有个数据表,是树结构存储.共10列,当前有40W数据.
查询时用到LIKE,需要2分多钟才能获取全部数据.
有没办法提升查询效率?
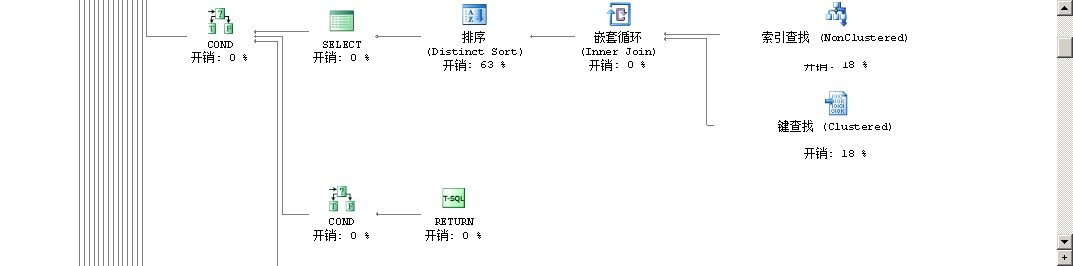
其它地方开销都为0
------解决方案--------------------
怎么用 都行呀。看你表里的内容来使用的嘛。
------解决方案--------------------
in是精确匹配,速度通常比like好,但是like和in的用处不一样
------解决方案--------------------
树结构为什么要用 distinct?应为是日志所以一个节点会出现多次?
那么为什么不从原始的树字典中先选取节点,然后再和 [_log] 进行关联?