某表T中,存在很多可能重复的记录行,现在要求保留一条重复记录并将其它重复的记录删除,记录判断依据为多个字段值相同:假设为c1,c2,c3这三个字段值相同就判断为重复记录,在网上找过,一般做法:
删除表中多余的重复记录(多个字段),只留有rowid最小的记录
delete from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
将此语句放到运行框中,却提示语法错误,原因是where后面应该跟布尔值。
照此原来写了一个:
delete a from T a
where a.id in(select b.id T b where a.c1=b.c1 and a.c2=b.c2 and a.c3=b.c3)
and a.id not in(select min(c.id) from T c where a.c1=c.c1 and a.c2=c.c2 and a.c3=c.c3)
and a.c4='xxx'
运行速度巨慢、巨卡,最后不得已终止执行。。。
向各位同学求解决办法
------解决思路----------------------
表 里应该有数据添加的时间字段吧,相同数据是同时添加的么?
有个想法,不知道适不适合你这种情况
自连接查询,找到相同的,group by 排序,
如
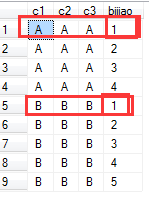
删除。。。。。。呵呵
------解决思路----------------------
不太清楚表结构,能判断重复,但总要找到不同的数据最为删除的条件
------解决思路----------------------
在不确定怎么删除的时候,请先备份表里的数据,删坏了,还有救


------解决思路----------------------
;WITH TAB AS(
SELECT ROW_NUMBER()over(partition by c1,c2,c3 order by rowid asc) id
FROM [dbo].[tabName]
)DELETE FROM TAB WHERE ID>1