-- 先模拟环境,后面说明:USE [Temp]GO-- DROP TABLE [TestTab] TRUNCATE TABLE [TestTab]CREATE TABLE [dbo].[TestTab]( [UserAcount] [varchar](50) NOT NULL, [UserName] [varchar](50) NOT NULL, [crdatetime] [datetime] NOT NULL, [value] [numeric](18, 4) NULL, [Info] [varchar](50) NULL, CONSTRAINT [PK_TestTab] PRIMARY KEY CLUSTERED ([UserAcount] ASC,[UserName] ASC)) ON [PRIMARY]GO-- DROP VIEW [VTestTab]CREATE VIEW [dbo].[VTestTab]ASSELECT [UserAcount],[UserName],[crdatetime],[value],[Info]FROM [dbo].[TestTab]WHERE [UserAcount] = CURRENT_USERGO-- 插入测试数据: 2538 行INSERT INTO [TestTab]([UserAcount],[UserName],[crdatetime],[value],[Info])SELECT CURRENT_USER,name,MAX(crdate),FLOOR(RAND(ABS(CHECKSUM(NEWID())))*1000),NULLFROM master.sys.sysobjectsWHERE LEN(name)>1 AND LEN(name)<50GROUP BY name
实际环境:
上面插入的数据是一个用户(CURRENT_USER)的数据,表中还存在更多用户.
由于是按用户划分管理(分库分区等)的,所以列名称[UserAcount]作为聚集索引首先放在第一列
因此,用户都是访问视图[VTestTab],查看到的只有用户自己的数据.
现有以下这个查询:
SELECT * FROM [VTestTab]WHERE [crdatetime] = '2011-06-17 03:18:08.647'
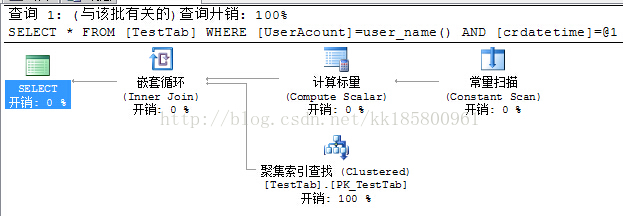
看执行计划,查询是走索引的.因为视图将转变为对表的查询,如下:
SELECT * FROM [TestTab]WHERE [UserAcount] = CURRENT_USERAND [crdatetime] = '2011-06-17 03:18:08.647'
开始以为,这个使用聚集索引已无法优化了.但是想想,按聚集索引的原理,使用聚集索引查找,表中[UserAcount] = CURRENT_USER 的数据将全部符合,也就是聚集索引将会把当前用户的数据全部查询一遍,即按主键列[UserAcount]查找一遍,并没有准确定位到时间点'2011-06-17 03:18:08.647'这行
所以,现在测试看看到底聚集索引到底查询了多少行!
--使用序列化查看,在事务结束前查看锁情况。SET TRANSACTION ISOLATION LEVEL SERIALIZABLEBEGIN TRAN SELECT * FROM [VTestTab] WHERE [crdatetime] = '2011-06-17 03:18:08.647' select resource_type,resource_description,request_mode,request_status,request_type,request_lifetime from sys.dm_tran_locks where resource_database_id=DB_ID() and request_session_id=@@SPID COMMIT TRAN
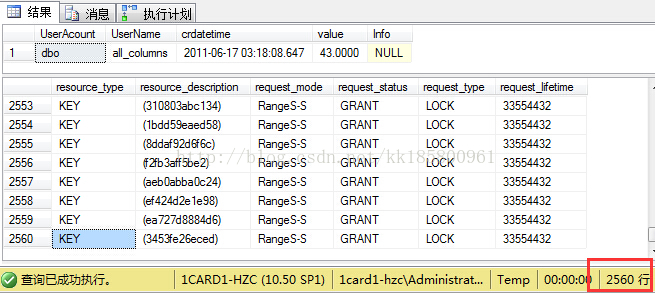
可以看到,整个哈希键都查找了一遍.有页锁(PAGE:IS),键范围锁(KEY:RangeS-S)。把符合索引键[UserAcount]的用户到查询出来了!但最终只返回一行。
如果表中的数据达到了锁升级要求(表行数五六千以上),对表将升级为共享锁!

既然不是最好的,那就考虑另外的索引定位了!
