在今天的文章里我想谈下基数计算里的一个特定问题:在查询谓语里相关列的基数计算。首先我们看下在SQL Server 7.0起的操作方法,最后我们详细看下SQL Server 2014里,在查询期间,处理相关列基数计算的全新实现方式。
什么是相关列(Correlated Columns)
在我们进入问题细节前,我们必须要澄清什么是相关列。当我们看SQL Server使用的查询优化器时,查询优化器是基于4个核心假设:
- 独立性(Independence)
- 一致性(Uniformity)
- 密封度(Containment)
- 夹杂物(Inclusion)
我不想细谈每个假设,因为它们在其它的白皮书里解释得非常清楚。在文章末尾的小结部分你会找到白皮书的链接。今天我们要聚焦的是第1个假设——独立性(Independence)。独立性意味这在查询谓语(WHERE子句)里用到的列是独立的,当各自查询时,会返回不同的记录。它们彼此间互不影响。遗憾的是这个假设并不都正确。我们来看一个具体的例子,这里违反了假设。假设下列2个查询:
1 SELECT * FROM Sales.SalesOrderHeader2 WHERE SalesOrderID > 74000 AND SalesOrderID < 750003 GO4 5 SELECT * FROM Sales.SalesOrderHeader6 WHERE OrderDate >= '20080626' AND OrderDate <= '20080724'7 GO
第1个查询返回999条记录,第2个查询返回1125条记录。但符合这2个查询条件的记录是912条,这就是说这2列之间是有关联的。但是查询优化器并没有意识到这点。
SQL Server 7.0-2012的基数计算
现在我们来看下SQL Server 7.0-2012是如何处理这个相关列的。在具体的执行计划里,第1个查询里,查询优化器估计行数是999.936,第2个查询里,查询优化器估计行数是1125。
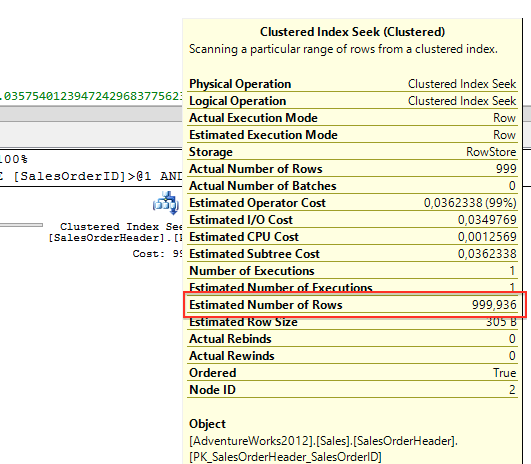
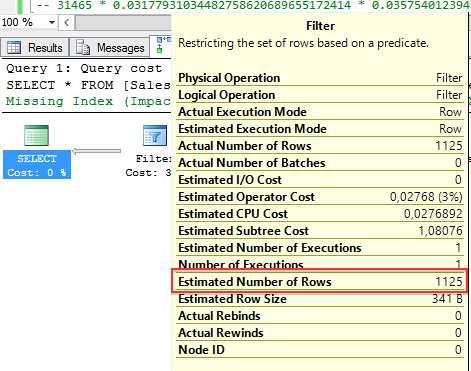
用那些信息就与基数计算我们的表(这里表总记录数是31465),我们可以计算出查询谓语所谓的选择度(Selectivity)。选择度是0到1的数字。选择度越小,从查询返回的记录越少(0表示0%的记录返回,1表示100%的记录返回)。我们可以通过估计行数除以表存储的总记录数来计算查询谓语的选择度。因此第1个查询谓语的选择度是0.03177931034482758620689655172414(999/31465),第2个查询谓语的选择度是0.03575401239472429683775623708883(1125/31465)。现在我们来看下如果我们使用AND运算符组合2个查询谓语会发生什么:
1 SELECT * FROM Sales.SalesOrderHeader2 WHERE SalesOrderID > 74000 AND SalesOrderID < 750003 AND OrderDate >= '20080626' AND OrderDate <= '20080724'4 GO
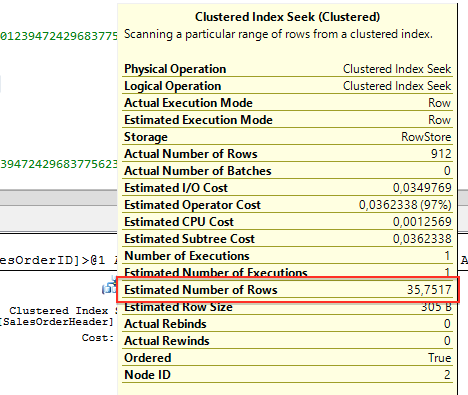
当你查看执行计划时,查询优化器在聚集索引查找(聚集的)(Clustered Index Seek (Clustered) )运算符上的估计行数是35.7517。
