Memory Access Patterns
´ó˛ż·ÖdeviceŇ»żŞĘĽ´Óglobal Memory»ńȡĘýľÝŁ¬¶řÇŇŁ¬´ó˛ż·ÖGPUÓ¦ÓñíĎֻᱻ´řżíĎŢÖơŁŇň´Ë×î´ó»ŻÓ¦ÓöÔglobal Memory´řżíµÄĘąÓĂʱ»ńȡ¸ßĐÔÄܵĵÚŇ»˛˝ˇŁŇ˛ľÍĘÇ˵Ł¬global MemoryµÄĘąÓĂľÍĂ»µ÷˝ÚşĂŁ¬ĆäËüµÄÓĹ»Ż·˝°¸Ň˛»ńȡ˛»µ˝Ę˛Ă´´óЧąűˇŁ
Aligned and Coalesced Access
ČçĎÂÍĽËůĘľŁ¬global MemoryµÄload/storeŇŞľÓÉcacheŁ¬ËůÓеÄĘýľÝ»áłőĘĽ»ŻÔÚDRAMŁ¬Ň˛ľÍĘÇÎďŔíµÄdevice MemoryÉĎŁ¬¶řkernelÄÜą»»ńȡµÄglobal MemoryʵĽĘÉĎĘÇŇ»żéÂ߼ÄÚ´ćżŐĽäˇŁKernel¶ÔMemoryµÄÇëÇó¶ĽĘÇÓÉDRAMşÍSMµÄƬÉĎÄÚ´ćŇÔ128-byteşÍ32-byte´«Ęä˝âľöµÄˇŁ
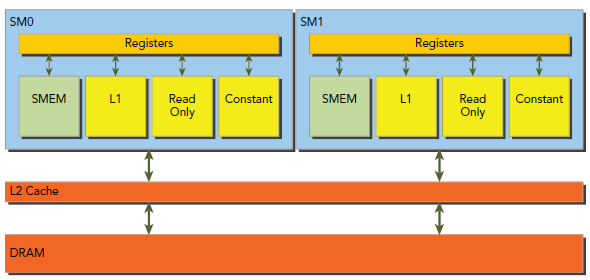
ËůÓĐ»ńȡglobal Memory¶ĽŇŞľąýL2 cacheŁ¬Ň˛ÓĐĐí¶ŕ»ąŇŞľąýL1 cacheŁ¬Ö÷ŇŞÓÉGPUµÄĽÜąąşÍ»ńȡģʽľö¶¨µÄˇŁČçąűL1şÍL2¶Ľ±»ĘąÓĂŁ¬ÄÇĂ´MemoryµÄ»ńȡĘÇŇÔ128-byteÎŞµĄÎ»´«ĘäµÄŁ¬ČçąűֻʹÓĂL2Ł¬ÔňŇÔ32-byteÎŞµĄÎ»´«Ę䣬ÔÚÔĘĐíĘąÓĂL1µÄGPUÖĐŁ¨şĂĎńMaxwellŇŃľłąµ×˛»ĘąÓĂL1Ł¬Ô±ľ×ßL1¶Ľ»»łÉ×ßtexture cacheŁ©Ł¬L1ĘÇżÉŇÔÔÚ±ŕŇëĆÚ±»ĎÔʾʹÓĂ»ň˝űÖąµÄˇŁ
ÓÉÉĎÎÄżÉÖŞŁ¬L1 cacheÖĐÿһĐĐĘÇ128bytesŁ¬ŐâĐ©ĘýľÝÓłÉäµ˝device MemoryÉϵÄ128λ¶ÔĆëµÄżéˇŁČçąűwarpÖĐĂż¸öthreadÇëÇóŇ»¸ö4-byteµÄÖµŁ¬ÄÇĂ´Ăż´ÎÇëÇó»áŇŞÇó»ńȡ128 bytesÖµŁ¬ŐýşĂĆőşĎcache line´óСşÍdevice Memory segment´óСˇŁ
Ňň´ËŁ¬ÎŇĂÇÔÚÉčĽĆ´úÂëµÄʱşňŁ¬ÓĐÁ˝¸öĚŘŐ÷ĐčҪעŇ⣺
- Aligned Memory access ¶ÔĆë
- Coalesced Memory access Á¬Đř
µ±ŇŞ»ńȡµÄMemoryĘ×µŘÖ·ĘÇcache lineµÄ±¶ĘýʱŁ¬ľÍĘÇAligned Memory AccessŁ¬ČçąűĘǷǶÔĆëµÄŁ¬ľÍ»áµĽÖÂŔË·Ń´řżíˇŁÖÁÓÚCoalesced Memory AccessÔňĘÇwarpµÄ32¸öthreadÇëÇóµÄĘÇÁ¬ĐřµÄÄÚ´ćżéˇŁ
ĎÂÍĽľÍĘǺܺõķűşĎÁËÁ¬ĐřşÍ¶ÔĆëÔÔňŁ¬Ö»ÓĐ128-byte Memory´«ĘäµÄĎűşÄŁş
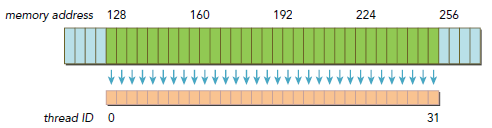
ĎÂÍĽÔňĂ»ÓĐ×ńĘŘÁ¬ĐřşÍ¶ÔĆëÔÔňŁ¬ÓĐČý´Î´«ĘäĎűşÄ·˘ÉúŁ¬Ň»´ÎĘÇ´ÓĆ«ŇƵŘÖ·0żŞĘĽŁ¬Ň»´ÎĘÇ´ÓĆ«ŇƵŘÖ·256żŞĘĽŁ¬»ąÓĐŇ»´ÎĘÇ´ÓĆ«ŇĆ128żŞĘĽŁ¬¶řŐâ´Î°üş¬Á˴󲿷ÖĐčŇŞµÄĘýľÝŁ¬ÁíÍâÁ˝´ÎÔňÓкܶŕĘýľÝ˛˘˛»ĘÇĐčŇŞµÄŁ¬¶řµĽÖ´řżíŔ˷ѡŁ
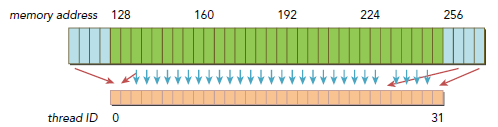
Ň»°ăŔ´˝˛Ł¬ÎŇĂÇÓ¦¸ĂŐâŃůÓĹ»Ż´«ĘäЧÂĘŁşĘąÓĂ×îÉٵĴ«Ęä´ÎĘýŔ´Âú×ă×î´óµÄ»ńȡÄÚ´ćÇëÇ󡣵±Č»Ł¬ĐčŇŞ¶ŕÉŮ´«Ę䣬¶ŕ´óµÄÍĚͶĽĘǸúCCÓйصġŁ
Global Memory Reads
ÔÚSMÖĐŁ¬ĘýľÝÔËËÍĘÇŇŞľąýĎÂĂćČýÖÖcache/bufferµÄŁ¬Ö÷ŇŞŇŔŔµÓÚŇŞ»ńȡµÄdevice MemoryÖÖŔࣺ
- L1/L2 cache
- Constant cache
- Read-only cache
L1/L2ĘÇĬČĎ·ľ¶Ł¬ÁíÍâÁ˝Ěő·ĐčŇŞÓ¦ÓĂĎÔĘľµÄ˵Ă÷Ł¬Ň»°ăŐâŃů×ö¶ĽĘÇÎŞÁËĚáÉýĐÔÄÜŁ¨Đ´CUDA´úÂëµÄʱşňŁ¬żÉŇÔĎȶĽĘąÓĂglobal MemoryŁ¬Č»şó¸ůľÝĐčŇŞÂýÂýµ÷˝ÚŁ¬ĘąÓĂһЩĚŘĘâµÄÄÚ´ćŔ´ĚáÉýĐÔÄÜŁ©ˇŁGlobal MemoryµÄload˛Ů×÷ĘÇ·ńľąýL1cacheżÉŇÔÓĐĎÂĂćÁ˝¸öŇňËŘľö¶¨Łş
- Device compute capability
- Compiler options
