��Ե�����������
- Fast Inference
- Model Compression
- Reduction in Communication
- Federated Learning and Optimization
- Federated Learning and security
??�����Ե���㷽����˺ܶ��µ��о��ɹ�����AI�����£���Ե���ܣ�Edge Intelligence�����µ��о�����ڴ�ͳ�����ѧϰ�о�����ע��������ģ�͵�ȷ�ʣ����������ʵ�ʲ����еĿ����ԣ�������Ӧ�ȡ�Ч�ʡ��ܺġ���Դռ�õȷ��档
??����֮�⣬����ѧϰ�DZ�Ե���ܵ�һ������Ҫ�ķ��棬�Լ���صİ�ȫ�Է�����о���ѡȡ�˽����궥����������ϸߵļ�ƪ���ķ�����������
Fast Inference
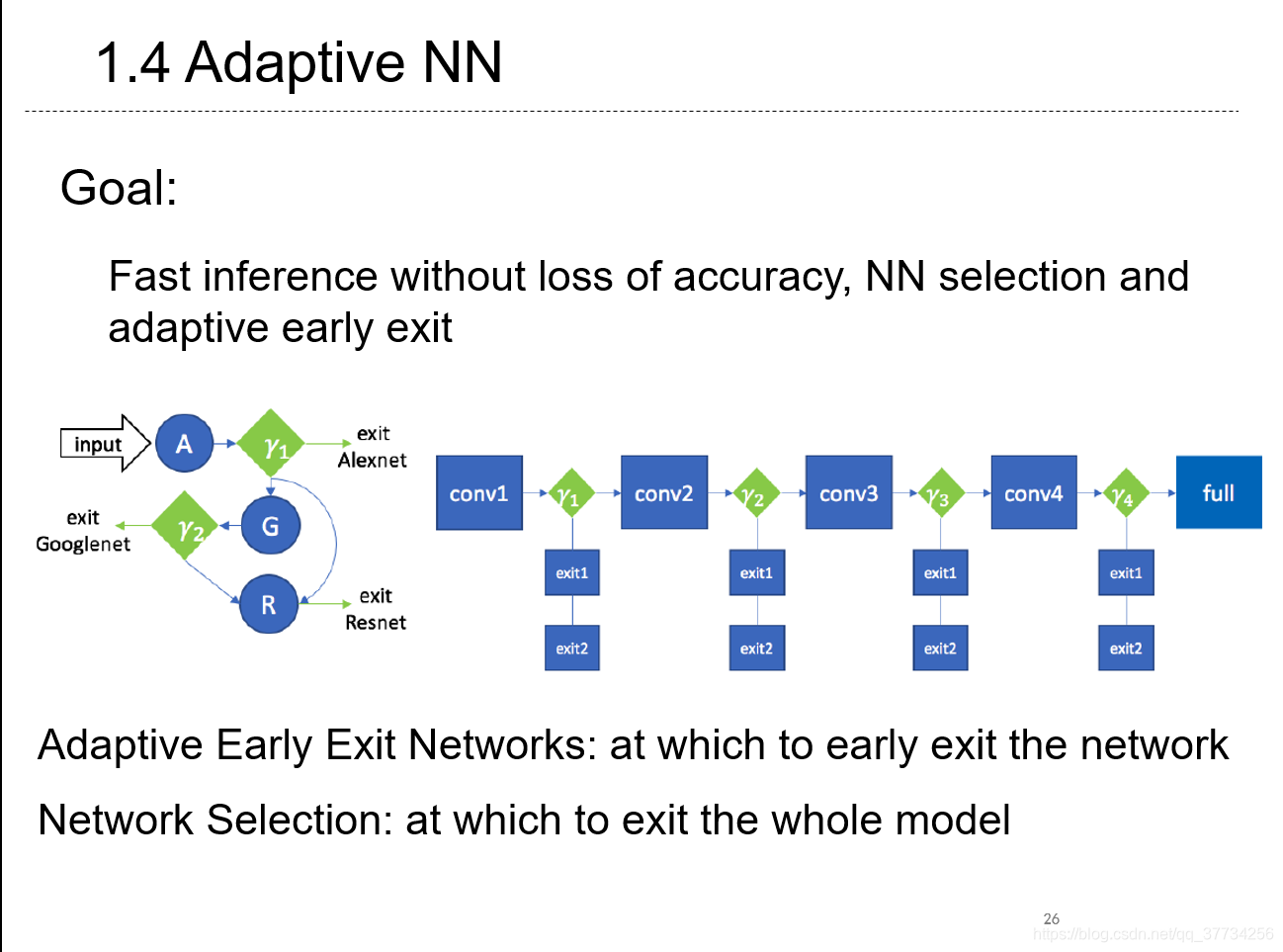
- BranchyNet: Fast inference via early exiting from deep neural networks, ICPR, 2016�������һ����ģ���ƶ�ʱ������ȷ�ʣ��ﵽȷ����ֵ�ͽ�ѡ���������ģ�ͻ�ý���ķ�����

