡ����ȡ���ֱ�����ʽ����Ϣ����ʾ��ϵ�����߽����ֱ�����ʽ������֪ʶͼ�Ĺ�ϵ����Ƕ�롣Ȼ���������ַ����ĸ��������������ġ����Ļ��ڹ�ϵ��Harris�ֲ����������չ���Լ���������ѧϰ�ı���ʾ���ر���BERT��������о���չ����ʵ�������ı��й����������صĹ�ϵ��ʾ�����DZ�������ʹ��ʹ���κ������ѵ�����ݣ���Щ��ʾҲ����������ǰ�ڻ��������Ĺ�ϵ��ȡ��FewRel������Ĺ��������ǻ���ʾ�ˣ�ʹ�����ǵ��������صı�ʾ��ʼ��ģ�ͣ�Ȼ�����мල��ϵ��ȡ���ݼ��Ͻ���������SemEval 2010 Task 8, KBP37, �� TACRED������������ǰ�ķ�����
Introduction
��ϵ��ȡ����Ҫ��Ϊ���ַ�����

����idea������˴��ı���ѧϰ��ϵ��ʾ�ģ�һ�ֲ���Ҫ�κ�֪ʶͼ������ע�ͼල�Ĺ�ϵ��ʾ�ķ�����Matching the Blanks��
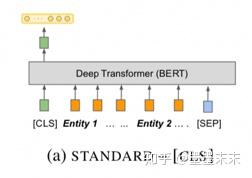
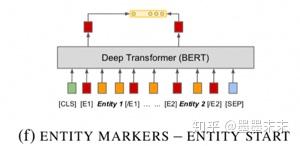
1�������ܹ�����һ���ı����Ͽ⣬����ʵ�������ӵ�Ψһ��ʶ�����������ǽ���ϵ��䶨��Ϊ�����������ʵ����ı��顣�ɴˣ����Ǵ���������ϵ����ѵ�����ݣ����е�ʵ�����滻Ϊ�����[BLANK]���ţ���ͼ1��ʾ��


2��ѵ�����̲��ð�����ϵ���ģ�blank-�������ԣ�����Ŀ���ǣ�������Ƿֲ�����ͬ��ʵ����ϣ����ϵ�ı����ʾ�������Ƶġ�
3������ѵ����ѧϰ���Ĺ�ϵ��ʾӦ�������������FewRel����Han et al., 2018���ϣ��ڸ������У��ض���ϵ���硰original language of work������һЩʾ������ʾ���硰The Crowd (Italian: La Folla) is a 1951 Italian film.�� Han et al. (2018)��FewRel��Ϊ������ݼ���ּ������ģ���ڲ���ʱ��Ӧ�����ϵ��������
Overview
Task definition
������Ҫ�о��ӹ�ϵ��䵽��ϵ��ʾ��ӳ��ѧϰ��
x = [x0 . . . xn]��ʾ�������У����У�x0 = [CLS]��xn = [SEP] ����Ŀ�ʼ�ͽ�����ǡ�
s1 = (i, j)��s2 = (k, l) ��һ��������0 < i < j ? 1, j < k, k �� l ? 1, l �� n.
