1. 基本查询
select [all | distinct] 字段或表达式列表 [from子句] [where子句] [group by子句] [having子句] [order by子句] [limit子句];
SELECT 8+5;# 8+5 ,8>5是表达式SELECT name,8>5,8+5,id+class_id,NOW(),CONCAT('a','b','c') FROM stu;1.1 all和 distinct
用于设定select出来的数据,是否消除“重复行”,可以不写,那就是默认值all:
all:表示不消除,即所有都出来,默认值;
distinct:表示消除重复行; 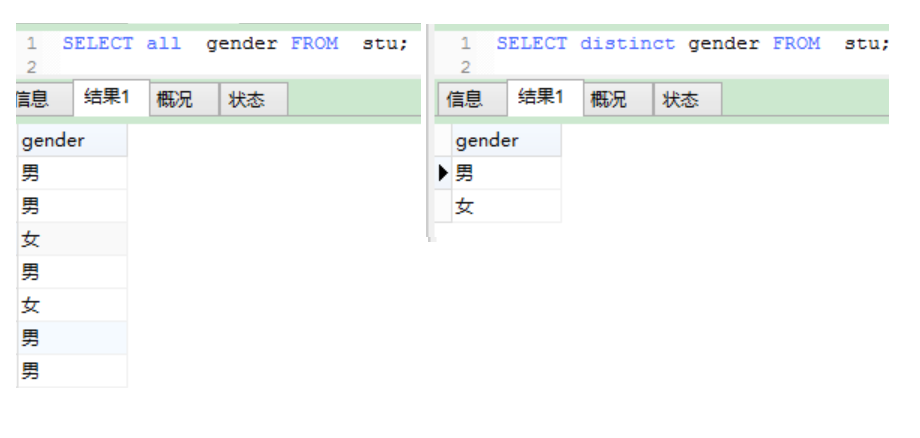
1.2 from子句
from子句表示select语句从中“取得”数据的数据源――其实就是表。
通常,其后面就是表名; 比如: from table1,
但,也可能是其他一些数据来源;from table1,table2(连接表);
#查询学生表stu的所有数据SELECT * FROM stu;1.3 where子句
- where子句就是对from子句中的“数据源”中的数据进行筛选的条件设定,筛选的机制是“一行一行进行判断”,其作用,几乎就跟各种语言中if语句的作用一样。
- where子句依赖于from子句
- where子句中,通常都需要使用各种“运算符”:
①算术运算符: + - * / %
②比较运算符: >, >= , < , <= , =(等于) , < >(不等于) , ==(等于) , !=(不等于)
③逻辑运算符: and or not
#查询学生表中班级号为偶数的学生信息SELECT * FROM stu WHERE class_id % 2 = 0;#查询学生表中班级号>=学生信息SELECT * FROM stu WHERE class_id >= 2;#查询学生表中班级号不等于2的学生信息SELECT * FROM stu WHERE class_id <> 2;#查询学生表中班级号等于1 或者班级号等于2的学生信息SELECT * FROM stu WHERE class_id = 1 or class_id = 2;#查询学生表中性别不是男的学生信息SELECT * FROM stu WHERE not (gender = '男');#查询学生表中班级号为3且性别为女的学生信息SELECT * FROM stu WHERE class_id = 3 and gender = '女';4.where后面为 true 或 false
#查询所有学生的信息SELECT * from stu WHERE true;#结果集为空SELECT * from stu WHERE false;5.is 运算符
#判断name字段是"null"值 -- 就是没有值;select * from stu name is null;# field is not null:判断某个字段不是“null”值# field is true:判断某个字段为"真"(true)# field is false:判断某个字段为"假"(false):0, 0.0, '', null 这几个值都为false6.between运算符:范围判断
#查询学生表中班级号范围为[1,2] 也就是班级号大于等于1且班级号小于等于2SELECT * from stu where class_id BETWEEN 1 AND 2;#等价于上一句SELECT SELECT * from stu where class_id >=1 and class_id <= 2;7.in运算符:给定确定数据的范围判断
field in(1,8,3);
表示字段值为所列出的这些值中的一个,就算是满足了条件;这些值,通常是零散无规律的
SELECT * from stu where class_id in(1,8,3);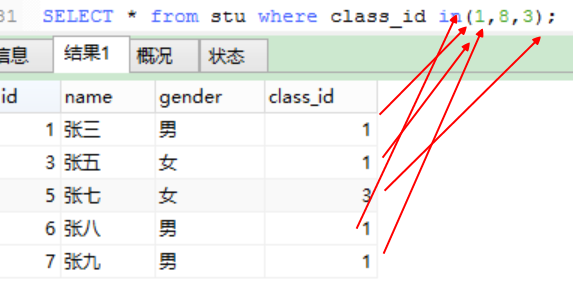
8.like运算符:对字符串进行模糊查找
实现对字符串的某种特征信息的模糊查找。它其实依赖于以下2个特殊的“符号”:
%:它代表“任何个数的任何字符”;
_ :(下杠),它代表“一个任何字符”;
address like ‘%广州%’: 表示address中包含’广州’这一个字的所有数据行;比如: 你知道广州吗 广州天河