ĬČĎÇéżöĎÂŁ¬L1ĘDZ»żŞĆôµÄŁ¬-Xptxas -dlcm=cgżÉŇÔÓĂŔ´˝űÓĂL1ˇŁL1±»˝űÓĂşóŁ¬ËůÓĐČĄL1µÄ¶ĽÖ±˝ÓČĄL2ÁˡŁµ±L2δĂüÖĐʱŁ¬ľÍÖ±˝ÓČĄDRAMˇŁËůÓĐMemory transactionżÉÄÜÇëÇóŇ»¸öŁ¬Á˝¸ö»ňŐßËĸösegmentŁ¬Ăż¸ösegmentĘÇ32 bytesˇŁµ±Č»L1ҲżÉŇÔ±»ĎÔĘ˝µÄżŞĆô-Xptxas -dlcm=caŁ¬´ËʱŁ¬ËůÓĐMemoryÇëÇó¶ĽĎČ×ßL1Ł¬Î´ĂüÖĐÔňČĄL2ˇŁÔÚKepler K10Ł¬K20şÍK20xϵÁĐGPUŁ¬L1˛»ÔÚÓĂŔ´cache global MemoryŁ¬L1µÄΨһÓĂÍľľÍĘÇŔ´cacheÓÉÓÚregister spill·Ĺµ˝local MemoryµÄÄDzż·ÖregisterˇŁ
Cache Loads
ÎŇĂÇŇÔĬČĎżŞĆôL1ÎŞŔýŁ¬ËµĂ÷϶ÔĆëşÍÁ¬ĐřŁ¬ĎÂÍĽĘÇŔíĎëµÄÇéżöŁ¬Á¬ĐřÇҶÔĆ룬warpÖĐËůÓĐthreadµÄMemoryÇëÇó¶ĽÂäÔÚͬһżécache lineŁ¨128 bytesŁ©Ł¬Ö»ÓĐŇ»´Î´«ĘäĎűşÄŁ¬Ă»ÓĐČκζŕÓŕµÄĘýľÝ±»´«Ę䣬busĘąÓĂЧÂʰٷְ١Ł

ĎÂÍĽĘǶÔĆ뵫ĎßłĚIDşÍµŘÖ·˛»ĘÇÁ¬Đřһһ¶ÔÓ¦µÄÇéżöŁ¬˛»ąýÓÉÓÚËůÓĐĘýľÝČÔČ»ÔÚŇ»¸öÁ¬Đř¶ÔĆëµÄżéÖĐŁ¬ËůÓĐŇŔȻûÓжîÍâµÄ´«ĘäĎűşÄŁ¬ÎŇĂÇČÔȻֻĐčŇŞŇ»´Î128 bytesµÄ´«ĘäľÍÄÜÍęłÉˇŁ

ĎÂÍĽÔňĘÇ·ÇÁ¬Đřδ¶ÔĆëµÄÇéżöŁ¬ĘýľÝÂäÔÚÁËÁ˝¸ö128-byteµÄżéÖĐŁ¬ËůŇÔľÍÓĐÁ˝¸ö128-byteµÄ´«ĘäĎűşÄŁ¬¶řĆäÖĐÓĐŇ»°ëĘÇÎŢЧĘýľÝŁ¬busĘąÓĂĘÇ°Ů·ÖÖ®ÎĺĘ®ˇŁ

ĎÂÍĽĘÇ×µÄÇéżöŁ¬Í¬ŃůĘÇÇëÇó32¸ö4 bytesĘýľÝŁ¬µ«ĘÇĂż¸öµŘÖ··Ö˛ĽµÄĎŕµ±˛»ąćÂÉŁ¬ÎŇĂÇÖ»ĎëŇŞĐčŇŞµÄÄÇ128 bytesĘýľÝŁ¬µ«ĘÇŁ¬ĘµĽĘÉĎĎÂÍĽŐâŃůµÄ·Ö˛ĽŁ¬Č´ĐčŇŞN∈(0,32)¸öcache lineŁ¬Ň˛ľÍĘÇN´ÎĘýľÝ´«ĘäĎűşÄˇŁ

CPUµÄL1 cacheĘǸůľÝʱĽäşÍżŐĽäľÖ˛żĐÔ×öłöµÄÓĹ»ŻŁ¬µ«ĘÇGPUµÄL1˝ö˝ö±»ÉčĽĆłÉŐë¶ÔżŐĽäľÖ˛żĐÔ¶ř˛»°üŔ¨Ę±ĽäľÖ˛żĐÔˇŁĆµ·±µÄ»ńȡL1˛»»áµĽÖÂijЩĘýľÝפÁôÔÚcacheÖĐŁ¬Ö»ŇŞĎ´ÎÓò»µ˝Ł¬Ö±˝ÓÉľˇŁ
Uncached Loads
ŐâŔďľÍĘÇÖ¸˛»×ßL1µ«ĘÇ»ąĘÇŇŞ×ßL2Ł¬Ň˛ľÍĘÇcache line´Ó128-byte±äÎŞ32-byteÁˡŁŇŔČ»ŇÔÉĎÎÄwarp 32¸öthreadĂż¸ö4 bytesÇëÇóŁ¬×ÜĽĆ128 bytesÎŞŔýŁ¬ĎÂÍĽĘÇŔíĎëµÄ¶ÔĆëÇŇÁ¬ĐřÇéĐÎŁ¬ËůÓеÄ128 bytes¶ĽÂäÔÚËÄżé32 bytesµÄżéÖСŁ

ĎÂÍĽÇëÇóĂ»ÓжÔĆ룬ÇëÇóÂäÔÚÁË160-byte·¶Î§ÄÚŁ¬busÓĐЧʹÓĂÂĘĘÇ°Ů·ÖÖ®°ËĘ®Ł¬Ďŕ¶ÔĘąÓĂL1Ł¬ĐÔÄÜŇŞşĂ˛»É١Ł

ĎÂÍĽĘÇËůÓĐthread¶ĽÇëÇóͬһżéĘýľÝµÄÇéĐÎŁ¬busÓĐЧʹÓĂÂĘÎŞ4bytes/32bytes=12.5%Ł¬ŇŔȻҪ±ČL1±íĎֺáŁ

ĎÂÍĽĘÇÇéżö×îÔă¸âµÄŁ¬ĘýľÝ·ÇłŁ·ÖɢŁ¬µ«ĘÇÓÉÓÚËůÇëÇóµÄ128 bytesÂäÔÚÁ˶ŕ¸öŇÔ32 bytesÎŞµĄÎ»µÄsegmentÖĐŁ¬Ňň´ËÎŢЧµÄĘýľÝ´«ĘäŇŞÉٵĶࡣ

Example of Misaligned Reads
ÄÚ´ć»ńȡģʽһ°ă¶ĽĘÇÓĐÓ¦ÓõÄʵĎÖşÍËă·¨Ŕ´ľö¶¨µÄŁ¬Ň»Đ©ÇéżöĎÂŁ¬ŇŞÂú×ăÁ¬ĐřÄÚ´ćĘÇ·ÇłŁÄѵġŁµ«ĘǶÔÓÚ¶ÔĆëŔ´ËµŁ¬ĘÇÓĐһЩ·˝·¨Ŕ´°ďÖúÓ¦ÓĂʵĎֵġŁ
ĎÂĂćŇÔ´úÂëŔ´ĽěŃéÉĎĘö֪ʶŁ¬kernelÖжŕÁËŇ»¸ökË÷ŇýŁ¬ĘÇÓĂŔ´ĹäÖĂĆ«ŇƵŘÖ·µÄŁ¬Í¨ąýËűľÍżÉŇÔĹäÖöÔĆëÇéżöŁ¬Ö»ÓĐÔÚloadÁ˝¸öĘý×éAşÍBʱ˛Ĺ»áĘąÓĂkˇŁ¶ÔCµÄĐ´˛Ů×÷ÔňĽĚĐřĘąÓĂÔŔ´µÄ´úÂ룬´Ó¶ř±ŁÖ¤Đ´˛Ů×÷ ±ŁłÖşÜşĂµÄ¶ÔĆ롣
__global__ void readOffset(float *A, float *B, float *C, const int n,int offset) { unsigned int i = blockIdx.x * blockDim.x + threadIdx.x; unsigned int k = i + offset; if (k < n) C[i] = A[k] + B[k];}
ĎÂĂćĘÇmain´úÂ룬offsetĬČĎĘÇÁ㣺