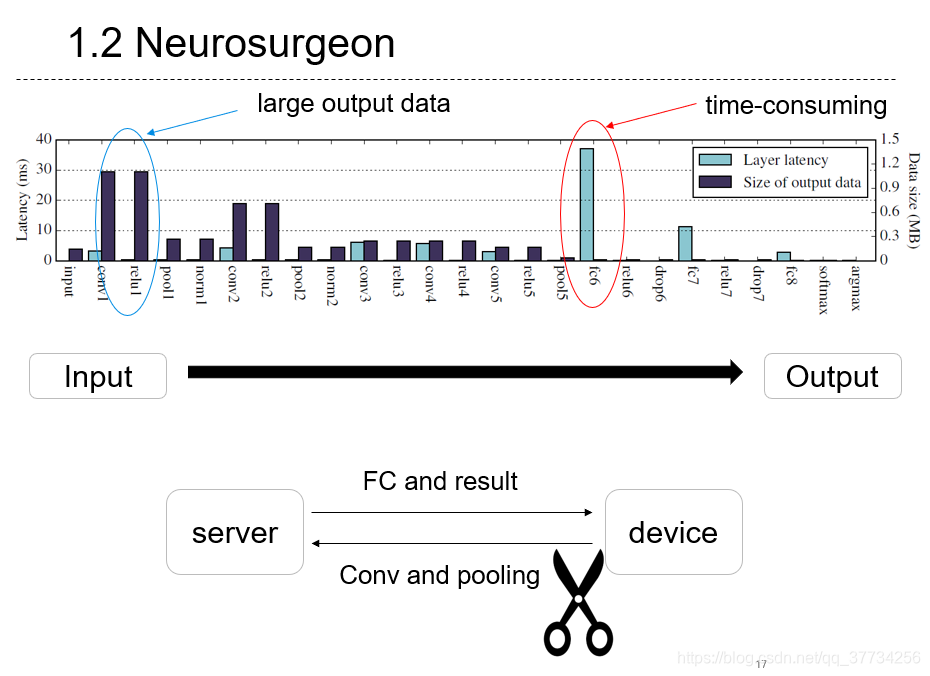
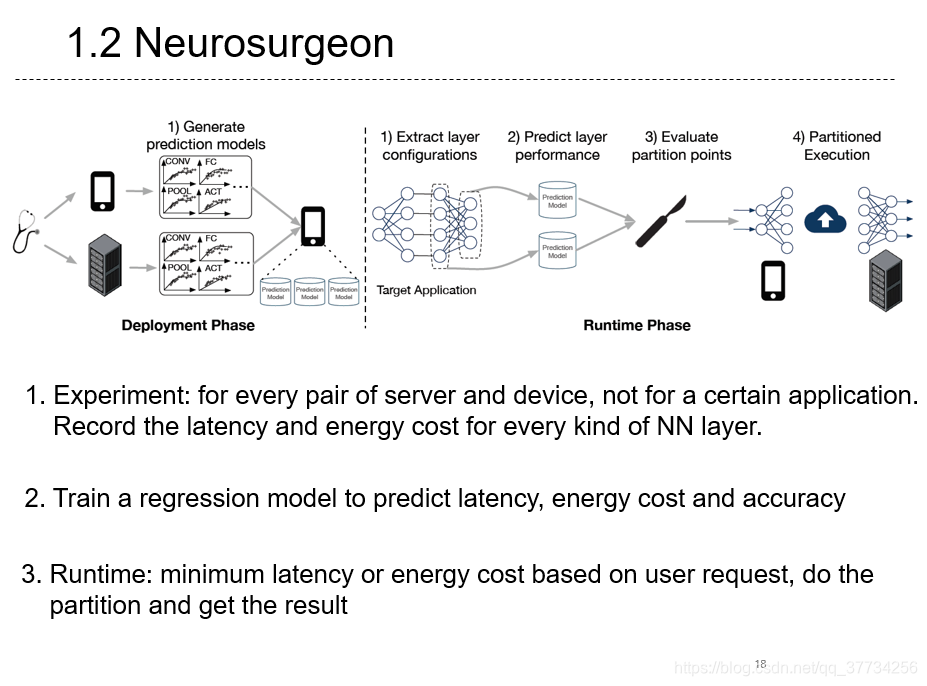
- Neurosurgeon: Collaborative Intelligence Between the Cloud and Mobile Edge, ASPLOS, 2017, ��BranchyNet�Ļ����ϣ���ϱ�Ե���㣬�����Ʊ߶�Эͬ�ƶϵķ����������������ƶϲ���ʱ��ɢ���Ʊ߶��У��ﵽģ���ƶϵ��ܺĺ��ӳ�Ҫ��

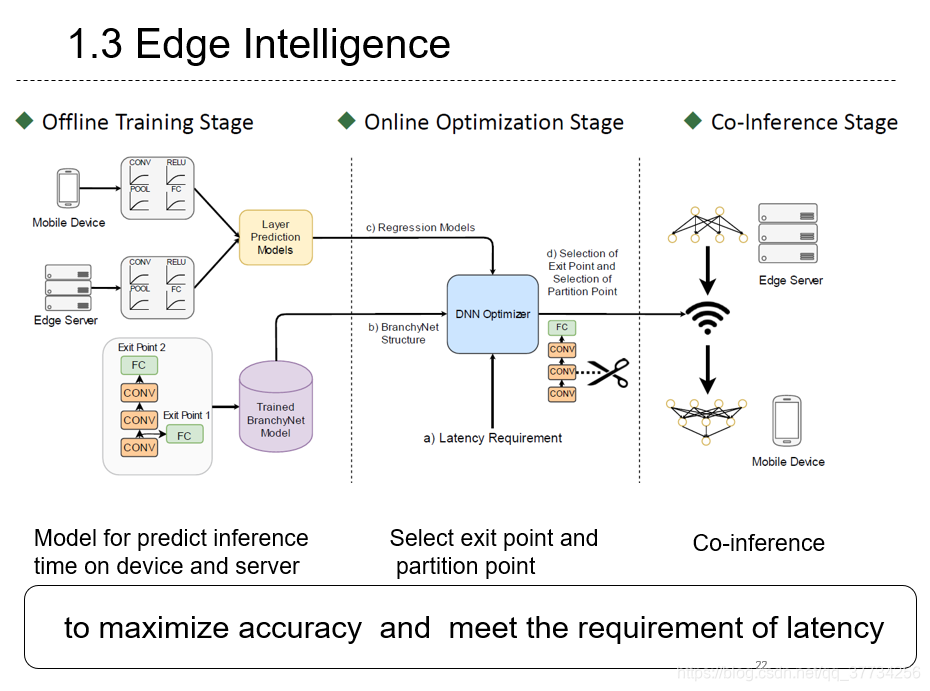
