主表 A
主键 id
从表 B
外键 id
函数 dbo.f_getall(@id varchar(30)) ,用于查询其它值,执行速度慢
SELECT B.B_ID,
B.B_NAME,
GETALL,
AA.ID
FROM
(select ID, DBO.f_getall(A.ID) as GETALL FROM A ) as AA , B
WHERE ( AA.ID = B.ID ) and AA.id ='1'
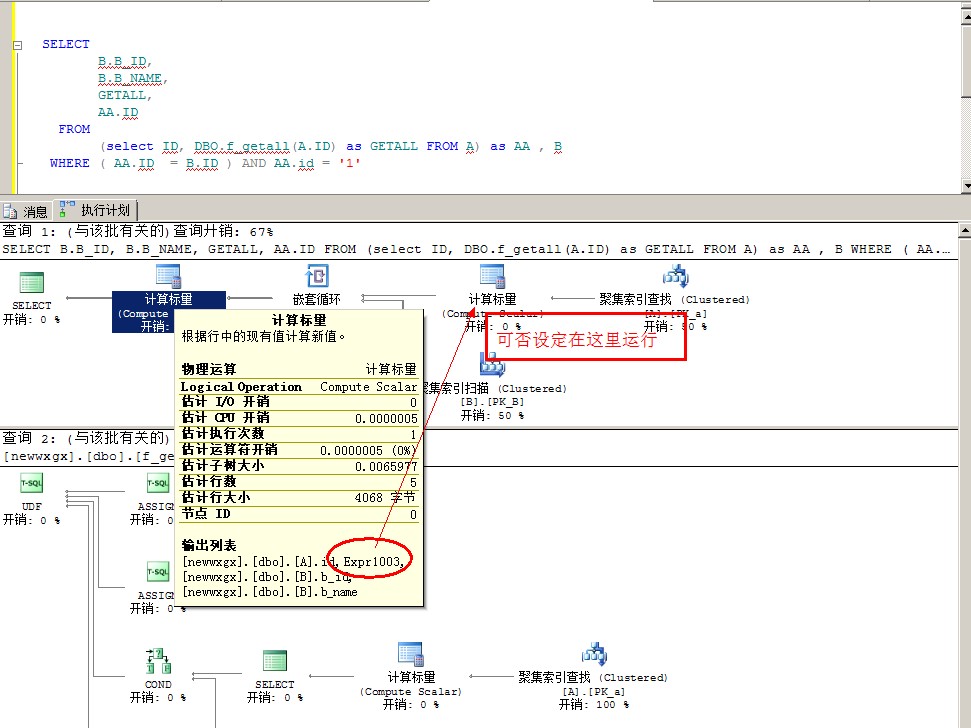
语句原本意思是,先执行 (select ID, DBO.f_getall(A.ID) as GETALL FROM A ) as AA ,然后再和B表关联查询出其它内容,这样 DBO.f_getall(A.ID) 只运行一次;
但后来发现,sqlserver 执行计划 是 A表 B表查询处理好后,最后再计算 DBO.f_getall(A.ID),如果从表有多少条记录,则 DBO.f_getall(A.ID) 就计算多少次, 由于函数 DBO.f_getall 执行比较耗时,造成耗时又延长了很多倍。
怎么样调整让 select ID, DBO.f_getall(A.ID) as GETALL FROM A 先运行?
CREATE TABLE [dbo].[A](
[id] [varchar](50) NOT NULL,
[name] [varchar](50) NULL,
CONSTRAINT [PK_a] PRIMARY KEY CLUSTERED
(
[id] ASC
) ON [PRIMARY]
) ON [PRIMARY]
INSERT A SELECT '1','11'
UNION ALL SELECT '2','22'
UNION ALL SELECT '3','33'
UNION ALL SELECT '4','44'
UNION ALL SELECT '5','55'
go
CREATE TABLE [dbo].[B](
[b_id] [varchar](50) NOT NULL,
[id] [varchar](50) NOT NULL,
[b_name] [varchar](50) NULL,
CONSTRAINT [PK_B] PRIMARY KEY CLUSTERED
(
[b_id] ASC
) ON [PRIMARY]
) ON [PRIMARY]
INSERT b SELECT '01','1','aaaaa'
UNION ALL SELECT '02','1','aaaaa'
UNION ALL SELECT '03','1','aaaaa'
UNION ALL SELECT '04','1','aaaaa'
UNION ALL SELECT '05','1','aaaaa'
UNION ALL SELECT '06','2','aaaaa'
UNION ALL SELECT '07','2','aaaaa'
ALTER TABLE [dbo].[B] WITH CHECK ADD CONSTRAINT [FK_B_A] FOREIGN KEY([id])
REFERENCES [dbo].[A] ([id])
GO
//模拟函数 耗时较多的
CREATE function dbo.f_getall(@as_id varchar(30))
returns varchar(8000)
as
begin
declare @str varchar(8000)
declare @count integer
set @str = ''
set @count = 0
WHILE @count < 1000
BEGIN
select @str = @str + '.' + ID
from A
where ID = @as_id
select @count = @count + 1
END
return (@str)
end
------解决思路----------------------
照我的理解发,SELECT最后运行的,如果还一样,那就不清楚了
另外,你可以把select ID, DBO.f_getall(A.ID) as GETALL FROM A 插入到临时表去,这样就是切实的改变执行计划了
------解决思路----------------------
是滴,只有这样了
select ID, DBO.f_getall(A.ID) as GETALL into #temp FROM A
SELECT B.B_ID,
B.B_NAME,
GETALL,
AA.ID
FROM #temp as AA inner join B
on AA.ID = B.ID where AA.id ='1'
------解决思路----------------------
像这种问题写表函数啊,标量值函数如果需要对表中字段做运算,那肯定是表有多少行就执行多少次效率低。
你处理到临时表标量值函数效率低的问题还是解决不了啊,只能是连接的效率解决了,尝试看能否换成表函数,返回id跟as GetAll的数据列,效率决然不一样。
------解决思路----------------------
考虑一下CROSS APPLY
------解决思路----------------------
确实改为表值函数后用cross apply后会先执行函数
//模拟函数 耗时较多的
create function dbo.f_getall(@as_id varchar(30))
returns @tb table(id int,getall varchar(100))
as
begin
declare @str varchar(8000)
declare @count integer
set @str = ''
set @count = 0
WHILE @count < 10
BEGIN