int main(int argc, char **argv) {// set up deviceint dev = 0;cudaDeviceProp deviceProp;cudaGetDeviceProperties(&deviceProp, dev);printf("%s starting reduction at ", argv[0]);printf("device %d: %s ", dev, deviceProp.name);cudaSetDevice(dev);// set up array sizeint nElem = 1<<20; // total number of elements to reduceprintf(" with array size %d\n", nElem);size_t nBytes = nElem * sizeof(float);// set up offset for summaryint blocksize = 512;int offset = 0;if (argc>1) offset = atoi(argv[1]);if (argc>2) blocksize = atoi(argv[2]);// execution configurationdim3 block (blocksize,1);dim3 grid ((nElem+block.x-1)/block.x,1);// allocate host memoryfloat *h_A = (float *)malloc(nBytes);float *h_B = (float *)malloc(nBytes);float *hostRef = (float *)malloc(nBytes);float *gpuRef = (float *)malloc(nBytes);// initialize host arrayinitialData(h_A, nElem);memcpy(h_B,h_A,nBytes);// summary at host sidesumArraysOnHost(h_A, h_B, hostRef,nElem,offset);// allocate device memoryfloat *d_A,*d_B,*d_C;cudaMalloc((float**)&d_A, nBytes);cudaMalloc((float**)&d_B, nBytes);cudaMalloc((float**)&d_C, nBytes);// copy data from host to devicecudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice);cudaMemcpy(d_B, h_A, nBytes, cudaMemcpyHostToDevice);// kernel 1:double iStart = seconds();warmup <<< grid, block >>> (d_A, d_B, d_C, nElem, offset);cudaDeviceSynchronize();double iElaps = seconds() - iStart;printf("warmup <<< %4d, %4d >>> offset %4d elapsed %f sec\n",grid.x, block.x,offset, iElaps);iStart = seconds();readOffset <<< grid, block >>> (d_A, d_B, d_C, nElem, offset);cudaDeviceSynchronize();iElaps = seconds() - iStart;printf("readOffset <<< %4d, %4d >>> offset %4d elapsed %f sec\n",grid.x, block.x,offset, iElaps);// copy kernel result back to host side and check device resultscudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost);checkResult(hostRef, gpuRef, nElem-offset);// copy kernel result back to host side and check device resultscudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost);checkResult(hostRef, gpuRef, nElem-offset);// copy kernel result back to host side and check device resultscudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost);checkResult(hostRef, gpuRef, nElem-offset);// free host and device memorycudaFree(d_A);cudaFree(d_B);cudaFree(d_C);free(h_A);free(h_B);// reset devicecudaDeviceReset();return EXIT_SUCCESS;}
±ŕŇëÔËĐĐŁş