实际执行返回是如刚才提到的912行。这个差异太大了。查询优化器只是把2个查询谓语的选择度值相乘得出最后的估计行数。SQL Server假设2个查询谓语返回不同的行——假设这2列是彼此独立的:
0.03177931034482758620689655172414 * 0.03575401239472429683775623708883 * 31465 = 35.7517241379310344827586206896586
当然,事实是完全不一样的,因为在2个查询谓语间有巨大的关联。因此你会看到估计行数和行数之间有绝大的差异。在查询里使用更多的AND组合各个查询谓语,差异就会更大。当最后估计将至1行时,查询优化器总会估计至少1行——从不估计0行。
SQL Server 2014的基数计算
你可能已经听说了,SQL Server 2014包含了一个新的基数计算。一旦你的数据库是在120的兼容模式,新的基数计算就会用到。注意,当你从老版本的SQL Server还原或附加数据库时——这里的兼容性会变成老的!如果你想步改变兼容模式使用新的基数计算,你也可以使用新的2312跟踪标记。现在让我们对查询启用2312跟踪标记来让刚才的2个查询谓语使用新的基数计算。
1 SELECT * FROM Sales.SalesOrderHeader2 WHERE SalesOrderID > 74000 AND SalesOrderID < 750003 AND OrderDate >= '20080626' AND OrderDate <= '20080724'4 OPTION (RECOMPILE, QUERYTRACEON 2312)5 GO
当你查看执行计划时,你会看到基数计算已经变了。
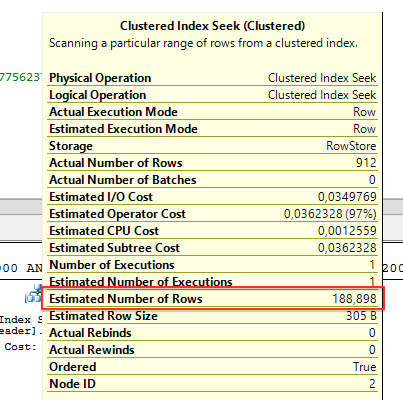
现在新的基数计算估计行数是188898.比刚才的老的基数计算的35.75行大很多。但到查询实际返回的912行还是有个大的缺口。不过现在新的基数估计用的是什么公式呢?新的基数计算使用所谓的指数退避算法(Exponential Back-off algorithm)。查询优化器取走这4个查询谓语,根据它们的选择度排序。所有的选择度再次相互相乘,但这里不同的是每个子过程值通过更大的平方根来软化。我们来看下公式来来理解这个行为:
c0 * (c1 ^ 1/2) * (c2 ^1/4) * (c3 ^ 1/8)
我们来看下具体的例子,通过下列计算就可以获得最终的基数:
0.03177931034482758620689655172414 * SQRT(0.03575401239472429683775623708883) * 31465 = 189.075212620762
比起188.898的估计行数我们的计算还有小差异,因为在SQL Server提供给执行计划里的估计行数是999.936行。使用指数退避算法,查询优化器可以确保做出更好的估计收紧估计行数和实际行数的洞,如果接受的查询参数之间有关联的话。
小结
在这篇文章里我们谈了关系数据库里基数计算期间的特定问题:作为查询谓语使用的关联列如何使用基数估计。在SQL Server 2014之前,查询优化器使用不同选择值相乘,非常平稳的方法。这会导致巨大的低估,如果执行计划里前一个运算符(例如Sort或Hash运算符)基于这些估计,它会引起麻烦。
SQL Server 2014新的基数计算对此特定问题使用增强的机制:在基数计算期间使用指数退避公式,生成更好的估计。但和运行时的实际行数还是有差异。如果你想了解更多SQL Server 2014新的基数计算,我建议看下Joe Sack写的白皮书“使用SQL Server 2014参数计算优化你的查询计划”。
感谢关注!