r = (x, s1, s2)��ϵ�����һ����Ԫ������ʾ������s1��s2�������ʵ�壬[xi . . . xj?1]��ʾ��һ��ʵ��[xk . . . xl?1]��ʾ�ڶ���ʵ�塣
Ŀ����ѧϰһ������hr = f��(r)������ϵ���ӳ�䵽һ���̶����ȵ�����hr��Rd����������ʾ��s1��s2��ǵ�ʵ��֮����x��ʾ�Ĺ�ϵ��
Contributions
1�������о��˹�ϵ������f�ȵIJ�ͬ�ܹ�����Щ�ܹ��������ڹ㷺ʹ�õ�transformer����ģ��֮�ϣ�Devlin���ˣ�2018��Vaswani���ˣ�2017�������ǻὫ����Ӧ����һϵ�еĹ�ϵ��ȡ���ݼ��ϣ������мලѵ����������
2��֤���˺���f�ȿ��Դӹ㷺ʹ�õ�Զ�̼������ʵ�������ı�����ʽѧϰ�õ���
Architectures for Relation Learning
Relation Classification and Extraction Tasks
��ϵ��ȡ������Ҫ��Ϊ���ࣺ��ֵ��мල��ϵ��ȡ��few-shot��ϵ��ȡ��
�мල��ϵ��ȡ������һ����ϵ������r��Ԥ���ϵ������t �� T��T�ǹ̶��Ĺ�ϵ�����ֵ䣬t=0��ʾ��ϵ����е�ʵ��֮��ȱ����ϵ��������������һ�����SemEval 2010 Task 8��KBP-37��TACRED���ݼ��Ͻ���������
few-shot��ϵ��ȡ�����ݲ�ѯ��ϵ����һ���ѡ��ϵ�����������ƥ�䡣�ڴ������У����ԺͿ������е�����ͨ����ѵ������û�г��ֹ��Ĺ�ϵ���͡�������������һ�����FewRel���ݼ��Ͻ��������������˵������K����N���б�ǵĹ�ϵ��䣬Sk = {(r0, t0) . . . (rN , tN )}��ti �� {1 . . . K } ������Ӧ�Ĺ�ϵ���ͣ�Ŀ����Ԥ���ѯ��ϵ���rq��tq��{1��K}��
Relation Representations from Deep Transformers Model
