? ? ? ?Ъ§ОнПтгІгУПЊЗЂжаЃЌОГЃЛсгіЕНвЛаЉБШНЯИДдгЕФSQLЪНМЦЫуЃЌБШШчМЧТМВ№ЗжЃЌНЋАДЗжИєЗћЗжИєЕФвЛЬѕМЧТМВ№ЗжГЩЖрЬѕМЧТМЁЃSQLдкЪЕЯжЪБгЩгкЪ§ОнПтМфЕФВювьЃЌЛсгіЕНгяЗЈжЇГжВЛзуЁЂЧЖЬзЖрВуЕШЮЪЬтЁЃЖјМЏЫуЦїОпгаЗсИЛЕФРрПтЃЌПЩвдБраДжБЙлЗжВНЕФНХБОЃЌЭъГЩетРрМЦЫувЊМђЕЅаэЖрЃЌЯТУцЭЈЙ§вЛИіР§згРДПДвЛЯТМЏЫуЦїЕФЪЕЯжЗНЪНЁЃ
?
?????? гІгУГЬађНЋгУЛЇвЛДЮЕЧТНКѓЕФЫљгаВйзїДњТыАДЖККХЗжИєЃЌвдвЛЬѕМЧТМДцДЂЕНЪ§ОнПтгУЛЇВйзїБэuser_opжаЃЌИУБэВПЗжЪ§ОнШчЯТЃК
LOGTIME???????????? USERID OPID
2014/1/3 11:10:12? 100001??? a,d,h
2014/1/3 9:23:12??? 100002??? a,e,g,p
2014/1/3 10:35:11? 100003??? a,r,n
??????
?????? ЯжашвЊНЋЖККХЗжИєЕФOPIDВ№ЗжГЩЖрааЃЌШчЕквЛЬѕМЧТМВ№ЗжКѓгІЮЊЃК
LOGTIME???????????? USERID OPID
2014/1/3 11:10:12? 100001??? a
2014/1/3 11:10:12? 100001??? d
2014/1/3 11:10:12? 100001??? h
?
?????? SQLдкЪЕЯжетРрдЫЫуЪБашвЊНшжњЕнЙщВщбЏЪЕЯжЃЌЖдгкЕнЙщВщбЏжЇГжВЛКУЕФЪ§ОнПтЪЕЯжЦ№РДвьГЃРЇФбЃЌЖјЖдЕнЙщВщбЏжЇГжВЛДэЕФOracleЪЕЯжвВВЂВЛМђЕЅЃЌБШШчЯТУцЕФSQLЪЕЯжгяОфЃК
SELECT logtime,userid,REGEXP_SUBSTR(opid,'[^,]+',1,rn) opidFROM user_op,(SELECT LEVEL rn FROM DUALCONNECT BY LEVEL<=(SELECT MAX(length(trim(translate(opid,replace(opid,','),' '))))+1 FROM user_op))WHERE REGEXP_SUBSTR(opid,'[^,]+',1,rn) IS NOT NULL
?
Лђеп
select logtime,userid,regexp_substr(opid,'[^,]+',1,level) opidfrom user_opconnect by level <= length(opid)-length(regexp_replace(opid,'[^,]+',''))and rowid= prior rowidand prior dbms_random.value is not null
?? ? ??
?
ДгвдЩЯЕФЪЕЯжжаПЩвдПДГіSQLЪЕЯжЕФИДдгадЃЌЯТУцПДвЛЯТМЏЫуЦїЕФЪЕЯжДњТыЃК
?
? ?ЦфжаЃК
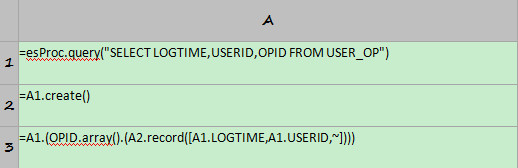
? ? ? ?A1=esProc.query("SELECT LOGTIME,USERID,OPID FROM USER_OP")
ДгЪ§ОнПтжаВщбЏuser_opБэЪ§ОнЃЌВПЗжВщбЏНсЙћШчЯТЃК

?
? ? ? ? ?A2= A1.create()
?
???????? ИљОнA1ЕФађБэДДНЈаТађБэЃЌВЂИДжЦA1ЕФНсЙЙЃЌгУгкДцДЂзюжеНсЙћМЏЁЃНсЙћШчЯТЃК

?
? ? ? ? ?A3=A1.(OPID.array().(A2.record([A1.LOGTIME,A1.USERID,~])))
?
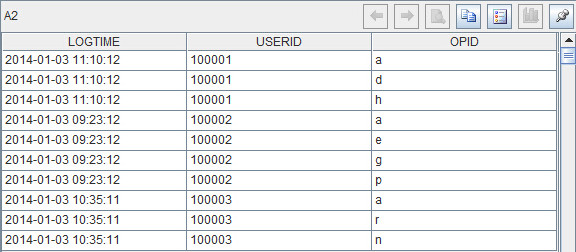
???????? бЛЗA1ађБэЃЌВ№ЗжOPIDзжЖЮжЕЃЌзЊЮЊзЊЮЊађСаЃЌВЂНЋВ№ЗжКѓНсЙћаДЛиA2НсЙћМЏЁЃМЦЫуКѓЕФA2НсЙћШчЯТЃК
?
? ? ? ? ?ПЩвдПДЕНдкМЏЫуЦїжаЭЈЙ§етбљМђЕЅЕФШ§ааДњТыОЭЭъГЩСЫВ№ЗжМЧТМЕФМЦЫуЁЃСэЭтЃЌМЏЫуЦїПЩБЛБЈБэЙЄОпЛђjavaГЬађЕїгУЃЌЕїгУЕФЗНЗЈвВКЭЦеЭЈЪ§ОнПтЯрЫЦЃЌЪЙгУЫќЬсЙЉЕФJDBCНгПкМДПЩЯђjavaжїГЬађЗЕЛиResultSetаЮЪНЕФМЦЫуНсЙћЃЌОпЬхЗНЗЈПЩВЮПМЯрЙиЮФЕЕЁЃ