$ nvcc -O3 -arch=sm_20 readSegment.cu -o readSegment$ ./readSegment 0readOffset <<< 32768, 512 >>> offset 0 elapsed 0.001820 sec$ ./readSegment 11readOffset <<< 32768, 512 >>> offset 11 elapsed 0.001949 sec$ ./readSegment 128readOffset <<< 32768, 512 >>> offset 128 elapsed 0.001821 sec
µ±offset=11ʱŁ¬»áµĽÖ´ÓAşÍB loadĘýľÝʱ˛»¶ÔĆ롣ĆäÔËĐĐʱĽäĎűşÄҲĘÇ×î´óµÄŁ¬ÎŇĂÇżÉŇÔĘąÓĂnvccµÄgld_efficiencyŔ´ĽěŃéŇ»ĎÂŁş
$ nvprof --devices 0 --metrics gld_transactions ./readSegment 0$ nvprof --devices 0 --metrics gld_transactions ./readSegment 11$ nvprof --devices 0 --metrics gld_transactions ./readSegment 128
ĘäłöŁş
Offset 0: gld_efficiency 100.00%Offset 11: gld_efficiency 49.81%Offset 128: gld_efficiency 100.00%
żÉŇÔż´µ˝offset=11ʱŁ¬Đ§ÂĘĽő°ëŁ¬żÉŇÔÔ¤ĽűĆäÍĚͱŘČ»şÜ¸ßŁ¬Ň˛żÉŇÔĘąÓĂgld_transactionsŔ´ĽěŃ飺
$ nvprof --devices 0 --metrics gld_transactions ./readSegment $OFFSETĘäłöÎŞŁş
Offset 0: gld_transactions 65184Offset 11: gld_transactions 131039Offset 128: gld_transactions 65744
Č»şóÎŇĂÇĘąÓĂ-Xptxas -dlcm=cgŔ´˝űÓĂL1Ł¬ż´Ň»ĎÂÖ±˝ÓĘąÓĂL2µÄ±íĎÖŁş
$ ./readSegment 0readOffset <<< 32768, 512 >>> offset 0 elapsed 0.001825 sec$ ./readSegment 11readOffset <<< 32768, 512 >>> offset 11 elapsed 0.002309 sec$ ./readSegment 128readOffset <<< 32768, 512 >>> offset 128 elapsed 0.001823 sec
´Ó¸Ă˝áąűż´łöŁ¬Î´¶ÔĆëµÄÇéżö¸üÔă¸âÁËŁ¬Č»şóż´ĎÂgld_efficiencyŁş
Offset 0: gld_efficiency 100.00%Offset 11: gld_efficiency 80.00%Offset 128: gld_efficiency 100.00%
ŇňÎŞL1±»˝űÓĂşóŁ¬Ăż´Îload˛Ů×÷¶ĽĘÇŇÔ32-byteÎŞµĄÎ»¶ř˛»ĘÇ128Ł¬ËůŇÔÎŢÓĂĘýľÝ»áĽőÉŮ·ÇłŁ¶ŕˇŁ
ŐâŔďδ¶ÔĆë·´¶řÇéżö±äÔăĘÇŇ»ÖÖĚŘŔýŁ¬¸ßOccupancyÇéżöĎÂŁ¬uncached»á°ďÖúĚáÉýbusÓĐЧʹÓĂÂĘŁ¬¶ř¶ÔÓÚδ¶ÔĆëµÄÇéżöŁ¬ÎŢÓĂĘýľÝµÄ´«Ę佫Ă÷ĎÔĽőÉ١Ł
Read-Only Cache
×ʼŁ¬read-only cacheĘÇÓĂŔ´ÎŞtexture Memory load·ţÎńµÄŁ¬¶ÔÓÚCC3.5ŇÔÉĎŁ¬¸ĂcacheżÉŇÔĚć»»L1ˇŁRead-only cacheµÄµĄÎ»ĘÇ32 bytesŁ¬Ň»°ăŔ´˝˛ĘDZČL1ŇŞşĂÓõöࡣ
ÓĐÁ˝ÖÖ·˝Ę˝Ŕ´ĘąÓĂread-only cacheŁş
- Using the function __ldg
- Using a declaration qualifier on the pointer being dereferenced
ŔýČ磺
__global__ void copyKernel(int *out, int *in) { int idx = blockIdx.x * blockDim.x + threadIdx.x; out[idx] = in[idx];}
¸ÄĐ´şóŁş
__global__ void copyKernel(int *out, int *in) { int idx = blockIdx.x * blockDim.x + threadIdx.x; out[idx] = __ldg(&in[idx]);}
»ňŐßĘąÓĂ const __restrict__Ŕ´ĐŢĘÎÖ¸Ő롣¸ĂĐŢĘηű°ďÖúnvcc±ŕŇëĆ÷ʶ±đnon-aliasedÖ¸Ő룬nvcc»á×Ô¶ŻĘąÓøĂnon-alias Ö¸Őë´Óread-cache¶ÁłöĘýľÝˇŁ