�ڱ��ڵ�����ʵ���У���ʹ��Devlin�����ṩ��BERTLARGEģ����Ϊ��ʼ����2018�꣩������ض��������ʧ����ѵ��������BERT��ǰû��Ӧ���ڹ�ϵ��ʾ���⣬������Ҫ���������Ҫ�Ľ�ģ���⣺
1����α�ʾ��ʵ����б�ʾ��ΪBERT�����롣
2��������δ�BERT���������ȡ���̶����ȵĹ�ϵ��ʾ��
Entity span identification
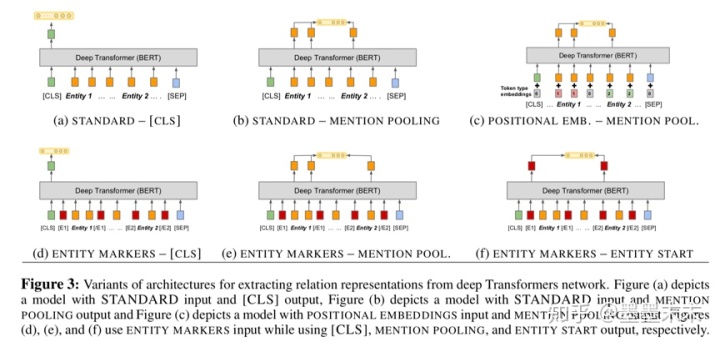
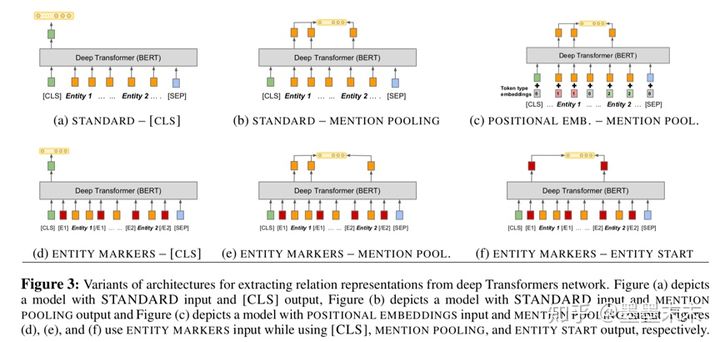
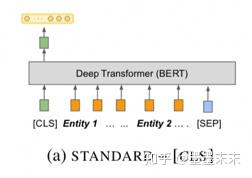
��������BERT encoder����ķ�����
Standard input :ֱ�ӷ���x��û�����������ʵ�������ʾ��ע����Ϊ��������BERT������ʶ��x�е�ʵ�壬���Ƕ��ڱ����루Standard input������x�����������ϵ�ʵ������ʱ����֪���ĸ�ʵ�崦�ڽ��㡣
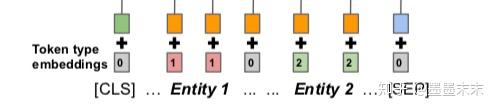
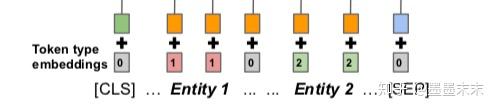
Positional embeddings��bert�ж���ÿ������Ĵ��ﶼ������һ��segment embedding�ķֶα�ǣ�Ϊ�˶�ʵ�������ʾ��ǣ���segment embedding�������ֱ�����ֱ��ǵ�һ��ʵ��͵ڶ���ʵ�塣
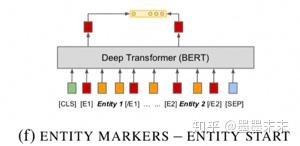
Entity marker tokens�����ĸ����[E1start], [E1end], [E2start] and [E2end] ������x���Ա�ǹ�ϵ������ᵽ��ÿ��ʵ��Ŀ�ʼ�ͽ���������x ? =[x0 . . . [E1start] xi . . . xj?1 [E1end] ...[E2start] xk ...xl?1 [E2end]...xn]. ~s1 = (i + 1,j+1) ?~s2 =(k+3,l+3)


Fixed length relation representation
�������ִ�BERT encoder����ȡ�̶����ȹ�ϵ��ʾhr�ķ��������������������ڳ�ȡtransformer��������һ�����ز�H = [h0, ...hn]������n=|x|��
