Index Scan Access Methods????? 索引扫描访问方法? (page 95)
??? If you have a book about U.S. Presidents and want to find information on Jimmy Carter, you could start
on the first page and visually scan each page until you came to the section of the book about Carter. ?
However, it would take a lot of time to do that scan so you might find it more expedient to look up
Carter in the book’s index.? Once you have the page number, you can go directly to that location. An
index scan operation is conceptually similar to using an index in a book.
??? 如果你有一本关于美国总统的书,且想要找出Jimmy Carter的信息,你可从第一页开始扫描每一页直到你到达关于Cater的那一节。然而,扫描将耗费你很多时间,如此的话,你可通过在书的索引中查找Carter更为方便的找到它。一旦你有了页码号,你就能直接的到达位置。索引扫描操作概念上相似于使用书中的索引。
??? The default index type is a B-tree index and is the only type I am going to discuss in this chapter. ?
Indexes are created on one or more table columns or column expressions and store the column values
along with a rowid.? There are other pieces of information stored in the index entry, but for your
purposes you’re only going to concern yourselves with the column value and the rowid.? The rowid is a
pseudocolumn that uniquely identifies a row within a table.? It is the internal address of a physical
table row and consists of an address that points to the data file that contains the table block that
contains the row and the address of the row within the block that leads directly to the row itself.? ?
Listing 3-7 shows how to decode the rowid into a readable form.
??? 默认的索引类型是B-tree索引且也是我在本章中唯一讨论的。索引创建在一个或多个表列或列的表达式上,且存储的列值带有一个rowid。还有其他一些信息也存于索引记录中,但是为了便于理解,你现在只需关心列值和rowid。rowid是一个伪列,唯一的标示表中的一行。它是物理表行的内部地址又组成了指向数据文件的地址,数据文件包含表块,表块包含行而在块中的行地址就能找到行本身。列表3-7展示了如何解码rowid成可读的形式。
Listing 3-7. Decoding rowid
SQL> column filen format a50 head 'File Name'
SQL>
SQL> select? e.rowid ,
? 2????????? (select file_name
? 3???????????? from dba_data_files
? 4??????????? where file_id = dbms_rowid.rowid_to_absolute_fno(e.rowid, user, 'EMP'))???? filen,
? 5????????? dbms_rowid.rowid_block_number(e.rowid) block_no,
? 6????????? dbms_rowid.rowid_row_number(e.rowid) row_no
? 7??? from? emp e
? 8?? where? e.ename = 'KING' ;
?
ROWID?????????????????????????? File Name?????????????????????????????????????????????????????????????????????????????? BLOCK_NO?? ROW_NO
------------------??????????????????? ----------------------------------------------- ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ---------???????? --------
AAANprAAEAAAWVvAAI?? C:\ORACLE\PRODUCT\11.2.0\ORADATA\DB\USERS01.DBF?? 91503?????? ?? 8
?
1 row selected.
? ? As you can see, the rowid points to the exact location of a particular row.? Therefore, when an index
is used to access a row, all that happens is that a match is made on the access criteria provided in the
predicate, then the rowid is used to access the specific file/block/row of data.? Block accesses made via
an index scan are made using single-block reads.? That makes sense when you consider how the rowid
is used.? Once the index entry is read, only the single block of data identified by that rowid is retrieved;
once it is retrieved, only the row specified by the rowid is accessed.??
??? 如你所见,rowid指向某一行的准确位置。因此,当用某索引访问某行时,所发生的事就是匹配在谓词中提供的访问标准,然后用rowid访问特定的文件/块/行数据。通过索引扫描访问块使用的是单块读。这很容易理解,若你考虑到rowid是如何使用的话。一旦读取了索引记录,就检索了由rowid标识的唯一的单块,检索后,由rowid指向的唯一行就访问到了。
??? What this means is that for each row that will be retrieved via an index scan, at least two block
accesses will be required: at least one index block and one data block.? If your final result set contains
100 rows and those 100 rows are retrieved using an index scan, there would be at least 200 block
accesses required.? I keep saying “at least” because depending on the size of the index, Oracle may
have to access several index blocks initially in order to get to the first matching column value needed.??