- Edge Intelligence: On-Demand Deep Learning Model Co-Inference with Device-Edge Synergy, SIGCOMM, 2018, ��ǰ��ƪBranchyNet��Neurosurgeon�Ļ����ϣ��ο�ǰһƪ���ģ�ʹ�����Իع�ģ�ͣ���ʵ���Զ������������ֺ��Զ�����BranchyNet��������ʱ��Ҫ���ͬʱ�ﵽ����ȡ�

- Adaptive Neural Networks for Efficient Inference, ICML, 2017, ��BranchyNet�Ļ����ϣ�BranchyNet����һ������ģ������AlexNet�У���ǰ�˳�����ִ�к��漸�㡣���������У��ǰ��Զ����ķ�ʽ���Ӽ���������ģ�ͣ������ǰ�˳��Ͳ�ִ�к�������ӵ������硣������ͼ������У��������Զ����ķ�������ڽ���AlexNet�����BranchyNet��������ȴﵽ���˳��������������GoogleNet��ResNet���ּ���ִ�С�
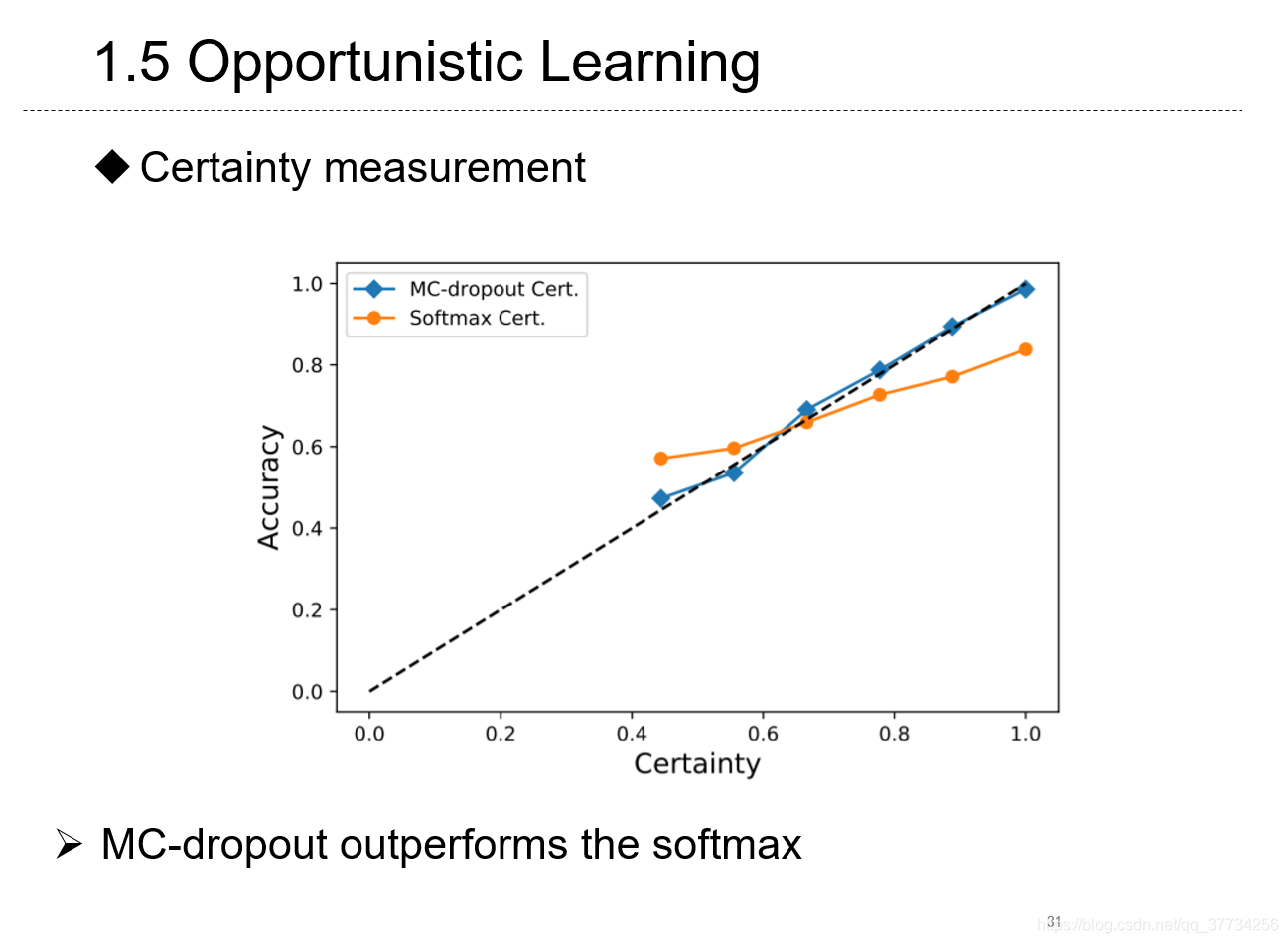
- Opportunistic Learning: Budgeted Cost-Sensitive Learning