__global__ void copyKernel(int * __restrict__ out,const int * __restrict__ in) { int idx = blockIdx.x * blockDim.x + threadIdx.x; out[idx] = in[idx];}
Global Memory Writes
Đ´˛Ů×÷Ďŕ¶ÔŇŞĽňµĄµÄ¶ŕŁ¬L1Ńą¸ůľÍ˛»ĘąÓĂÁˡŁĘýľÝÖ»»ácacheÔÚL2ÖĐŁ¬ËůŇÔĐ´˛Ů×÷ҲĘÇŇÔ32bytesÎŞµĄÎ»µÄˇŁMemory transactionŇ»´ÎżÉŇÔĘÇŇ»¸öˇ˘Á˝¸ö»ňËĸösegmentˇŁŔýČ磬ČçąűÁ˝¸öµŘÖ·ÂäÔÚÁËͬһ¸ö128-byteµÄÇřÓňÄÚŁ¬µ«ĘÇÔÚ˛»Í¬µÄÁ˝¸ö64-byte¶ÔĆëµÄÇřÓňŁ¬Ň»¸öËĸösegmentµÄtransactionľÍ»á±»Ö´ĐĐŁ¨Ň˛ľÍĘÇ˵Ł¬Ň»¸öµĄ¶ŔµÄ4-segmentµÄ´«ĘäŇŞ±ČÁ˝´Î1-segmentµÄ´«ĘäĐÔÄܺã©ˇŁ
ĎÂÍĽĘÇŇ»¸öŔíĎëµÄÇéżöŁ¬Á¬ĐřÇҶÔĆ룬ֻĐčŇŞŇ»´Î4 segmentµÄ´«Ę䣺

ĎÂÍĽĘÇŔëɢµÄÇéżöŁ¬»áÓÉČý´Î1-segment´«ĘäÍęłÉˇŁ

ĎÂÍĽĘǶÔĆëÇҵŘÖ·ÔÚŇ»¸öÁ¬ĐřµÄ64-byte·¶Î§ÄÚµÄÇéżöŁ¬ÓÉŇ»´Î2-segment´«ĘäÍęłÉŁş

Example of Misaligned Writes
ÔŮ´ÎĐ޸ĴúÂ룬load±ä»ŘĘąÓĂiŁ¬¶ř¶ÔCµÄĐ´ÔňĘąÓĂkŁş
__global__ void writeOffset(float *A, float *B, float *C,const int n, int offset) { unsigned int i = blockIdx.x * blockDim.x + threadIdx.x; unsigned int k = i + offset; if (k < n) C[k] = A[i] + B[i];}
Đ޸ÄhostµÄĽĆË㺯Ęý;
void sumArraysOnHost(float *A, float *B, float *C, const int n,int offset) { for (int idx = offset, k = 0; idx < n; idx++, k++) { C[idx] = A[k] + B[k]; }}
±ŕŇëÔËĐĐŁş
$ nvcc -O3 -arch=sm_20 writeSegment.cu -o writeSegment$ ./writeSegment 0writeOffset <<< 2048, 512 >>> offset 0 elapsed 0.000134 sec$ ./writeSegment 11writeOffset <<< 2048, 512 >>> offset 11 elapsed 0.000184 sec$ ./writeSegment 128writeOffset <<< 2048, 512 >>> offset 128 elapsed 0.000134 sec
ĎÔ¶řŇ׼űŁ¬Misaligned±íĎÖ×î˛îŁ¬Č»şó˛éż´gld_efficiencyŁş
$ nvprof --devices 0 --metrics gld_efficiency --metrics gst_efficiency ./writeSegment $OFFSETwriteOffset Offset 0: gld_efficiency 100.00%writeOffset Offset 0: gst_efficiency 100.00%writeOffset Offset 11: gld_efficiency 100.00%writeOffset Offset 11: gst_efficiency 80.00%writeOffset Offset 128: gld_efficiency 100.00%writeOffset Offset 128: gst_efficiency 100.00%
łýÁËoffset=11µÄstoreÍ⣬ËůÓĐloadşÍstore¶ĽĘǰٷְ١Łµ±offset=11ʱŁ¬128-bytesµÄĐ´ÇëÇó»á±»Ň»¸ö4-segmentşÍŇ»¸ö1-segmentµÄ´«Ęä·ţÎńŁ¬Ňň´ËŁ¬ÎŇĂÇËäČ»ĐčŇŞĐ´128bytesµ«ĘÇČ´ÓĐ160bytesĘýľÝ±»loadŁ¬´Ó¶řµĽÖ°ٷÖÖ®°ËĘ®µÄЧÂʡŁ
Array of Structure versus Structure of Arrays
×÷ÎŞCłĚĐňÔ±Ł¬ÎŇĂÇÓ¦¸ĂĘěϤÁ˝ÖÖ×éÖŻĘýľÝµÄ·˝Ę˝Łşarray of structuresŁ¨AoSŁ©şÍstructure of arraysŁ¨SoAŁ©ˇŁ¶ţŐßµÄĘąÓĂĘÇŇ»¸öÓĐȤµÄ»°Ě⣬Ö÷ŇŞĘÇĘýľÝĹĹÁĐ×éÖŻˇŁ
ąŰ˛ěĎÂĂć´úÂ룬Ę×ĎČżĽÂǸĂĘýľÝ˝áąąĽŻşĎÔÚĘąÓĂAoS×é֯ʱŁ¬ĘÇÔőŃů´ć´˘µÄŁş