address like ‘广州%’: 表示address中以’广州’开头的所有数据行;比如:广州人民,广州欢迎你来
address like ‘%广州’: 表示address中以’广州’结尾的所有数据行;比如:广东广州,中国城市广州
address like ‘广州_’: 表示address中以’广州’开头并只有3个字符的所有数据行;比如:广州市
address like ‘_广州’: 表示address中以’广州’结尾并只有3个字符的所有数据行;比如:去广州如果字符串中含有 “%” 或者 “_” 那么就需要进行转义
\% 就代表 % 本身
\_ 就代表 _ 本身
SELECT * from stu WHERE name LIKE '张%';SELECT * from stu WHERE name LIKE '_三';1.4 group by 子句:分组
形式:
group by 字段1 【desc | asc】, 字段2 【desc | asc】, …
说明:
1,分组是对“前述”已经找出的数据(也可能是where已经筛选过了)按照指定的依据(字段)进行分组;
2,同时,该分组结果,可以同时指定其“排序方式”:desc(倒序),asc(顺序);
3,分组的依据可以是2个或者2个以上字段,但是通常的应用只用一个分组依据。
注意: 分组之后,通常只有如下几种可用的“组信息”了(即可以出现在select中):
1,分组依据本身的信息,其实就是该分组依据的字段名;
2,每一组的“数量”信息:就是用count(*)获得;
3,原来数据中的“数值类型字段的聚合信息”,包括如下几个:
最大值: max(字段名)
最小值: min(字段名)
平均值: avg(字段名)
总和值: sum(字段名)
产品表:product 有如下数据: 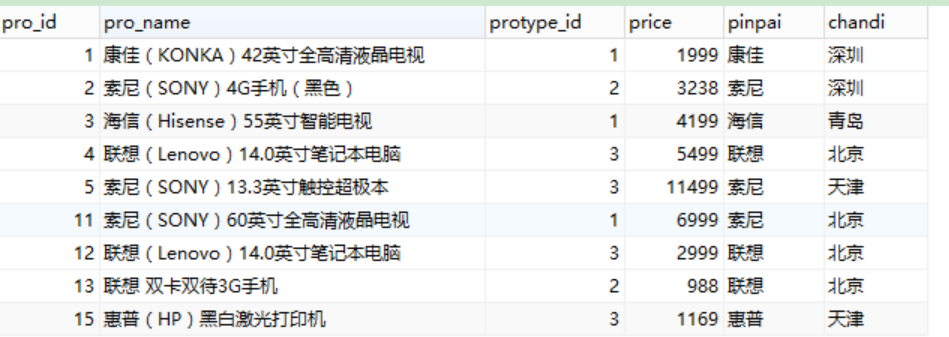
#不会报错是因为mysql比较宽松的语法SELECT * from product GROUP BY chandi;正确的写法:
SELECT pinpai,count(*) as 品牌的产品数量 ,max(price) as 最高价,min(price) as 最低价, avg(price) as 平均价,sum(price) as 总价格 from product GROUP BY pinpai;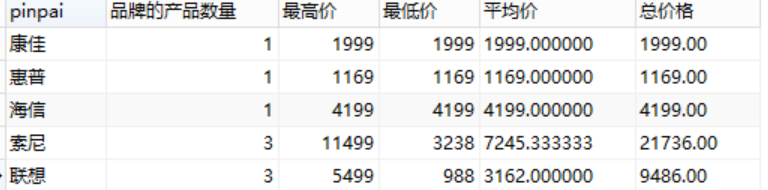
1.5 having 子句
having对分组之后的数据行进行筛选,having子句的出现依赖于group by子句。
①找出品牌中产品平均价格超过5000的品牌
SELECT pinpai, avg(price) AS 平均价FROM productGROUP BY pinpaiHAVING 平均价 > 5000;
②找出品牌中产品数量大于2的品牌
SELECT pinpai, count(*) AS 品牌的产品数量FROM productGROUP BY pinpaiHAVING 品牌的产品数量 > 2;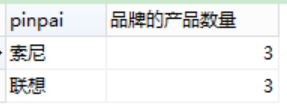
1.6 order by 子句
用于将前面“取得”的数据以设定的依据(字段)来进行排序以输出结果。
order by 字段1 【asc | desc】, 字段2 【asc | desc】,…
1,对前面的结果数据以指定的一个或多个字段排序;
2,排序可以谁定正序(asc,默认值)或倒序(desc);
3,多个字段的排序,都是在前一个字段排序基础上,如果还有“相等值”,才继续以后续字段排序,如果按前面的字段排序结果每个值都不相等,后续的字段排序没有任何意义。
#查询所有学生信息,按照班级号倒序排,班级号相同的按照学生ID升序排序SELECT * FROM stu ORDER BY class_id desc,id asc;
1.7 limit 子句
用于将“前述取得的数据”,按指定的行取出来:从第几行开始取出多少行,行号是从0开始;
limit n; 等价于 limit 0 , n;
SELECT * from stu ORDER BY class_id desc LIMIT 3;SELECT * from stu ORDER BY class_id desc LIMIT 0,3;#因为下标是0开始的,实际上是从第三行算起(包括第三行)取出3条数据SELECT * from stu ORDER BY class_id desc LIMIT 2,3;