from Data Streams, ICLR, 2019, ���������ijЩ����ѧϰ�����ͱ�Ե���ܳ������������Ƶ��������������ȡ����Ҫ�������۵ģ�ʹ��ǿ��ѧϰ�ļ�ֵ��������ȡ���������л��ر��ָ��BranchyNet�����������ع��ƾ��Ȳ�ȷ����������ؿ�����ƾ��ȷ�����

Model Compression
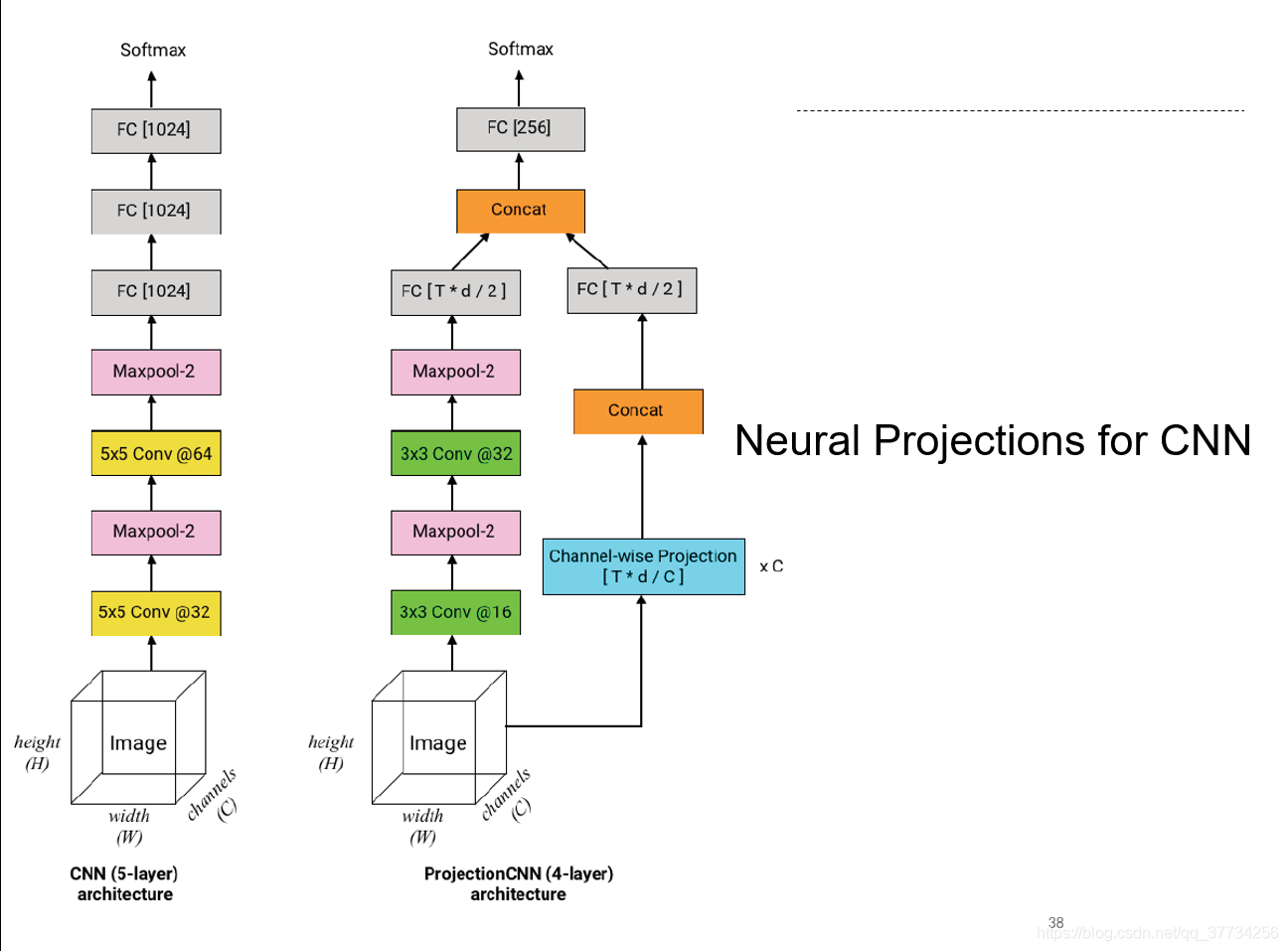
Efficient On-Device Models using Neural Projections