struct innerStruct { float x; float y;};struct innerStruct myAoS[N]; //ÿһ¶ÔxşÍyµÄ´ć´˘Ł¬żŐĽäÉĎĘÇÁ¬ĐřµÄ
Č»şóĘÇSoAŁş
struct innerArray { float x[N]; float y[N];};struct innerArray moa; //xşÍyĘÇ·Ö±đ´ć´˘µÄŁ¬ËůÓĐxşÍyĘÇ·Ö±đ´ć´˘ÔÚÁ˝¶Î˛»Í¬µÄÁ¬ĐřµŘÖ·Ŕ
ĎÂÍĽĎÔĘľÁËAoSşÍSoAÔÚÄÚ´ćÖеĴ洢¸ńĘ˝Ł¬µ±¶Ôx˝řĐвŮ×÷ʱŁ¬»áµĽÖÂŇ»°ăµÄ´řżíŔË·ŃŁ¬ŇňÎŞÔÚ˛Ů×÷xʱŁ¬yҲ»áŇţĘ˝µÄ±»loadŁ¬¶řSoAµÄ±íĎÖľÍŇŞşĂµĂ¶ŕŁ¬ŇňÎŞËůÓĐx¶ĽĘÇĎŕÁڵġŁ
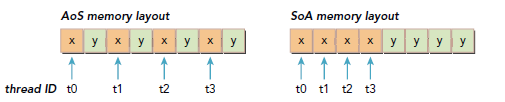
Đí¶ŕ˛˘ĐбŕłĚąć·¶ŔĚرđĘÇSIMD-style·ç¸ńµÄąć·¶Ł¬¶Ľ¸üÇăĎňÓÚĘąÓĂSoAŁ¬ÔÚCUDA CŔSoAҲĘÇ·ÇłŁ˝¨ŇéĘąÓõģ¬ŇňÎŞĘýľÝŇŃľÔ¤ĎČĹĹĐňÁ¬ĐřÁˡŁ
ExampleŁşSimple Math with the AoS Data Layout
__global__ void testInnerStruct(innerStruct *data,innerStruct *result, const int n) { unsigned int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < n) { innerStruct tmp = data[i]; tmp.x += 10.f; tmp.y += 20.f; result[i] = tmp; }}
ĘäČ볤¶ČĘÇ1MŁ¬#define LEN 1<<20ˇŁ
łőĘĽ»ŻĘýľÝŁş
void initialInnerStruct(innerStruct *ip, int size) { for (int i = 0; i < size; i++) { ip[i].x = (float)(rand() & 0xFF) / 100.0f; ip[i].y = (float)(rand() & 0xFF) / 100.0f; } return;}
Main´úÂ룺
int main(int argc, char **argv) {// set up deviceint dev = 0;cudaDeviceProp deviceProp;cudaGetDeviceProperties(&deviceProp, dev);printf("%s test struct of array at ", argv[0]);printf("device %d: %s \n", dev, deviceProp.name);cudaSetDevice(dev);// allocate host memoryint nElem = LEN;size_t nBytes = nElem * sizeof(innerStruct);innerStruct *h_A = (innerStruct *)malloc(nBytes);innerStruct *hostRef = (innerStruct *)malloc(nBytes);innerStruct *gpuRef = (innerStruct *)malloc(nBytes);// initialize host arrayinitialInnerStruct(h_A, nElem);testInnerStructHost(h_A, hostRef,nElem);// allocate device memoryinnerStruct *d_A,*d_C;cudaMalloc((innerStruct**)&d_A, nBytes);cudaMalloc((innerStruct**)&d_C, nBytes);// copy data from host to devicecudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice);// set up offset for summaryint blocksize = 128;if (argc>1) blocksize = atoi(argv[1]);// execution configurationdim3 block (blocksize,1);dim3 grid ((nElem+block.x-1)/block.x,1);// kernel 1: warmupdouble iStart = seconds();warmup <<< grid, block >>> (d_A, d_C, nElem);cudaDeviceSynchronize();double iElaps = seconds() - iStart;printf("warmup <<< %3d, %3d >>> elapsed %f sec\n",grid.x,block.x,iElaps);cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost);checkInnerStruct(hostRef, gpuRef, nElem);// kernel 