??? 这意味着每行都可以通过索引扫描检索,至少需要两个块访问:至少一个索引块和一个数据块。如果你最终的结果集包含100行而这100行由使用索引扫描检索,则至少需要200次块访问。我总是说“至少”因为取决于索引的大小,最初时Oracle可能必须访问好几次索引块为了获取第一个所需的匹配列值。
Index Structure???? 索引结构????? (page 96)
??? An index is logically structured, as shown in Figure 3-4.? Indexes are comprised of one or more levels
of branch blocks and a single level of leaf blocks.? Branch blocks hold information about the range of
values contained in the next level of branch blocks and are used to search the index structure to find
the needed leaf blocks.? The height? of an index is the number of branch levels between the initial
branch block (referred to as the root block) and the leaf blocks.? The leaf blocks contain the indexed
values and the rowid for each in sorted order as mentioned previously.
??? 索引的逻辑结构,如图3-4所示。索引由一级或多级分支块和一单级叶块构成。分支块持有信息:关于在下一级分支块包含的值的范围,和用于搜索索引结构和找出所需的叶块。索引的高度是指在初始分支块(就是根块)和叶块之间的分支层级数。页块包含索引值而每个的rowid已排序,如之前所述。
??? If you start with a newly created, empty table and create an index on that table, the index consists
of one, empty block.? In this case, the single block acts as both a root block and a leaf block.? The height
of the index will be 1.? There is another statistic called blevel? that represents the number of branch
levels present in an index.? In this case, the blevel would be 0.
??? 如果你从一张新创建的空表开始再在那表上创建一索引,则索引由一个空块组成。这种情况下,该单块的作用既是根块又是叶块。索引的高度就是1。还有一种统计法称为blevel,代表某索引的分支层级。这种情况下,blevel将是0。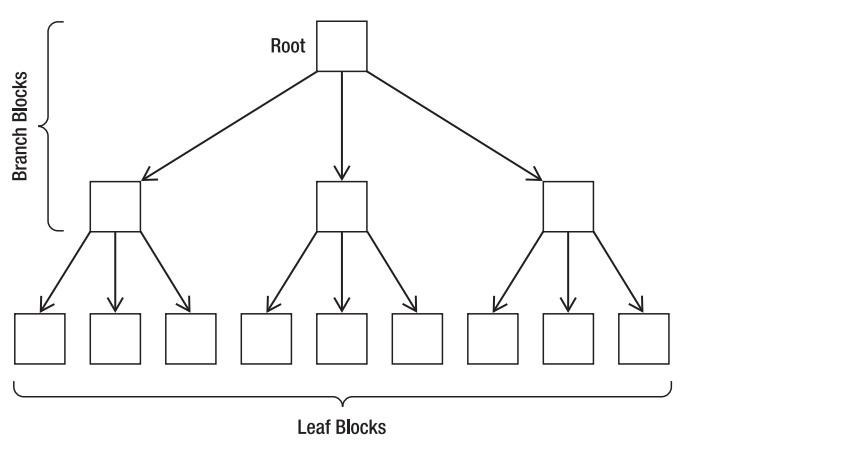
?Figure 3-4. Logical view of an index structure???? 索引结构的逻辑图
???? As new rows are added to the table, new index entries are added to the block, and it will fill to the
point where additional entries won’t fit.? At this point, Oracle will allocate two new index blocks and
place all the index entries into these two new leaf blocks.? The previously filled single root block is
now replaced with pointers to the two new blocks.? The pointers are made up of the Relative Block
Address (RBA) to the new index blocks and a value indicating the lowest indexed value (i.e. lowest in
sorted order) found in the referenced leaf block.? With this information in the root block, Oracle can
now search the index to find specific leaf blocks that hold a requested value.? At this point, the index
now has a height of 2 and a blevel of 1.
??? 当新行加入表中,新索引记录加入块,且它将填充块直到新的索引记录不再合适。从那点起,Oracle将分配两个新的索引块再把所有的索引记录放入这两个新的叶块中。之前填满的单个根块现在由指向两个新块的指针所代替。指针由相对块地址(RBA)组成,指向新的索引块和一个标示的最低索引值(例如,有序列中的最小值),用于找出引用的叶块。通过根块中的这些信息,Oracle现在能搜索带有请求值的特定叶块的索引。此时,索引的高度就是2,而blevel是1。
??? Over time, as more rows are inserted into the table, index entries are added into the two leaf
blocks that were just created.? As these leaf blocks fill up, Oracle will add one leaf block and allocate the
index entries between the full and new leaf blocks.? Every time a leaf block fills up and splits, a new
pointer for this new leaf block will be added to the root block.? Eventually, the root block will fill up and
the process repeats with the root being split into two new branch blocks.? When this split occurs, the
height of the index will increase to 3 and the blevel to 2.
