IF OBJECT_ID('tempdb..#mytest') IS NOT NULL
DROP TABLE #mytest
CREATE TABLE #mytest
(
[name] NVARCHAR(10) ,
[action] NVARCHAR(10)
)
CREATE NONCLUSTERED INDEX IX_mytest ON #mytest([name])
INSERT INTO #mytest
SELECT '刘德华' ,
'电视剧'
UNION ALL
SELECT '刘德华' ,
'电影'
UNION ALL
SELECT '周星驰' ,
'主持人'
UNION ALL
SELECT '周星驰' ,
'电视剧'
UNION ALL
SELECT '周星驰' ,
'电影'
--查询一
SELECT DISTINCT
a.NAME ,
t.actionlist
FROM #mytest a
CROSS APPLY ( SELECT actionlist = ( SELECT action + ';'
FROM #mytest
WHERE name = a.name
FOR
XML PATH('')
)
) t
--查询二
SELECT a.name ,
( SELECT action + ';'
FROM #mytest
WHERE name = a.name
FOR
XML PATH('')
) actionlist
FROM #mytest a
GROUP BY a.name
在数据量较大的表上查询一的效率很低,请分析下为何
像这种类似“字符串汇总”的查询效率较高的查询如何写?
------解决方案--------------------
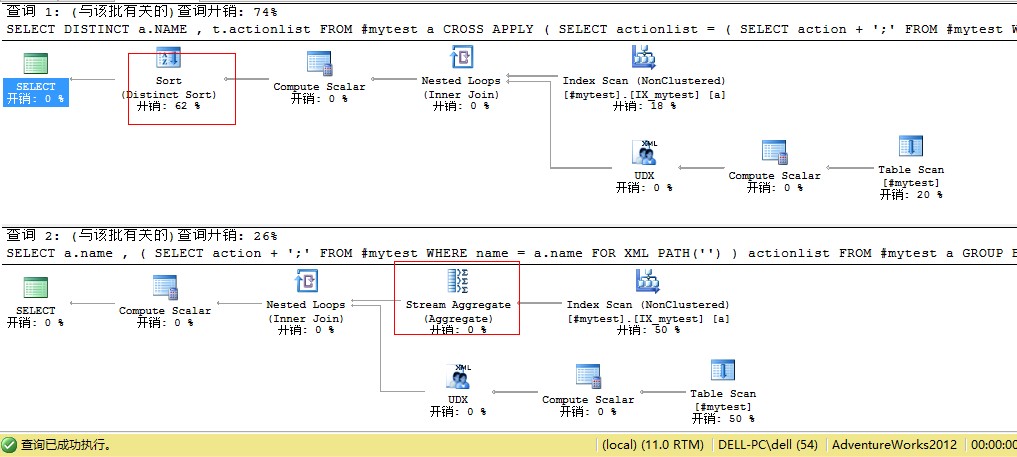
我测试了一下,上图是两个的查询计划对比,我觉得差异主要来自于查询一是对查询 cross apply后的结果进行distinct操作(name和生成的xml一起取distinct),此时distinct操作所需要的排序没办法再利用name列的索引,而查询二是对name进行group by 且name列的索引被用于group by操作而无需再进行排序的动作。
另外你可以试试将索引拿掉,其实两个的效率查的就没那么大了。
个人愚见,如有错望不吝赐教
------解决方案--------------------
用空间换时间,即专门建一个表存储此"字符串汇总"结果的数据.
每次更新基表时,用触发器同步更新该结果表.