第一节 同步容器、并发容器
1.简述同步容器与并发容器
在Java并发编程中,经常听到同步容器、并发容器之说,那什么是同步容器与并发容器呢?同步容器可以简单地理解为通过synchronized来实现同步的容器,比如Vector、Hashtable以及SynchronizedList等容器,如果有多个线程调用同步容器的方法,它们将会串行执行。
可以通过查看Vector、Hashtable等同步容器的实现代码,可以看到这些容器实现线程安全的方式就是将它们的状态封装起来,并在需要同步的方法上加上关键字synchronized,但在某些情况下,同步容器不一定就是线程安全的,比如获取最后一个元素或者删除最后一个元素,我们需要实现额外的同步操作:
public static Object getLast(Vector list) { int lastIndex = list.size() - 1; return list.get(lastIndex); } public static void deleteLast(Vector list) { int lastIndex = list.size() - 1; list.remove(lastIndex); }
虽然上面的方法看起来没有问题,Vector自身的方法也是同步的,但是在多线程环境中还是隐藏着问题。如果有两个线程A,B同时调用上面的两个方法,假设list的大小为10,这里计算得到的lastIndex为9,线程B首先执行了删除操作(多线程之间操作执行的不确定性导致),而后线程A调用了list.get方法,这时就会发生数组越界异常,导致问题的原因就是上面的复合操作不是原子操作,这里可以通过在方法内部使用list对象锁来实现原子操作。
同步容器会导致多个线程中对容器方法调用的串行执行,降低并发性,因为它们都是以容器自身对象为锁,所以在需要支持并发的环境中,可以考虑使用并发容器来替代。并发容器是针对多个线程并发访问而设计的,在jdk5.0引入了concurrent包,其中提供了很多并发容器,如ConcurrentHashMap、CopyOnWriteArrayList等。
其实同步容器与并发容器都为多线程并发访问提供了合适的线程安全,不过并发容器的可扩展性更高。在Java5之前,程序员们只有同步容器,且在多线程并发访问的时候会导致争用,阻碍了系统的扩展性。Java5介绍了并发容器,并发容器使用了与同步容器完全不同的加锁策略来提供更高的并发性和伸缩性,例如,在ConcurrentHashMap中采用了一种粒度更细的加锁机制,可以称为分段锁,在这种锁机制下,允许任意数量的读线程并发地访问map,并且执行读操作的线程和写操作的线程也可以并发的访问map,同时允许一定数量的写操作线程并发地修改map,所以它可以在并发环境下实现更高的吞吐量,另外,并发容器提供了一些在使用同步容器时需要自己实现的复合操作,包括putIfAbsent等,但是由于并发容器不能通过加锁来独占访问,所以我们无法通过加锁来实现其他复合操作了。
2.参考资料:
(1)http://www.cnblogs.com/dolphin0520/p/3933404.html
第二节 ConcurrentHashMap
1.初识ConcurrentHashMap
针对并发容器中的ConcurrentHashMap,《java并发编程实战》一书有如下这样一段文字:

此处将揭开ConcurrentHashMap的神秘面纱,首先我们看一下ConcurrentHashMap的结构图,如下:

2.详述ConcurrentHashMap
(1)ConcurrentHashMap的并发度
ConcurrentHashMap把实际map划分成若干部分来实现它的可扩展性和线程安全。这种划分是使用并发度获得的,它是ConcurrentHashMap类构造函数的一个可选参数,默认值为16,这样在多线程情况下就能避免争用。
(2)ConcurrentHashMap的锁分离技术