当前聚集索引键列为:([UserAcount],[UserName])
现考虑4种索引创建方法,到底哪种比较较好!~
-- DROP INDEX IX_TestTab ON [TestTab]CREATE NONCLUSTERED INDEX IX_TestTab ON [TestTab]([UserAcount],[crdatetime])CREATE NONCLUSTERED INDEX IX_TestTab ON [TestTab]([crdatetime])CREATE NONCLUSTERED INDEX IX_TestTab ON [TestTab]([crdatetime],[UserAcount])CREATE NONCLUSTERED INDEX IX_TestTab ON [TestTab]([crdatetime])INCLUDE([value],[Info])
--第一种:CREATE NONCLUSTERED INDEX IX_TestTab ON [TestTab]([UserAcount],[crdatetime])
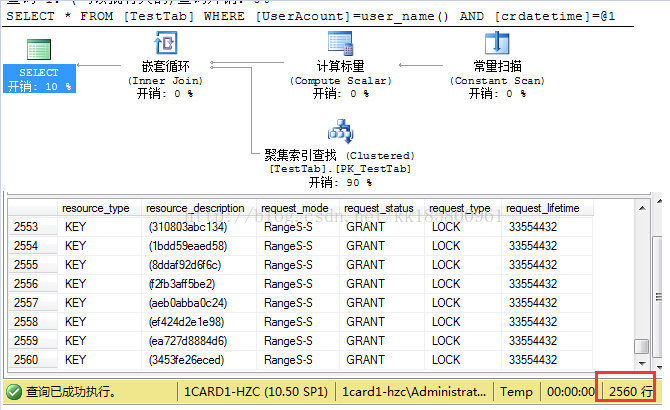
这种还是使用聚集索引,并没有用到新的索引,因为新的索引第一个键列为 [UserAcount],与聚集索引一样,所以只要有[UserAcount] ,查询就使用聚集索引了!这个索引加上去也是白加。
--第二种:CREATE NONCLUSTERED INDEX IX_TestTab ON [TestTab]([crdatetime])
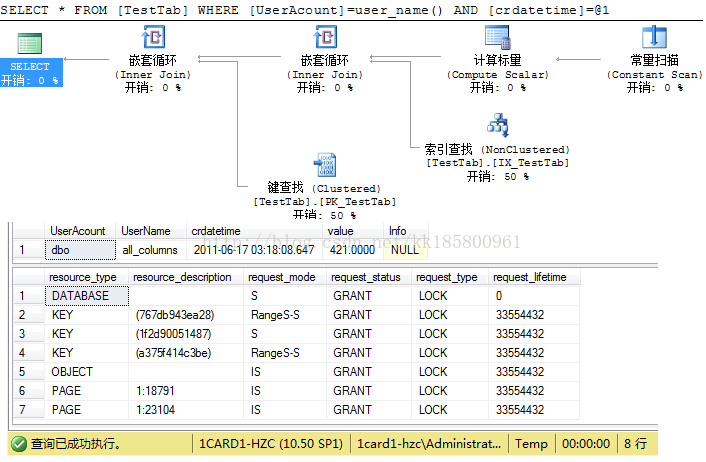
这个查询使用了索引查找,直接按列 [crdatetime] 查询,但是其他不包含在索引的列,使用了键查找。还得在索引子页中查找非索引列。并且锁少了很多!!
--第三种:CREATE NONCLUSTERED INDEX IX_TestTab ON [TestTab]([crdatetime],[UserAcount])
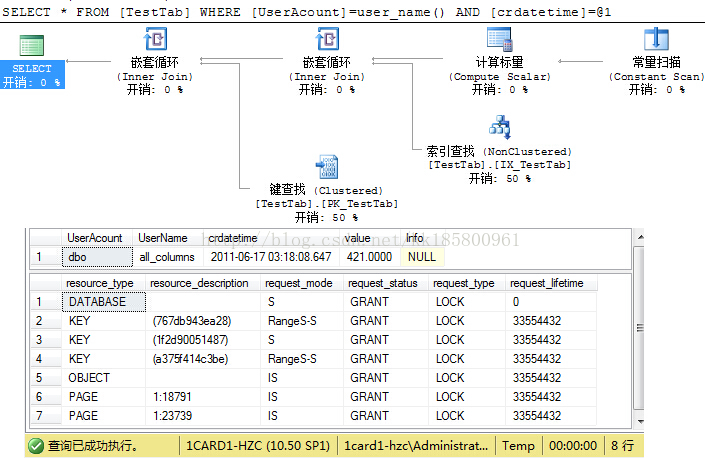
这种查询的执行计划与上面的一致,因为缓存计划进行了参数化,两者执行语句一样,使用的索引不影响执行计划。而且锁定的资源几乎一样。这个索引的另一列 [UserAcount] 其实是多余了,因为非聚集索引中都会包含聚集索引的键列。所以这个索引的第二列[UserAcount]可以去掉了。
--第四种:CREATE NONCLUSTERED INDEX IX_TestTab ON [TestTab]([crdatetime])INCLUDE([value],[Info])
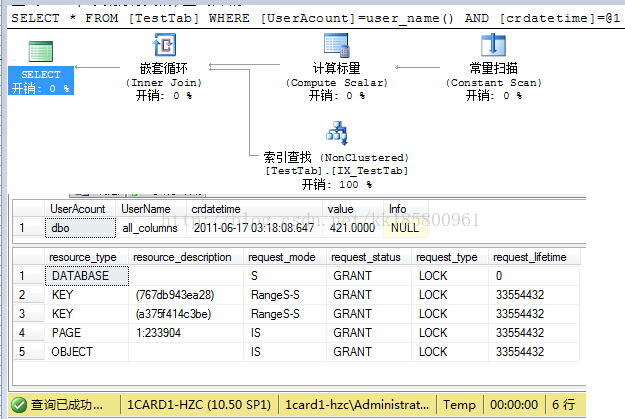
这个锁定的资源就比较直接了!~完全使用非聚集索引查找,查询直接定位到数据行!~
所以对于聚集索引,应尽量使用唯一列作为聚集索引,或者最为键列的数据尽量不要重复,这样才能以最快速度定位到行。若没有唯一列,像上面的例子中,聚集索引和另一个比较有效的列作为组合索引聚集索引!~