2: testInnerStructiStart = seconds();testInnerStruct <<< grid, block >>> (d_A, d_C, nElem);cudaDeviceSynchronize();iElaps = seconds() - iStart;printf("innerstruct <<< %3d, %3d >>> elapsed %f sec\n",grid.x,block.x,iElaps);cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost);checkInnerStruct(hostRef, gpuRef, nElem);// free memories both host and devicecudaFree(d_A);cudaFree(d_C);free(h_A);free(hostRef);free(gpuRef);// reset devicecudaDeviceReset();return EXIT_SUCCESS;}
±ŕŇëÔËĐĐ(Fermi M2070)Łş
$ nvcc -O3 -arch=sm_20 simpleMathAoS.cu -o simpleMathAoS$ ./simpleMathAoSinnerStruct <<< 8192, 128 >>> elapsed 0.000286 sec
˛éż´loadşÍstoreĐÔÄÜŁş
$ nvprof --devices 0 --metrics gld_efficiency,gst_efficiency ./simpleMathAoSgld_efficiency 50.00%gst_efficiency 50.00%
ŐýČçÔ¤ĆÚÄÇŃůŁ¬¶ĽÖ»´ďµ˝ÁËŇ»°ăŁ¬ŇňÎŞ¶îÍâÄDzż·ÖĎűşÄ¶ĽÓĂŔ´load/store ÁíŇ»¸öÔŞËŘÁËŁ¬¶řŐⲿ·Ö˛»ĘÇÎŇĂÇĐčŇŞµÄˇŁ
ExampleŁşSimple Math with the SoA Data Layout
__global__ void testInnerArray(InnerArray *data,InnerArray *result, const int n) { unsigned int i = blockIdx.x * blockDim.x + threadIdx.x; if (i<n) { float tmpx = data->x[i]; float tmpy = data->y[i]; tmpx += 10.f; tmpy += 20.f; result->x[i] = tmpx; result->y[i] = tmpy; }}
·ÖĹäglobal MemoryŁş
int nElem = LEN;size_t nBytes = sizeof(InnerArray);InnerArray *d_A,*d_C;cudaMalloc((InnerArray **)&d_A, nBytes);cudaMalloc((InnerArray **)&d_C, nBytes);
±ŕŇëÔËĐĐŁş
$ nvcc -O3 -arch=sm_20 simpleMathSoA.cu -o simpleSoA$ ./simpleSoAinnerArray <<< 8192, 128 >>> elapsed 0.000200 sec
˛éż´load/storeĐÔÄÜŁş
$ nvprof --devices 0 --metrics gld_efficiency,gst_efficiency ./simpleMathSoAgld_efficiency 100.00%gst_efficiency 100.00%
Performance Tuning
µ÷˝Údevice Memory´řżíŔűÓĂĐÔÄÜʱŁ¬Ö÷ŇŞĘÇÁ¦Çó´ďµ˝ĎÂĂćÁ˝¸öÄż±ęŁş
- Aligned and Coalesced Memory accesses that reduce wasted bandwidth
- Sufficient concurrent Memory operations to hide Memory latency
Unrolling Techniques
ŐążŞŃ»·żÉŇÔÔöĽÓ¸ü¶ŕµÄ¶ŔÁ˘µÄMemory˛Ů×÷Ł¬ÎŇĂÇÔÚ֮ǰ˛©ÎÄÓĐĎęϸ˝éÉÜČçşÎŐążŞloopŁ¬żĽÂÇ֮ǰµÄredSegmentµÄŔý×ÓŁ¬ÎŇĂÇĐ޸ÄĎÂreadOffsetŔ´ĘąĂż¸öthreadÖ´ĐĐËĸö¶ŔÁ˘Memory˛Ů×÷Ł¬ľÍĎńĎÂĂćÄÇŃůŁş