[CLS] token������[CLS]���h0��Ϊ��һ�ֹ�ϵ��ʾ��
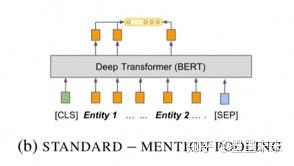
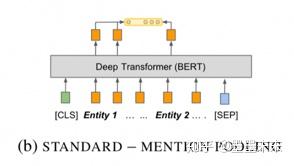
Entity mention pooling����������ʵ���Ӧ������he1 = MAXPOOL([hi...hj?1])��he2 = MAXPOOL([hk...hl?1]) ����ƴ�ӵõ�hr = ?he1|he2 ? ����Ϊ��ϵ��ʾ��
Entity start state����ʹ��ENTITY MARKERS �ķ�ʽ��Ϊ���������£���������ʵ��Ŀ�ʼ�������Ӧ�����ز��������ƴ��rh = ?hi|hj+2?.��Ϊ��ϵ�ı�ʾ��
���˶���ģ�����������ܹ�֮�⣬���ǻ�����������ѵ��ģ�͵���ʧ����figure2��ʾ����
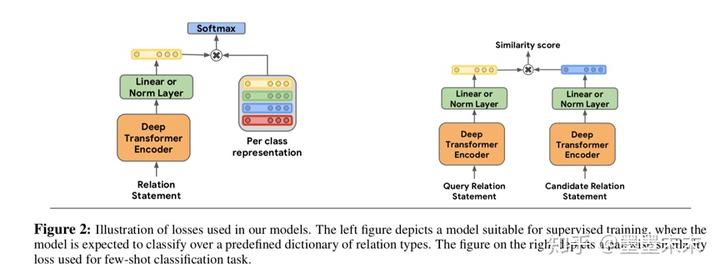
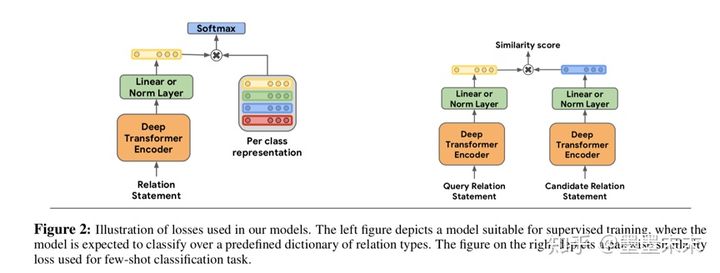
�����мල������һ���µķ���㣬W �� RKxH ������H�ǹ�ϵ��ʾ�Ĵ�С��K�ǹ�ϵ���͵���������ʧΪsoftmax��hrWT��������������ϵ���Ľ�������ʧ��
����few-shot��������ʹ�ò�ѯ���Ĺ�ϵ��ʾ��ÿ����ѡ���֮��ĵ����Ϊ���ƶȵ÷֣�����softmax�����ƶȵ÷֣�������������ϵ���Ľ�������ʧ��Ϊѵ����ʧ��
����ʹ������һ�鳬������BERTģ�Ͷ��ض��������������


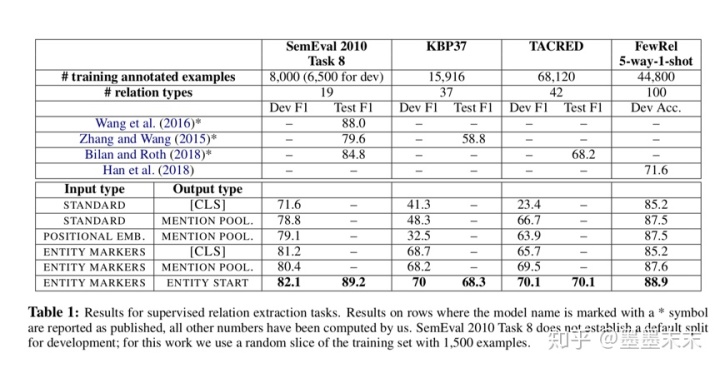
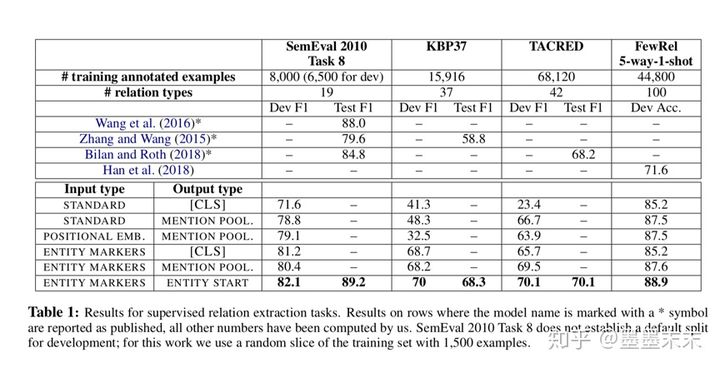
Table 1��ʾ�������мල��ϵ��ȡ�����ģ�ͱ�����few-shot��ϵ���������5-way-1-shot�����Ľ�������������ĸ�������ʾʹ��ENTITY MARKERS�����ʾ��ENTITY START�����ʾ��ģ�ͻ������õķ�����˵������ʵ���λ����Ϣ�Ƿdz��б�Ҫ�ģ�����������position embedding�л���Ĺ�����ͬ(Zhang et al., 2017; Bilan and Roth, 2018)��deep Transformers�ӿ����µ�ʵ��߽�ʣ�ENTITY MARKERS���л������
Learning by Matching the Blanks
����һ���µ�ѵ����ϵ��������f�ȵķ�������ʹ���б�ǩ��ѵ�����ݣ�����ʹ�������뷨����������κ�һ�Թ�ϵ���r��r�䣬���r��r����������ϵ��������������ƣ���ô�ڻ�f�ȣ�r��?f�ȣ�r�䣩Ӧ���ǽϴ�ģ����������ϵ״̬��ʾ�����ϲ�ͬ�Ĺ�ϵ����ô����ڻ�Ӧ���ǽ�С�ġ�
���Ƿ���web�ı��д��ڸ߶ȵ����࣬����һ��ʵ��֮���ÿһ����ϵ�����ܶ�γ��֡����s1��s��1ָͬһ��ʵ�壬s2��s��2ָͬһ��ʵ�壬��r=��x��s1��s2�����п��ܱ�����r��=��x�䣬s��1��s��2����ͬ�������ϵ��������۲����������������һ�ִ�ʵ�������ı���ѧϰf�ȵ��·�������Matching the Blanks��MTB����
Learning Setup
D = [(r0,e01,e02)...(rN,eN1 ,eN2 )] ��һ�����������ʵ��Ĺ�ϵ������Ͽ⡣
����һ����������
p(l = 1|r,r��) =1/(1+expf��(r)?f��(r��) )
��r��r���ʾ��ͬ��ϵ��l=1��������ͬ��ϵ��l=0�����������һ�����ʣ�Ȼ�����ǽ�ѧϰf�ȵIJ�����ʹ��ʧ��С��
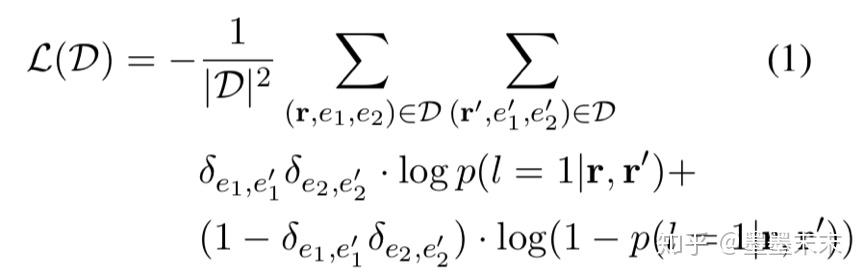
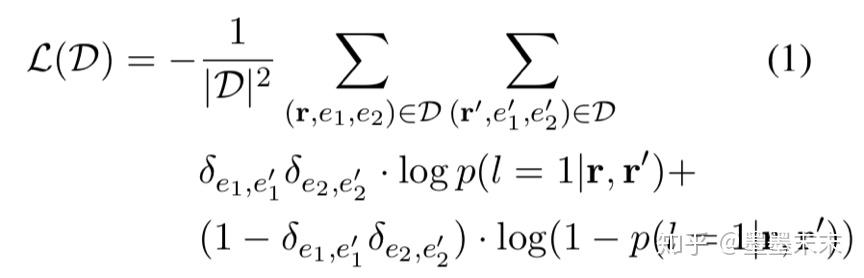
���У���e,e�� ��Kronecker delta����e = e�� ʱֵΪ1������Ϊ0��
Introducing Blanks
�����������ϵͳû���κι�ϵ�ĸ����˼���f���ܹ�����������Ĺ�ϵ��ʾ�Dz������ģ�Ϊ�˱��������ѧϰʵ������ϵͳ������������һ�������ĵ����Ͽ�
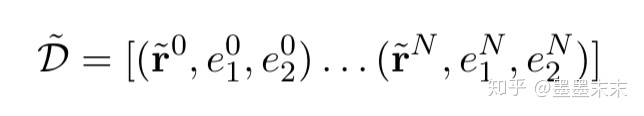
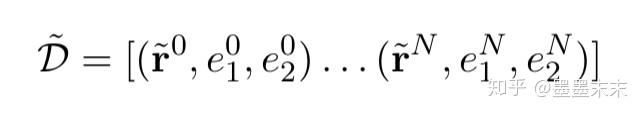
?ri = (x ?i, si1, si2) ����һ����ϵ��䣬����һ��������ʵ���ᵽ�ѱ������[BLANK]�����滻��������˵��~x?������s1��s2����ľ��и��ʦ���ʵ�塣����ʵ���ѱ�����[BLANK]]�����滻��ֻ�Ц�2�Ĺ�ϵ����в����ϵ������ʵ������ʽ�ġ�����ʹ����С��L��~D����f����Ҫ���IJ������Ǽ�ʶ��r�е�����ʵ�塣
Matching the Blanks Training
ѵ�����ϲ���Ӣ��ά���ٿƣ�ʹ���ֳɵ�ʵ������ϵͳ��Google Cloud Natural Language API����Ψһ��֪ʶ���ʶ�������磬Freebase ID��Wikipedia URL��ע���ı��е�ʵ�塣Ϊ�˼�С�漰����ʵ��Ĺ�ϵ���Ľϴ�ƫ����Ƕ�ÿ������ʵ�嶼������������ķ�ʽ������������ʵ��Ĺ�ϵ����������
ʹ��ѵ��������ʹL(D ?)��С������ʵ�ϣ�������ʹ����������ϵ��䶼���бȽϣ���������ʹ�������Աȹ���(Gutmann and Hyva ?rinen, 2012; Mnih and Kavukcuoglu, 2013)����Ϊ���е�������������ͬ��ʵ�壬���Equation 1�е�һ��Ĺ���û�б仯�����Ц�e1��e��1��e2��e��2=1������ֵ�ı��˵ڶ���Ĺ��ס������й�ϵ�����о���������������ߴ�ֻ����һ��ʵ��Ĺ�ϵ����г���������Ϊ��������ͬʱ������һ����hard�����ݼ��������ǹ�ϵ�������ƣ�����ʵ������һ�ֹ�ϵ�����������С���������Ϊ�������IJ���ȷ�ȡ�
���ѡ���=0.7�ĸ�������ʵ���滻[blank], ȷ��ģ�Ͳ���������������ȱ��[blank]���Ŷ�������һ��������6�ڹ�ϵ���ԣ����а���50%����������50%�ĸ�������
