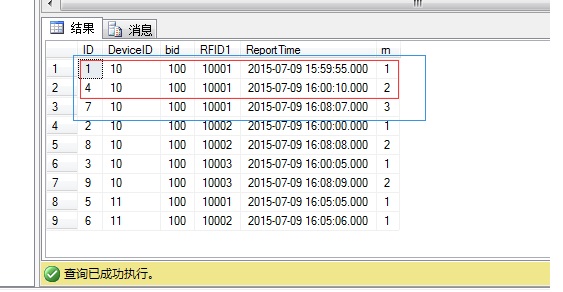
图中每个bid对应多个RFID1,每个DeviceID下面每个RFID1在采集时间一分钟以内只取1条数据,
就是图中标出的数据只取rn=1 、3 的数据,其他类似的数据也做相同的筛选
------解决思路----------------------
建议改下规则,“每分钟的时刻内只取1条”而不是“连续一分钟以内只取1条”。
即1、2都取,但是如果有多条16:00的则只取1条。
否则只能用递归(如下),速度不快
WITH g(bid,RFID1) AS ( -- 分组
SELECT DISTINCT bid,RFID1
FROM table1
)
,r AS (
-- 分组第一条
SELECT t.*
FROM g
CROSS APPLY (
SELECT top 1 *
FROM table1
WHERE table1.bid = g.bid
AND table1.RFID1 = g.RFID1
ORDER BY ReportTime
) t
UNION ALL
-- 递归取1分钟后的第一条
SELECT t.*
FROM r
CROSS APPLY (
SELECT top 1 *
FROM table1
WHERE table1.bid = r.bid
AND table1.RFID1 = r.RFID1
AND table1.ReportTime >= DATEADD(minute,1,r.ReportTime)
ORDER BY ReportTime
) t
)
SELECT * FROM r
------解决思路----------------------
; WITH cte(ID,DeviceID,bid,RFID1,ReportTime) AS (
SELECT 1,10,100,10001, '2015-07-09 15:59:55' UNION ALL -- ID = 1 和 ID = 4 的需要处理
SELECT 4,10,100,10001, '2015-07-09 16:00:10' UNION ALL -- 取 ID = 1
SELECT 7,10,100,10001, '2015-07-09 16:08:07' UNION ALL
SELECT 2,10,100,10002, '2015-07-09 16:00:00' UNION ALL -- ID = 2 和 ID = 8 的需要处理
SELECT 8,10,100,10002, '2015-07-09 16:00:08' UNION ALL -- 取 ID = 2
SELECT 3,10,100,10003, '2015-07-09 16:00:05' UNION ALL
SELECT 9,10,100,10003, '2015-07-09 16:08:09' UNION ALL
SELECT 5,11,100,10001, '2015-07-09 16:05:05' UNION ALL
SELECT 6,11,100,10002, '2015-07-09 16:05:06'
) , cte2(ID,DeviceID,bid,RFID1,ReportTime) AS (
SELECT a.ID,a.DeviceID,a.bid,a.RFID1,a.ReportTime
-- 这里做一个自连接,这样每行数据就能产生两个时间列了
FROM cte a INNER JOIN cte b ON a.DeviceID = b.DeviceID AND a.bid = b.bid AND a.RFID1 = b.RFID1 AND a.ID <> b.ID
WHERE ABS(DATEDIFF(s,a.ReportTime,b.ReportTime)) < 60
) , cte3(ID,DeviceID,bid,RFID1,ReportTime,Flag) AS (
SELECT ID,DeviceID,bid,RFID1,ReportTime,MIN(ID) OVER (PARTITION BY DeviceID,bid,RFID1) FROM cte2
) , -- 表cte4中的数据是需要删除
cte4(ID,DeviceID,bid,RFID1,ReportTime) AS (
SELECT ID,DeviceID,bid,RFID1,ReportTime FROM cte3 WHERE ID <> Flag
) -- 表cte中的所有数据剔除表cte4中的数据,剩下的数据都是有效的
SELECT * FROM cte WHERE NOT EXISTS(SELECT ID FROM cte4 WHERE cte.ID = cte4.ID)