ALTER PROC [dbo].[Insert]
@Tid Int
AS
BEGIN
IF NOT EXISTS(SELECT 1 FROM Table WHERE TId = @Tid)
BEGIN
INSERT INTO Table (
INSERTDATE,
TID
)
VALUES (
GETDATE(),
@Tid
);
END
END
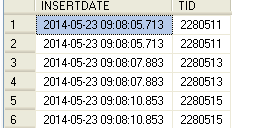
TID是其他表的主键,主要为了避免重复插入的
这是什么情况。。。
是代码的问题?
求解
------解决方案--------------------
--查了一下,说是在锁定键上建立唯一索引(约束)xlock,rowlock才有效
--我测了一下,好像也是的,如下修改存储过程,为了防止还有重复的,UI上也反馈不出来,特意加了个异常的处理,
--如果异常,则记录下来,反反复复测试了即便,2000次循环*30线程,
--结果是预期的,没有重复的
--不知道能否说明这个问题:锁定键上建立唯一索引(约束)xlock,rowlock才有效?
--锁这块一直没弄清楚,我的理解应该分两类吧,范围和锁定方式,
--像tablock,rowlock这些事范围,xlock,updlock这些事锁定方式
--不知道对不对?
drop index index_1 on t
create unique index index_1 on t(id,createdate)
truncate table t
create table logmsg(id int,msg nvarchar(100))
alter proc test_p
@i int
as
begin
begin try
begin tran
if not exists(select 1 from t with(xlock,rowlock) where id=@i )
begin
insert into t values (@i,GETDATE());
end
commit
end try
begin catch
insert into logmsg values (@i,'数据重复异常');
end catch
end
select COUNT(1),id,Createdate from t
group by id,Createdate
having(COUNT(1))>1
select * from logmsg