__global__ void readOffsetUnroll4(float *A, float *B, float *C,const int n, int offset) { unsigned int i = blockIdx.x * blockDim.x * 4 + threadIdx.x; unsigned int k = i + offset; if (k + 3 * blockDim.x < n) { C[i] = A[k] C[i + blockDim.x] = A[k + blockDim.x] + B[k + blockDim.x]; C[i + 2 * blockDim.x] = A[k + 2 * blockDim.x] + B[k + 2 * blockDim.x]; C[i + 3 * blockDim.x] = A[k + 3 * blockDim.x] + B[k + 3 * blockDim.x]; }}
±ŕŇëÔËĐĐŁ¨żÉÄÜĐčŇŞĘąÓĂ-Xptxas -dlcm=caŔ´ĆôÓĂL1Ł©Łş
$ ./readSegmentUnroll 0warmup <<< 32768, 512 >>> offset 0 elapsed 0.001990 secunroll4 <<< 8192, 512 >>> offset 0 elapsed 0.000599 sec$ ./readSegmentUnroll 11warmup <<< 32768, 512 >>> offset 11 elapsed 0.002114 secunroll4 <<< 8192, 512 >>> offset 11 elapsed 0.000615 sec$ ./readSegmentUnroll 128warmup <<< 32768, 512 >>> offset 128 elapsed 0.001989 secunroll4 <<< 8192, 512 >>> offset 128 elapsed 0.000598 sec
ÎŇĂÇż´µ˝Ł¬unrollingĽĽĘő»á¶ÔĐÔÄÜÓо޴óÓ°Ď죬±ČµŘÖ·¶ÔĆëÓ°Ď컹´óˇŁ¶ÔÓÚŐâŔŕI/O-boundµÄkernelŁ¬Ěá¸ßÄÚ´ć»ńȡµÄ˛˘ĐĐĐÔ¶ÔĐÔÄÜĚáÉýµÄÓ°Ď죬Óиü¸ßµÄÓĹĎČĽ¶ˇŁ˛»ąýŁ¬ÎŇĂÇÓ¦¸Ăż´µ˝Ł¬¶ÔĆëµÄtest±Čδ¶ÔĆëµÄtest±íĎÖŇŔȻҪşĂˇŁ
Unrolling˛˘˛»ÄÜÓ°ĎěÄÚ´ć˛Ů×÷µÄ×ÜĘýÄżŁ¨Ö»ĘÇÓ°Ď첢ĐеIJŮ×÷ĘýÄżŁ©Ł¬ÎŇĂÇżÉŇԲ鿴ĎÂĎŕąŘĘôĐÔŁş
$ nvprof --devices 0 --metrics gld_efficiency,gst_efficiency ./readSegmentUnroll 11readOffset gld_efficiency 49.69%readOffset gst_efficiency 100.00%readOffsetUnroll4 gld_efficiency 50.79%readOffsetUnroll4 gst_efficiency 100.00%$ nvprof --devices 0 --metrics gld_transactions,gst_transactions./readSegmentUnroll 11readOffset gld_transactions 132384readOffset gst_transactions 32928readOffsetUnroll4 gld_transactions 33152readOffsetUnroll4 gst_transactions 8064
Exposing More Parallelism
Őâ·˝ĂćľÍĘǵ÷ŐűgridşÍblockµÄĹäÖĂŁ¬ĎÂĂćĘÇĽÓÉĎunrollingşóµÄ˝áąűŁş
$ ./readSegmentUnroll 0 1024 22unroll4 <<< 1024, 1024 >>> offset 0 elapsed 0.000169 sec$ ./readSegmentUnroll 0 512 22unroll4 <<< 2048, 512 >>> offset 0 elapsed 0.000159 sec$ ./readSegmentUnroll 0 256 22unroll4 <<< 4096, 256 >>> offset 0 elapsed 0.000157 sec$ ./readSegmentUnroll 0 128 22unroll4 <<< 8192, 128 >>> offset 0 elapsed 0.000158 sec
±íĎÖ×îşĂµÄĘÇblockĹäÖĂ256 threadµÄkernelŁ¬ËäČ»128thread»áÔöĽÓ˛˘ĐĐĐÔŁ¬µ«ĘÇŇŔČ»±Č256ÉŮÄÇĂ´Ň»µăµăĐÔÄÜŁ¬Őâ¸öÖ÷ŇŞĘÇCC°ć±ľ¶ÔÓ¦µÄ×ĘÔ´ĎŢÖĆľö¶¨µÄŁ¬ŇÔ±ľ´úÂëÎŞŔýŁ¬FermiĂż¸öSM×î¶ŕÓĐ8¸öblockŁ¬Ăż¸öSMÄÜą»˛˘ĐеĵÄwarpĘÇ48¸öŁ¬µ±ĘąÓĂ128¸öthreadŁ¨per blockŁ©Ę±Ł¬Ăż¸öblockÖĐÓĐ4¸öwarpŁ¬ŇňÎŞĂż¸öSM×î¶ŕ8¸öblockÄÜą»Í¬Ę±ÔËĐĐŁ¬Ňň´Ë¸ĂkernelĂż¸öSM×î¶ŕÖ»ÄÜÓĐ32¸öwarpŁ¬»ąÓĐ16¸öwarpµÄĽĆËăĐÔÄÜĂ»ÓĂÉĎŁ¬ËůŇÔĐÔÄܲîÁ˾ͣ¬żÉŇÔĘąÓĂOccupancyŔ´ŃéÖ¤Ď¡Ł
˛ÎżĽĘ飺ˇ¶professional cuda c programmingˇ·