以第一行数据字符做基准,计算字符连续出现的次数(注意是连续,中间断开就不算了)
请看截图,我要得到下面那个表。
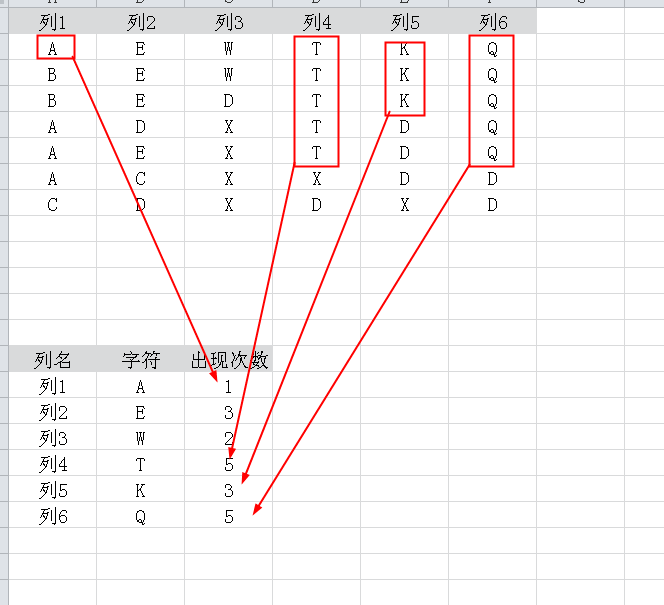
测试数据:
CREATE TABLE [dbo].[Table_test](
[id] [int] IDENTITY(1,1) NOT NULL,
[列1] [nchar](10) NULL,
[列2] [nchar](10) NULL,
[列3] [nchar](10) NULL,
[列4] [nchar](10) NULL,
[列5] [nchar](10) NULL,
[列6] [nchar](10) NULL,
CONSTRAINT [PK_Table_test] PRIMARY KEY CLUSTERED
(
[id] ASC
) ON [PRIMARY]
) ON [PRIMARY]
GO
SET IDENTITY_INSERT [dbo].[Table_test] ON
INSERT [dbo].[Table_test] ([id], [列1], [列2], [列3], [列4], [列5], [列6]) VALUES (1, N'A ', N'E ', N'W ', N'T ', N'K ', N'Q ')
INSERT [dbo].[Table_test] ([id], [列1], [列2], [列3], [列4], [列5], [列6]) VALUES (2, N'B ', N'E ', N'W ', N'T ', N'K ', N'Q ')
INSERT [dbo].[Table_test] ([id], [列1], [列2], [列3], [列4], [列5], [列6]) VALUES (3, N'B ', N'E ', N'D ', N'T ', N'K ', N'Q ')
INSERT [dbo].[Table_test] ([id], [列1], [列2], [列3], [列4], [列5], [列6]) VALUES (4, N'A ', N'D ', N'X ', N'T ', N'D ', N'Q ')
INSERT [dbo].[Table_test] ([id], [列1], [列2], [列3], [列4], [列5], [列6]) VALUES (5, N'A ', N'E ', N'X ', N'X ', N'D ', N'Q ')
INSERT [dbo].[Table_test] ([id], [列1], [列2], [列3], [列4], [列5], [列6]) VALUES (6, N'C ', N'C ', N'X ', N'D ', N'D ', N'D ')
SET IDENTITY_INSERT [dbo].[Table_test] OFF
------解决思路----------------------
dense_rank() ,
------解决思路----------------------
用递归不是很简单吗
WITH list (列名,字符,id) AS (
SELECT '列1',列1,id FROM table_test UNION ALL
SELECT '列2',列2,id FROM table_test UNION ALL
SELECT '列3',列3,id FROM table_test UNION ALL
SELECT '列4',列4,id FROM table_test UNION ALL
SELECT '列5',列5,id FROM table_test
),
cte AS (
SELECT * FROM list WHERE id=1
UNION ALL
SELECT list.*
FROM list, cte
WHERE list.列名 = cte.列名
AND list.字符 = cte.字符
AND list.id = cte.id+1
)
SELECT 列名,字符,COUNT(*) 出现次数
FROM cte
GROUP BY 列名,字符
列名 字符 出现次数
---- ---------- -----------
列1 A 1
列2 E 3
列5 K 3
列4 T 4