jsoup ���
Java �����ڽ��� HTML �ĵ�ʱ�����Ŵ�Ҷ��Ӵ��� htmlparser �����Դ��Ŀ���������� IBM DW �Ϸ�������ƪ���� htmlparser �����£��ֱ��ǣ���HTML�о�ȡ���������Ϣ ����չ HTMLParser ���Զ����ǩ�Ĵ������������������Ѿ�����ʹ�� htmlparser �ˣ�ԭ���� htmlparser ���ٸ��£�������Ҫ�������� jsoup ��
jsoup ��һ�� Java ��HTML ����������ֱ�ӽ���ij��URL��ַ��HTML�ı����ݡ����ṩ��һ�dz�ʡ����API����ͨ��DOM��CSS�Լ���似��jQuery�IJ���������ȡ���Ͳ������ݡ�
jsoup����Ҫ�������£�
1. ��һ��URL���ļ����ַ����н���HTML��
2. ʹ��DOM��CSSѡ���������ҡ�ȡ�����ݣ�
3. �ɲ���HTMLԪ�ء����ԡ��ı���
jsoup�ǻ���MITЭ�鷢���ģ��ɷ���ʹ������ҵ��Ŀ��
jsoup ����Ҫ���νṹ����ͼ��ʾ��

����������ר����Լ��ֳ�����Ӧ�ó�������˵�� jsoup ��������ŵĽ��� HTML �ĵ������ġ�
�ĵ�����
jsoup ���ԴӰ����ַ�����URL��ַ�Լ������ļ������� HTML �ĵ��������� Document ����ʵ����
��������ش��룺
// ֱ�Ӵ��ַ��������� HTML �ĵ�
String html = "<html><head><title>��Դ�й�����</title></head>"
+ "<body><p>������ jsoup ��Ŀ���������</p></body></html>";
Document doc = Jsoup.parse(html);
// ��URLֱ�Ӽ��� HTML �ĵ�
Document doc = Jsoup.connect("http://www.oschina.net/").get();
String title = doc.title();
Document doc = Jsoup.connect("http://www.oschina.net/")
.data("query", "Java") //�������
.userAgent("I��m jsoup") //����User-Agent
.cookie("auth", "token") //����cookie
.timeout(3000) //�������ӳ�ʱʱ��
.post(); //ʹ��POST��������URL
// ���ļ��м��� HTML �ĵ�
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/");
����ע�����һ�� HTML �ĵ����뷽ʽ�е� parse �ĵ�����������Ϊʲô��Ҫ������ָ��һ����ַ�أ���Ȼ���Բ�ָ�������һ�ַ���������Ϊ HTML �ĵ��л��кܶ��������ӡ�ͼƬ�Լ������õ��ⲿ�ű���css�ļ��ȣ�����������Ϊ baseURL �IJ�������˼���ǵ� HTML �ĵ�ʹ�����·����ʽ�����ⲿ�ļ�ʱ��jsoup ���Զ�Ϊ��Щ URL ����һ��ǰ��Ҳ������� baseURL��
���� <a href=/project>��Դ����</a> �ᱻת���� <a href=http://www.oschina.net/project>��Դ����</a>��
��������ȡ HTML Ԫ��
�ⲿ���漰һ�� HTML ������������Ĺ��ܣ��� jsoup ʹ��һ���б���������Դ��Ŀ�ķ�ʽ�D�Dѡ���������ǽ������һ������ϸ���� jsoup ѡ�������������㽫���� jsoup ���������Ĵ���ʵ�֡�
���� jsoup Ҳ�ṩ�˴�ͳ�� DOM ��ʽ��Ԫ�ؽ�������������Ĵ��룺
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://www.oschina.net/");
Element content = doc.getElementById("content");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
}
����ܻ���� jsoup �ķ���似����ʶ��û������ getElementById �� getElementsByTag ������ JavaScript �ķ���������һ���ģ�����Ҳ��ȫһ�¡�����Ը��ݽڵ����ƻ����� HTML Ԫ�ص� id ����ȡ��Ӧ��Ԫ�ػ���Ԫ���б���
�� htmlparser ��Ŀ��ͬ���ǣ�jsoup ��û��Ϊ HTML Ԫ�ض���һ����Ӧ���࣬һ��һ�� HTML Ԫ�ص���ɲ��ְ������ڵ��������Ժ��ı���jsoup �ṩ�ķ��������Լ�������Щ���ݣ���Ҳ�� jsoup ����������ԭ��
����Ԫ�ؼ������棬jsoup ��ѡ������ֱ�������ܣ�
File input = new File("D:\test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/");
Elements links = doc.select("a[href]"); // ���� href ���Ե�����
Elements pngs = doc.select("img[src$=.png]");//��������pngͼƬ��Ԫ��
Element masthead = doc.select("div.masthead").first();
// �ҳ������� class=masthead ��Ԫ��
Elements resultLinks = doc.select("h3.r > a"); // direct a after h3
���� jsoup ���������۷��ĵط���jsoup ʹ�ø� jQuery һģһ����ѡ������Ԫ�ؽ��м��������ϵļ���������������������� HTML �����������ٶ���Ҫ�ܶ��д��룬�� jsoup ֻ��Ҫһ�д��뼴����ɡ�
jsoup ��ѡ������֧�ֱ���ʽ���ܣ����ǽ������һ�ڽ��������ǿ��ѡ������
������
�ڽ����ĵ���ͬʱ�����ǿ��ܻ���Ҫ���ĵ��е�ijЩԪ�ؽ����ģ��������ǿ���Ϊ�ĵ��е�����ͼƬ���ӿɵ�����ӡ������ӵ�ַ���������ı��ȡ�
������һЩ�����ӣ�
doc.select("div.comments a").attr("rel", "nofollow");
//������������ rel=nofollow ����
doc.select("div.comments a").addClass("mylinkclass");
//������������ class=mylinkclass ����
doc.select("img").removeAttr("onclick"); //ɾ������ͼƬ��onclick����
doc.select("input[type=text]").val(""); //��������ı�������е��ı�
�����ܼ���ֻ��Ҫ���� jsoup ��ѡ�����ҳ�Ԫ�أ�Ȼ��Ϳ���ͨ�����ϵķ����������ģ��������ı�ǩ���⣨����ɾ�����ٲ����µ�Ԫ�أ�������Ԫ�ص����Ժ��ı��������ġ�
����ֱ�ӵ��� Element(s) �� html() �����Ϳ��Ի�ȡ����� HTML �ĵ���
HTML �ĵ�����
jsoup ���ṩǿ��� API ͬʱ�����Ի�����Ҳ���÷dz��á�������վ��ʱ�������ṩ�û����۵Ĺ��ܡ���Щ�û��Ƚ����������һЩ�ű������������У�����Щ�ű����ܻ��ƻ�����ҳ�����Ϊ�������ص��ǻ�ȡһЩ��Ҫ��Ϣ������ XSS ��վ�㹥��֮��ġ�
jsoup ���ⷽ���֧�ַdz�ǿ��ʹ�÷dz�������������δ��룺
String unsafe = "<p><a href='http://www.oschina.net/' onclick='stealCookies()'>��Դ�й�����</a></p>"; String safe = Jsoup.clean(unsafe, Whitelist.basic()); // ���: // <p><a href="http://www.oschina.net/" rel="nofollow">��Դ�й�����</a></p>
jsoup ʹ��һ�� Whitelist �������� HTML �ĵ����й��ˣ������ṩ�������÷�����
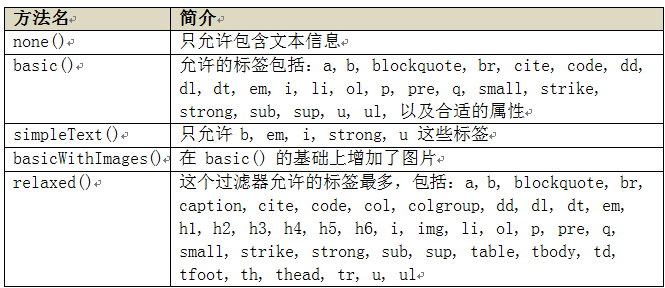
�������������������������Ҫ���أ������������û����� flash ������û��ϵ��Whitelist �ṩ��չ���ܣ����� whitelist.addTags("embed","object","param","span","div"); Ҳ�ɵ��� addAttributes ΪijЩԪ���������ԡ�
jsoup �Ĺ���֮���D�Dѡ����
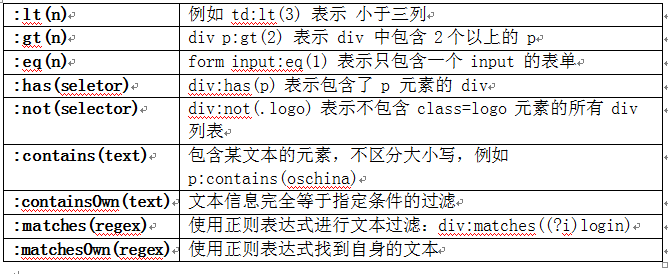
ǰ�������Ѿ��Ľ����� jsoup �����ʹ��ѡ��������Ԫ�ؽ��м����ġ��������ǰ��ص����ѡ��������ǿ�����ϡ��±��� jsoup ѡ�������������ϸ�б���
�����÷�

�������������ѡ���������Щ�Ҳ�����������ʹ�ã������� jsoup ֧�ֵ�����÷���

����һЩ��������Լ���Щ���������⣬jsoup ��֧��ʹ�ñ���ʽ����Ԫ�ع���ѡ�������� jsoup ֧�ֵ����б���ʽһ������
�ܽ�
jsoup �Ļ������ܵ�����ͽ�����ϣ������� jsoup ���õĿ���չ�� API ��ƣ������ͨ��ѡ�����Ķ������������dz�ǿ��� HTML �������ܡ��ټ��� jsoup ��Ŀ�����Ŀ���Ҳ�dz���Ծ��������������ʹ�� Java ����Ҫ�� HTML ���д������������ԡ