Memory
kernel���ܸߵ��Dz��ܵ����Ĵ�warp��ִ���������͵ġ�����֮ǰ�����漰���ģ���block��ά������Ϊwarp��С��һ��ᵼ��load efficiency���ͣ������������warp�ĵ��Ȼ��߲����������͡�����ԭ���ǻ�ȡglobal memory�ķ�ʽ�ܲ��
������֪��memory�IJ����ڽ���Ч�ʵ�������ռ�м��صĵ�λ��low-latency��high-bandwidth�Ǹ����ܵ�������������ǹ���ӵ�д������������ܵ�memory�Dz���ʵ�ģ����߲����õġ���ˣ����Ǿ�Ҫ��������������������ȡ����latency��bandwidth��CUDA��memory model unit��Ϊdevice��host����ϵͳ����ֱ�¶�����ڴ�ṹ�Թ����Dz����������û������ʹ������ԡ�
Benefits of a Memory Hierarchy
һ����˵�������ȡ��Դ���й��ɵģ�Ҳ���Ǽ������ϵ�ṹ�����ᵽ�ľֲ�ԭ�����ַ�Ϊʱ��ֲ��ԺͿռ�ֲ��ԡ� ���Ŵ�ҶԼ�����ڴ淽���֪ʶ������Ϥ�ˣ�����Ͳ���˵�ˣ�ֻ�����¡�
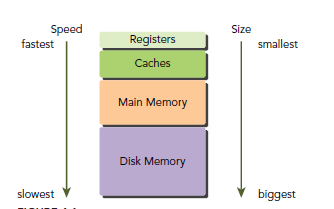
GPU��CPU�����涼����DRAMʵ�֣�cache������lower-latency��SRAM��ʵ�֡�GPU��CPU�Ĵ洢�ṹ����һ��������CUDA��memory�ṹ���õij��ָ��û����Ӷ��ܸ����Ŀ��Ƴ�����Ϊ��
CUDA Memory Model
���ڳ���Ա��˵��memory���Է�Ϊ�������ࣺ
- Programmable�����ǿ����������IJ��֡�
- Non-programmable�����ܲ�������һ���Զ��������ﵽ�ܺõ����ܡ�
��CPU�Ĵ洢�ṹ�У�L1��L2 cache����non-programmable�ġ�����CUDA��˵��programmable�����ͺܷḻ��
- Registers
- Shared memory
- Local memory
- Constant memory
- Texture memory
- Global memory
��ͼչʾ��memory�Ľṹ�����Ǹ��Զ��в��õĿռ䡢�����ں�cache��
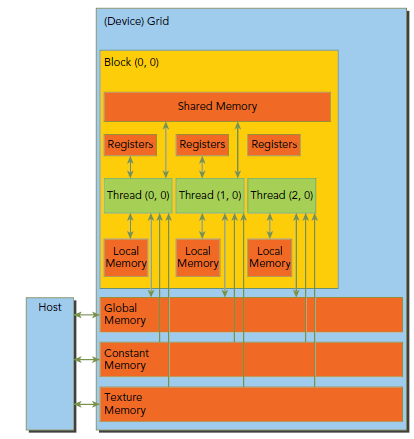
����constant��texture��ֻ���ġ�������������global��constant��textureӵ����ͬ���������ڡ�
Registers
�Ĵ�����GPU����memory��kernel��û��ʲô�����������Զ��������Ƿ��ڼĴ����еġ��������������constant�������ڱ������ܱ�ȷ���Ļ��������������ͣ�����Ҳ�Ƿ��ڼĴ����С�
�Ĵ���������ÿ���߳�˽�еģ�һ��threadִ�н������Ĵ��������ͻ�ʧЧ���Ĵ�����ϡ����Դ����Fermi�ϣ�ÿ��thread�������ӵ��63��register��Kepler����255�������Լ���kernelʹ�ý��ٵ�register���ܹ����������blockפ����SM�У�Ҳ��������Occupancy�����������ܡ�
ʹ��nvcc��-Xptxas -v,-abi=no������Xptxas��ʾ�����Ҫ����ptx�IJ���������nvcc�ģ�v��verbose��abi���ˣ�������application by interface��ѡ����Բ鿴ÿ��threadʹ�õļĴ���������shared memory��constant memory�Ĵ�С�����kernelʹ�õ�register����Ӳ�����ƣ��ⲿ�ֻ�ʹ��local memory������register������ν��register spilling������Ӧ�þ��������������������������Ӧ��������С��register��ʹ�ò��ұ���register spilling������Ҳ�����ڴ�������ʽ�ļ��϶������Ϣ���������������Ż���
__global__ void__launch_bounds__(maxThreadsPerBlock, minBlocksPerMultiprocessor)kernel(...) { // your kernel body}
maxThreadsPerBlockָ��ÿ��block�����������thread��Ŀ��minBlocksPerMultiprocessor�ǿ�ѡ�IJ�����ָ����Ҫ�����ٵ�block��Ŀ��
����Ҳ����ʹ��-maxrregcount=32��ָ��kernelʹ�õ�register�����Ŀ�����ʹ����__launch_bounds__��������ָ����32��ʧЧ��
Local Memory
��ʱ�����register�������ˣ���ô�ͻ�ʹ��local memory�������ⲿ�ּĴ����ռ䡣�����⣬���漸����������������ܻ�ѱ���������local memory��
- ������������ȷ��ֵ�ı������顣
- �ϴ�Ľṹ��������飬Ҳ������Щ���ܻ����Ĵ���register�ı�����
- �κγ����Ĵ������Ƶı�����
local memory���������������ģ���local memory�еı��������ϸ�global memory��ͬһ��洢�������ԣ�local memory�кܸߵ�latency�ͽϵ͵�bandwidth����CC2.0���ϣ�GPU���local memory����L1��per-SM����L2��per-device������cache��
Shared Memory
��__shared__���η����εı��������shared memory����Ϊshared memory��on-chip�ģ������localMemory��global memory��˵��ӵ�иߵĶ�bandwidth�͵ͺܶ��latency������ʹ�ú�CPU��L1cache�dz����ƣ���������programmable�ġ�
��������������������ô�õ�memory���������Ƶģ�shared memory����blockΪ��λ����ġ����DZ���dz�С�ĵ�ʹ��shared memory�����������ʶ��������active warp����Ŀ��
��ͬ��register��shared memory������kernel�������ģ������������������ǰ�������block�������ǵ���thread������blockִ����ϣ�����ӵ�е���Դ�ͻᱻ�ͷţ����·�������block��
shared memory��thread�����Ļ�����ʽ��ͬһ��block�е�threadͨ��shared memory�е����������������ȡshared memory������ǰ��������__syncthreads()ͬ����L1 cache��shared memoryʹ����ͬ��64KB on-chip memory������Ҳ����ʹ�������API����̬���ö��ߣ�
cudaError_t cudaFuncSetCacheConfig(const void* func, enum cudaFuncCachecacheConfig);
func�Ƿ�����ԣ�����ʹ�����漸�֣�
cudaFuncCachePreferNone: no preference (default)
cudaFuncCachePreferShared: prefer 48KB shared memory and 16KB L1 cache
cudaFuncCachePreferL1: prefer 48KB L1 cache and 16KB shared memory
cudaFuncCachePreferEqual: Prefer equal size of L1 cache and shared memory, both 32KB
Fermi��֧��ǰ�������ã�Kepler֧��ȫ����
Constant Memory
Constant Memoryפ����device Memory������ʹ��ר�õ�constant cache��per-SM������Memory������Ӧ����__connstant__���Ρ�constant�ķ�Χ��ȫ�ֵģ��������kernel����������CC���С����64KB����ͬһ�����뵥Ԫ��constant������kernel�ɼ���
kernelֻ�ܴ�constant Memory��ȡ���ݣ�������ʼ��������host��ʹ�������function���ã�
cudaError_t cudaMemcpyToSymbol(const void* symbol, const void* src,size_t count);
���function����srcָ���count��byte��symbol�ĵ�ַ��symbolָ�������device�е�global����constant Memory��
��һ��warp������thread����ͬһ��Memory��ַ��ȡ����ʱ��constant Memory������á����磬���㹫ʽ�е�ϵ����������е�thread�Ӳ�ͬ�ĵ�ַ��ȡ���ݣ�����ֻ��һ�Σ���ôconstant Memory�Ͳ��Ǻܺõ�ѡ����Ϊһ�ζ�constant Memory������㲥������thread֪����
Texture Memory
texture Memoryפ����device Memory�У�����ʹ��һ��ֻ��cache��per-SM����texture Memoryʵ����Ҳ��global Memory��һ�飬���������Լ�ר�е�ֻ��cache�����cache�ڸ�����������ã����廹ûŪ������texture Memory�����2D�ռ�ֲ��Ե��Ż����ԣ�����threadҪ��ȡ2D���ݾͿ���ʹ��texture Memory���ﵽ�ܸߵ����ܣ�D3D�������������Ҫ�Ļ����洢�ռ䣬����һ������texture��
Global Memory
global Memory�ǿռ����latency��ߣ�GPU�������memory��“global”ָ�������������ڡ�����SM������������������������л�ȡ��״̬��global�еı����ȿ����Ǿ�̬Ҳ�����Ƕ�̬����������ʹ��__device__���η����������ԡ�global memory�ķ������֮ǰƵ��ʹ�õ�cudaMalloc���ͷ�ʹ��cudaFree��global memoryפ����devicememory������ͨ��32-byte��64-byte����128-byte���ָ�ʽ���䡣��Щmemory transaction�����Ƕ���ģ�Ҳ����˵��ַ������32��64����128�ı������Ż�memory transaction������������������Ҫ����warpִ��memory load/storeʱ����Ҫ��transaction���������������������أ�
- Distribution of memory address across the thread of that warp ����ǰ�ĵ�����
- Alignment of memory address per transaction ����
һ����˵���������transactionԽ�࣬DZ�ڵIJ���Ҫ���ݴ����Խ�࣬�Ӷ�����throughput efficiency���͡�
����һ���ȶ���warp memory����transaction��������throughput efficiency����CC�汾�����ġ�����CC1.0��1.1��˵������global memory�Ļ�ȡ�Ƿdz��ϸ�ġ���1.1���ϣ�����cache�Ĵ��ڣ���ȡҪ���ɵĶࡣ
GPU Cache
��CPU��cacheһ����GPU cacheҲ��non-programmable�ġ���GPU�ϰ������¼���cache����ǰ�Ķ��Ѿ��ᵽ��
- L1
- L2
- Read-only constant
- Read-only texture
ÿ��SM����һ��L1 cache������SM����һ��L2 cache�����߶�����������local��global memory�ģ���ȻҲ����register spilling���Dz��֡���Fermi GPus �� Kepler K40����֮���GPU��CUDA�����������ö������������Ƿ�ʹ��L1��L2����ֻʹ��L2��
��CPU���棬memory��load/store�����Ա�cache��������GPU�ϣ�ֻ��load�����ᱻcache��store�ᡣ
ÿ��SM����һ��ֻ��constant cache��texture cache���������ܡ�
CUDA Variable Declaration Summary
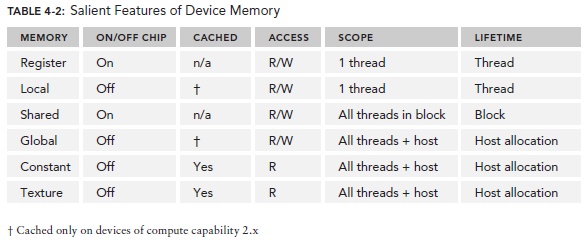
�±���֮ǰ���ܵļ���memory�������ܽ


Static Global Memory
����Ĵ��������������̬������global variable��֮ǰ�IJ�����ʵ����global variable�������¹��̾��ǣ���������һ��floatȫ�ֱ�������checkGlobal-Variable�У���ֵ����ӡ�����������ֵ�㱻�ı䡣��main�У����ֵʹ��cudaMemcpyToSymbol����ʼ�������յ�ȫ�ֱ������ı��ֵ������host��
#include <cuda_runtime.h>#include <stdio.h>__device__ float devData;__global__ void checkGlobalVariable() { // display the original value printf("Device: the value of the global variable is %f\n",devData); // alter the value devData +=2.0f;}int main(void) { // initialize the global variable float value = 3.14f; cudaMemcpyToSymbol(devData, &value, sizeof(float)); printf("Host: copied %f to the global variable\n", value); // invoke the kernel checkGlobalVariable <<<1, 1>>>(); // copy the global variable back to the host cudaMemcpyFromSymbol(&value, devData, sizeof(float)); printf("Host: the value changed by the kernel to %f\n", value); cudaDeviceReset(); return EXIT_SUCCESS;}
��������
$ nvcc -arch=sm_20 globalVariable.cu -o globalVariable$ ./globalVariable�����
Host: copied 3.140000 to the global variableDevice: the value of the global variable is 3.140000Host: the value changed by the kernel to 5.140000
��Ϥ��CUDA�Ļ���˼��������ף�����host��device�Ĵ�����д��ͬһ��Դ�ļ����������ǵ�ִ��ȴ����ȫ��ͬ���������磬host����ֱ�ӷ���device��������֮��Ȼ��
���ǿ��ܻᷴ��˵��������Ĵ�����ܻ��device��ȫ�ֱ�����
cudaMemcpyToSymbol(devD6ata, &value, sizeof(float));
���ǣ�����Ӧ�û�ע�����ļ��㣺
- �ú�����CUDA��runtime API��ʹ�õ�GPUʵ�֡�
- devData�����ֻ�Ǹ����ţ�����device�ı�����ַ��
- ��kernel��devData������������
���ң�cudaMemcpy������&devData���ַ�ʽ�����ݱ���,����������˵��devDataֻ�Ǹ����ţ�ȡַ���ֲ����������Ǵ���ģ�
cudaMemcpy(&devData, &value, sizeof(float),cudaMemcpyHostToDevice); // It’s wrong!!!
����������CUDA����Ϊ�����ṩ�ˣ�����devData���ַ�������ȡ������ַ�ķ�ʽ��
cudaError_t cudaGetSymbolAddress(void** devPtr, const void* symbol);
��ȡ��ַ֮�Ϳ���ʹ��cudaMemcpy�ˣ�
float *dptr = NULL;cudaGetSymbolAddress((void**)&dptr, devData);cudaMemcpy(dptr, &value, sizeof(float), cudaMemcpyHostToDevice);
����ֻ��һ�ַ�ʽ�ܹ�ֱ�ӻ�ȡGPU memory����ʹ��pinned memory�����Ľ���ϸ���ܡ�
Memory Management
Will coming soon…