HashTable容器在竞争激烈的并发环境下效率低下,原因是所有访问HashTable的线程都必须竞争同一把锁。若容器中有多把锁,每一把锁用于锁定容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁并访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
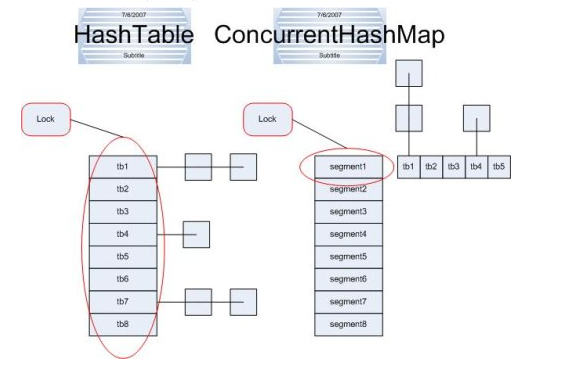
对比上图(该图摘自网络),同步容器HashTable实现锁的方式是锁整个hash表,而并发容器ConcurrentHashMap的实现方式是锁桶(简单理解就是将整个hash表想象成一大缸水,现在将这大缸里的水分到了几个水桶里,hashTable每次都锁定这个大缸,而ConcurrentHashMap则每次只锁定其中一个 桶)。
ConcurrentHashMap将hash表分为16个桶(默认值),诸如get,put,remove等常用操作只锁当前需要用到的桶。试想,原来只能一个线程进入,现在却能同时16个线程进入,并发性的提升是显而易见的。
(3)ConcurrentHashMap的remove操作
当对ConcurrentHashMap进行remove操作时,并不是进行简单的节点删除操作
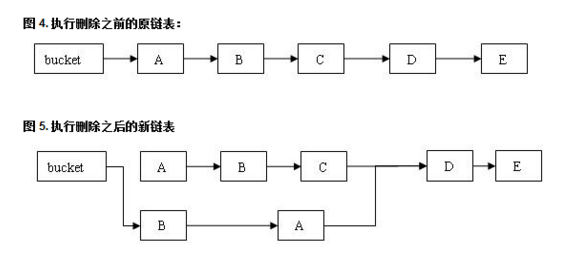
对比上图,当对ConcurrentHashMap的一个segment(也就是一个桶中的节点)进行remove后,例如,删除节点C,C节点实际并没有被销毁,而是将C节点前面的反转并拷贝到新的链表中,C节点后面的不需要被克隆。这样的操作使并发的读线程不受并发的写线程的干扰,例如,现在有一个读线程读到了A节点,写线程把C删掉了,但是看上图,读线程仍然可以继续读下去;当然,如果在删除C之前读线程读到的是D,那么更不会有影响。
根据上面所提到的在ConcurrentHashMap中删除一个节点并不会立刻被读线程感受到的效果,就是传说中的弱一致性,所以ConcurrentHashMap的迭代器是弱一致性迭代器
3.参考资料:
本小节仅简单概述了ConcurrentHashMap的一些内容,其实现机制等可参考以下优质文章
(1)http://www.cnblogs.com/ITtangtang/p/3948786.html
(2)http://ifeve.com/concurrenthashmap/
(3)http://blog.csdn.net/xuefeng0707/article/details/40834595
第三节 SynchronousQueue
(1)初识SynchronousQueue
SynchronousQueue是一种无界、无缓冲的等待队列,可以认为SynchronousQueue是一个缓存值为1的阻塞队列,在某次添加元素后必须等待其他线程取走该元素后才能继续添加,但是其isEmpty()方法永远返回true,remainingCapacity()方法永远返回0,remove()和removeAll() 方法永远返回false,iterator()方法永远返回空,peek()方法永远返回null。
声明一个SynchronousQueue有两种不同的方式,它们之间有着不太一样的行为。
公平模式和非公平模式的区别:如果采用公平模式,SynchronousQueue会采用公平锁,并配合一个FIFO队列来阻塞多余的生产者和消费者;如果是非公平模式(SynchronousQueue默认),SynchronousQueue会采用非公平锁,同时配合一个LIFO队列来管理多余的生产者和消费者。若采用非公平模式,如果生产者和消费者的处理速度有差距,则很容易出现饥渴的情况(可能某些生产者或者消费者的数据永远都得不到处理)。
(2)参考资料
(1)Java并发包中的同步队列SynchronousQueue实现原理 http://ifeve.com/java-synchronousqueue/