??? 随着时间推移,越多的行插入表中,索引记录也加入到刚创建的两个叶块中。因为这两个叶块填满,Oracle将再加一个叶块且分配索引记录到满的和新的叶块中。每次一叶块填满和分裂,指向新叶块的新指针就会加入根块。最终根块将填满,而这个过程重复,根块将分裂成两个新的分支块。当这次分裂发生时,索引的高度将增加到3而blevel变成2。
??? At this point, as new index entries are made, the leaf blocks will fill and split, but instead of a new
pointer being added to the root block, the pointer will be added to the corresponding branch block.?
Eventually the branch blocks will fill and split.? It is at this point that a new entry gets added to the root
block.? As this process continues, eventually the root block will fill up and split increasing the height of
the index once again.? Just remember that the only time the height of an index increases is when the
root block splits.? For that reason, all leaf blocks will always be at the same distance from the root block.?
This is why you’ll hear the term? balanced used in regard to Oracle B-tree indexes.? Indexes are
guaranteed to remain height-balanced.
??? 此时,当新的索引记录产生,叶块将填充和分裂,但是不是新的指针加入到根块中,指针被加入到相应的分支块中。最终分支块将填满和分裂。而那时新的记录才加入根块中。随着这个过程的继续,最终根块将填满再分裂而再次增加索引的高度。只要记住当根块分裂时索引的高度就会增加。正因为如此,所有叶块将到根块的距离是相同的。这就是为什么你听到术语“平衡”用在Oracle B-树索引中(B指的是Balance)。生成的索引保持高度平衡。
??? Why go through all this detail?? Understanding how an index structure is created and maintained
will help you understand how the various types of index scans work.? Now that you have an
understanding of how indexes are structured, you’re ready to discover how the different index scans
traverse that structure to retrieve row data that your query needs.
??? 为什么把讨论这些细节?理解一索引结构如何创建和维护将有助于你理解各种类型的索引扫描是如何工作的。既然你理解了索引是如何构造的,你就容易发现不同的索引扫描遍历(索引)结构,检索你查询所需数据,是如何的不同。
详细解决方案
《Pro Oracle SQL》Chapter3-3.2 Index Scan Access Methods-3.2.1 Index Structure
热度:10494 发布时间:2013-02-26 00:00:00.0
相关解决方案
- 求教,SSH + ORACLE 日期处理有关问题
- hibernate 连接 oracle session 有关问题
- Spring自动扫描 <context:componet-scan>和加了<context:include-filter>以后有什么区别
- java.sql.SQLException: Access denied for user 'root'@'localhost' (using password,该如何处理
- eclipse+tomcat6.0+oracle 10g配置数据库连接池的异常
- java.sql.SQLException: [Microsoft][ODBC Microsoft Access Driver] 找不到资料 '(未知的)'
- java.sql.SQLException: Access denied for user 'root'@'localhost' (using password解决思路
- index.jsp经过模拟action接口 转发 到login.jsp页面后,页面背景无法显示
- java 生成 word 封存到 oracle 数据库
- jsp access 图片调用的有关问题
- oracle 最大连市接数 为什么main方法无限拿连接
- oracle 分页排序,ssi,该怎么处理
- oracle 最近的时间(而不是前一天的时间) 跪求sql语句 。解决方法
- 小弟我用JSP+ACCESS+tomcat 5.0 JDK1.4做的一个网站
- java.sql.SQLException: No suitable driver found for jdbc:oracle:thin:192.168解决思路
- Parameter index out of range (五 > number of parameters, which is 4)
- java.lang.ClassNotFoundException: oracle.jdbc.driver.OracleDriver,该怎么处理
- 求高手看一看!index.jsp可以进,在往上点就出现有关问题了
- Jsp + Oracle 怎么取回id,报错getInt not implemented for class oracle.jdbc.driver.T4CRo
- oracle 调用java程序,该如何处理
- oracle,该怎么解决
- 在 Hibernate3 查询不到 Oracle 11g 里的记录
- tomcat启动出现Caused by: java.lang.StringIndexOutOfBoundsException: String index out解决方法
- JSP有关问题 index.jsp使用meta 页面都跳转不过去
- Oracle 评论排序!该怎么解决
- 出现异常:cvs [server aborted]:"passwd" requires write access to the repository
- oracle 安装时出现 java tm 异常
- android访问其他数据库(如:oracle、MySql等),希望大家给点建议!解决方案
- java.lang.SecurityException: Application not authorized to access the restricted API有关问题,
- oracle sql 有关问题