Experimental Evaluation
BERTEM +MTB ����


Few-shot Relation Matching
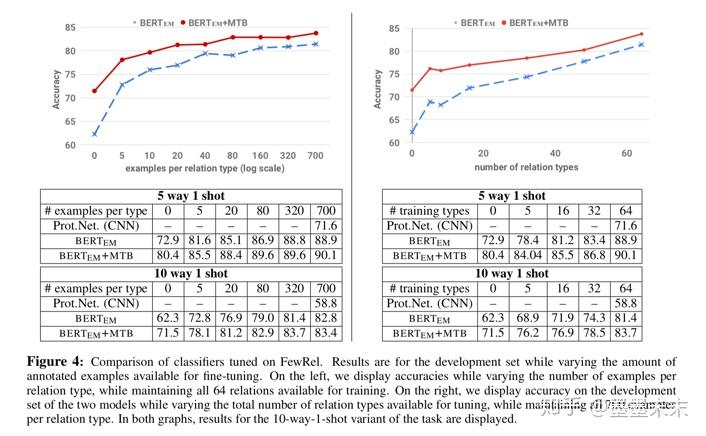
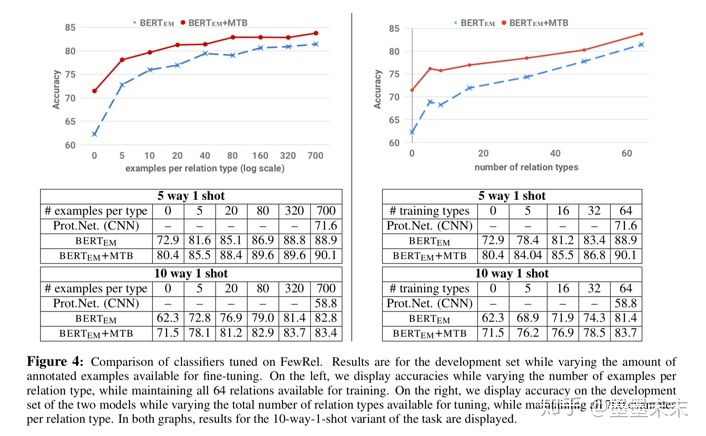
ͼ4��ʾ�˵�����Ϊÿ����ϵ��������ѵ������������������������ѵ�����������ӹ�ϵ���͵�����ʱ�����ܻ���ߡ����������ѵ������ʱ��BERTEM�ӽ�BERTEM+MTB�����ܡ�Ȼ������������ѵ�������б������еĹ�ϵ���ͣ����Ҹı�ÿ��������������ʱ��BERTEM+MTBֻ��Ҫ6%��ѵ�����ݾͿ���ƥ��BERTEMģ��������ѵ��������ѵ���ĵ����ܡ�ͼ4�еĽ��������MTBѵ����������������ʵ�ֻ��������Ĺ�ϵ��ȡϵͳ�Ĺ�������
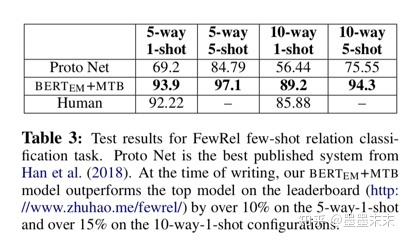
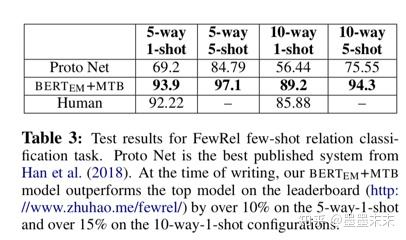
��3�б���BERTEM+MTB��FewRel��������ȫ�ල�����ϵ����ܡ����Ƿ���������������Han���ˣ�2018�꣩�������������ޡ����������ı��������������������ύ��FewRel���а��Ͷ�壬�������ѷ�������δ������
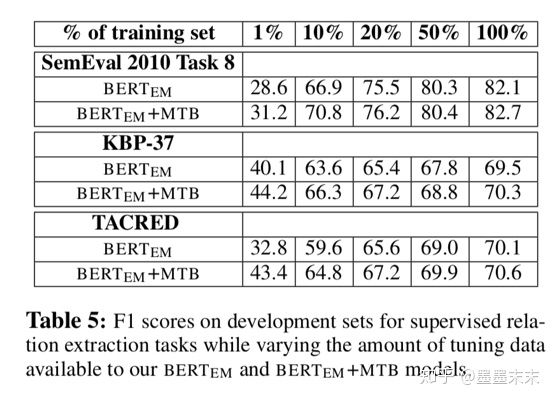
Supervised Relation Extraction
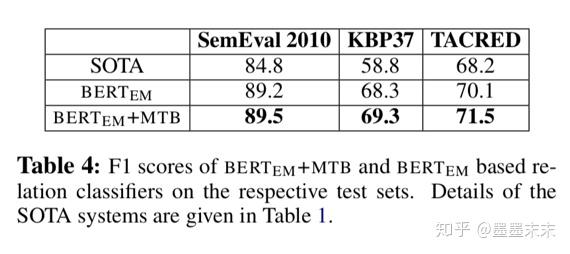
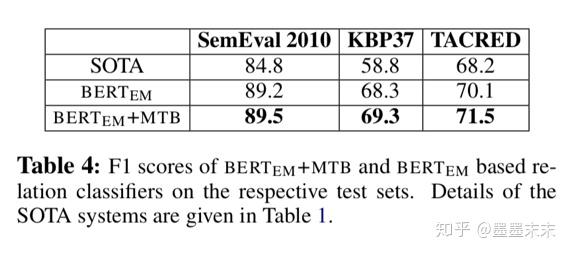
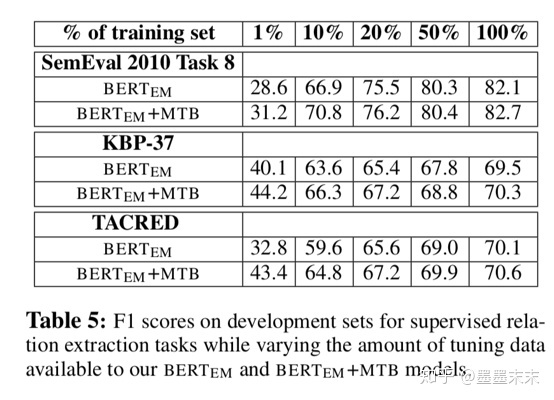
Future Work
���Ժ�Ĺ����У����Ǽƻ�����BERTEM+MTB�Ծ������Ʊ�ʾ�Ĺ�ϵ�����о��࣬�Ӷ����й�ϵ���֡����ǻ����о��������ڷֲ�ʽ֪ʶ���д洢��ϵ��Ԫ��Ĺ�ϵ��ʵ��ı�ʾ�����������֪ʶ��Ƕ�빤��������(Bordes et al., 2013; Nickel et al., 2016)��