, ICML, 2019, �����һ������GAN��֪ʶ�����������ͶӰ�ķ�����ѹ��ģ�ͽṹ����ø�С��ģ�ͣ��÷�����ΪCNN��RNN���˶��ơ�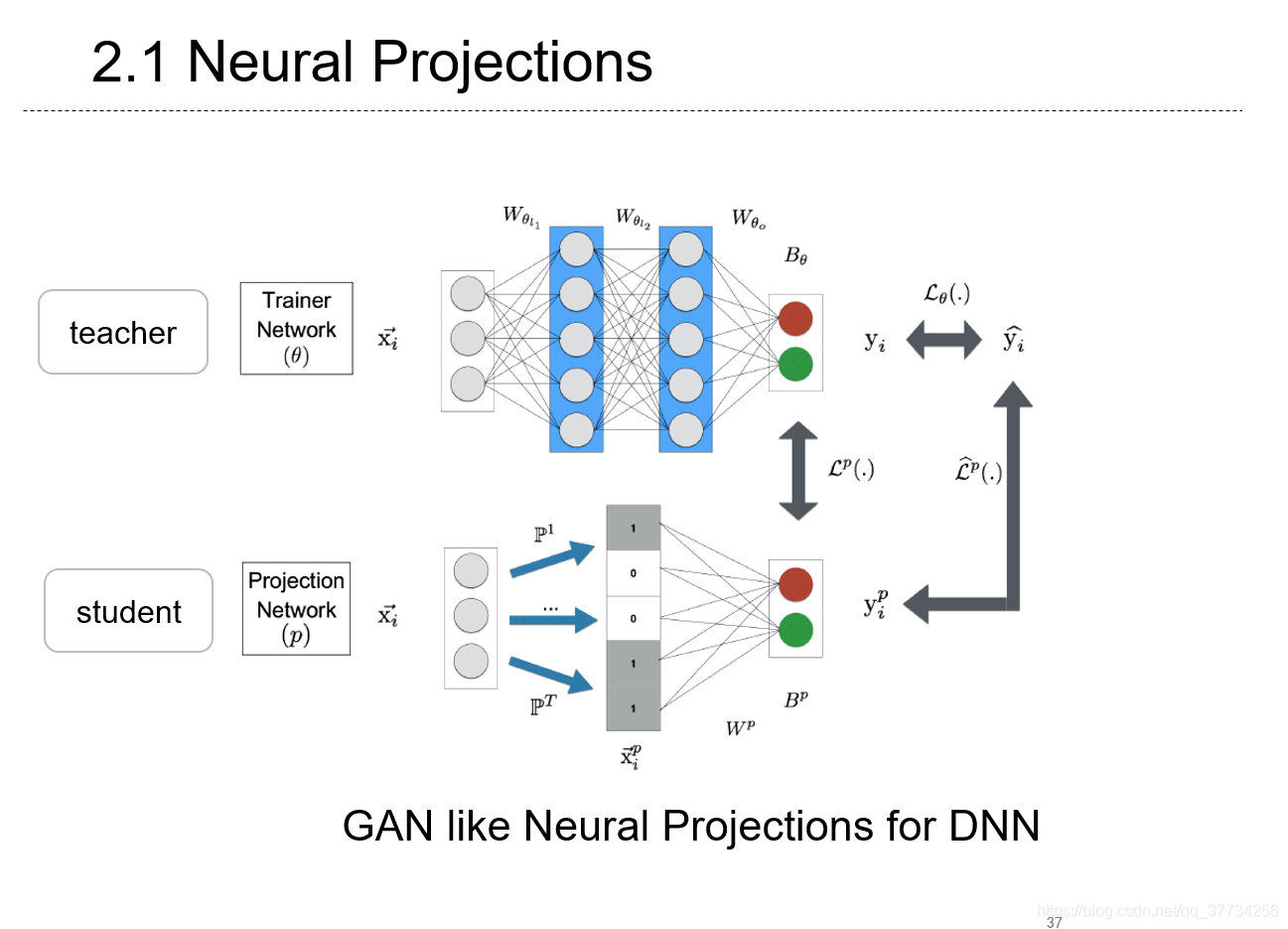
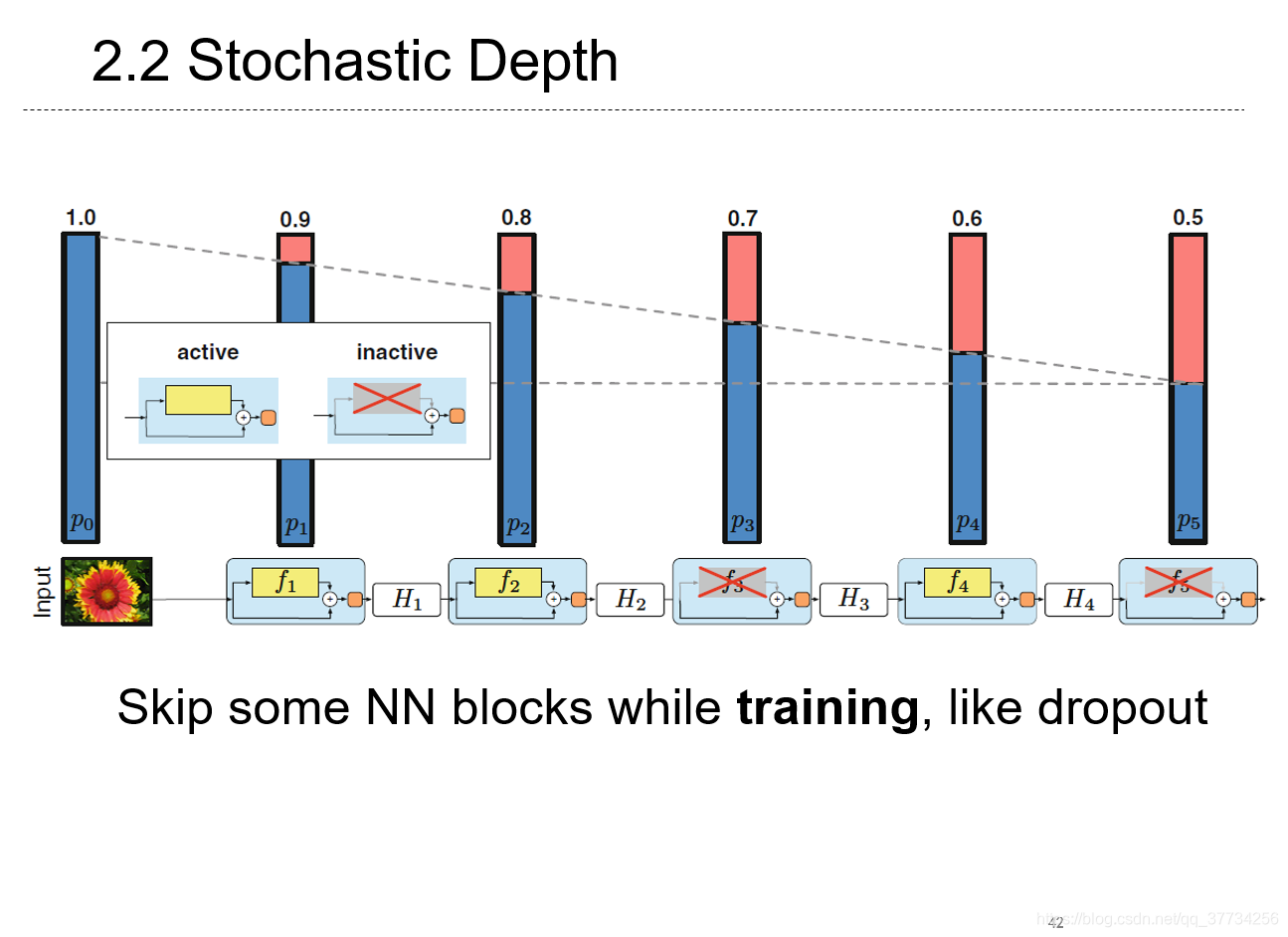
- Deep Networks with Stochastic Depth, ECCV, 2016, ����ģ��ѹ�����棬����Ϊ��Ķ��Ǽӿ�ģ���ƶϣ���һƪ�ӿ���ѵ�����̣���ѵ��ʱʹ��skip�ķ������������翴��һ�����飬��dropoutһ��������һ���飬����ѡ������Ҳ����ѡ�������Լ���ѵ�����̣����ƶ�ʱ��ʹ�����������硣
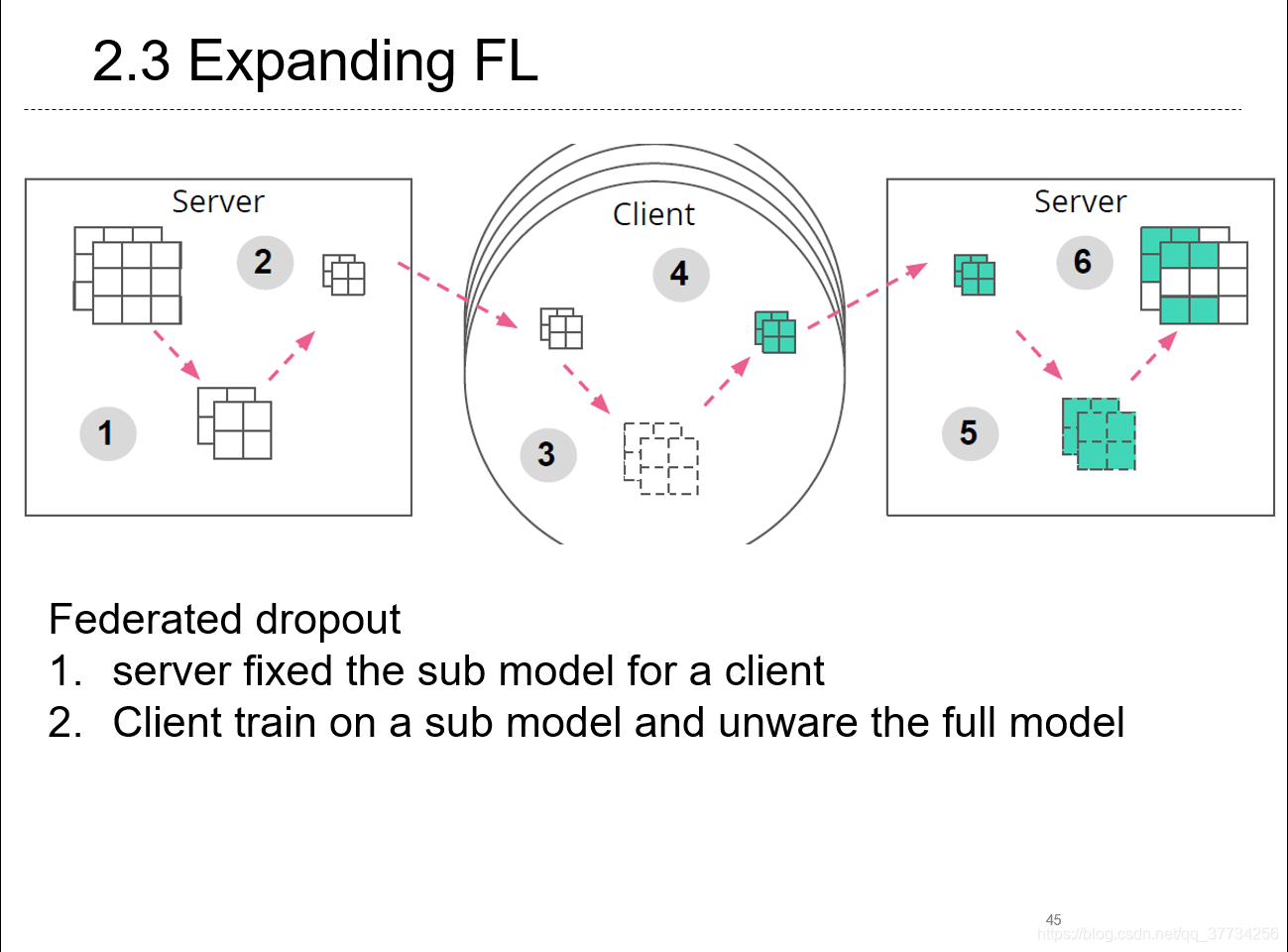
- Expanding the Reach of Federated Learning by Reducing Client Resource Requirements, TODO, 2018, �����Federated Dropout�ķ�����ѵ����ÿ��������ӵ�еIJ��Ǵ�ͳ����ѧϰ�����������model������dropout��һ����submodel��
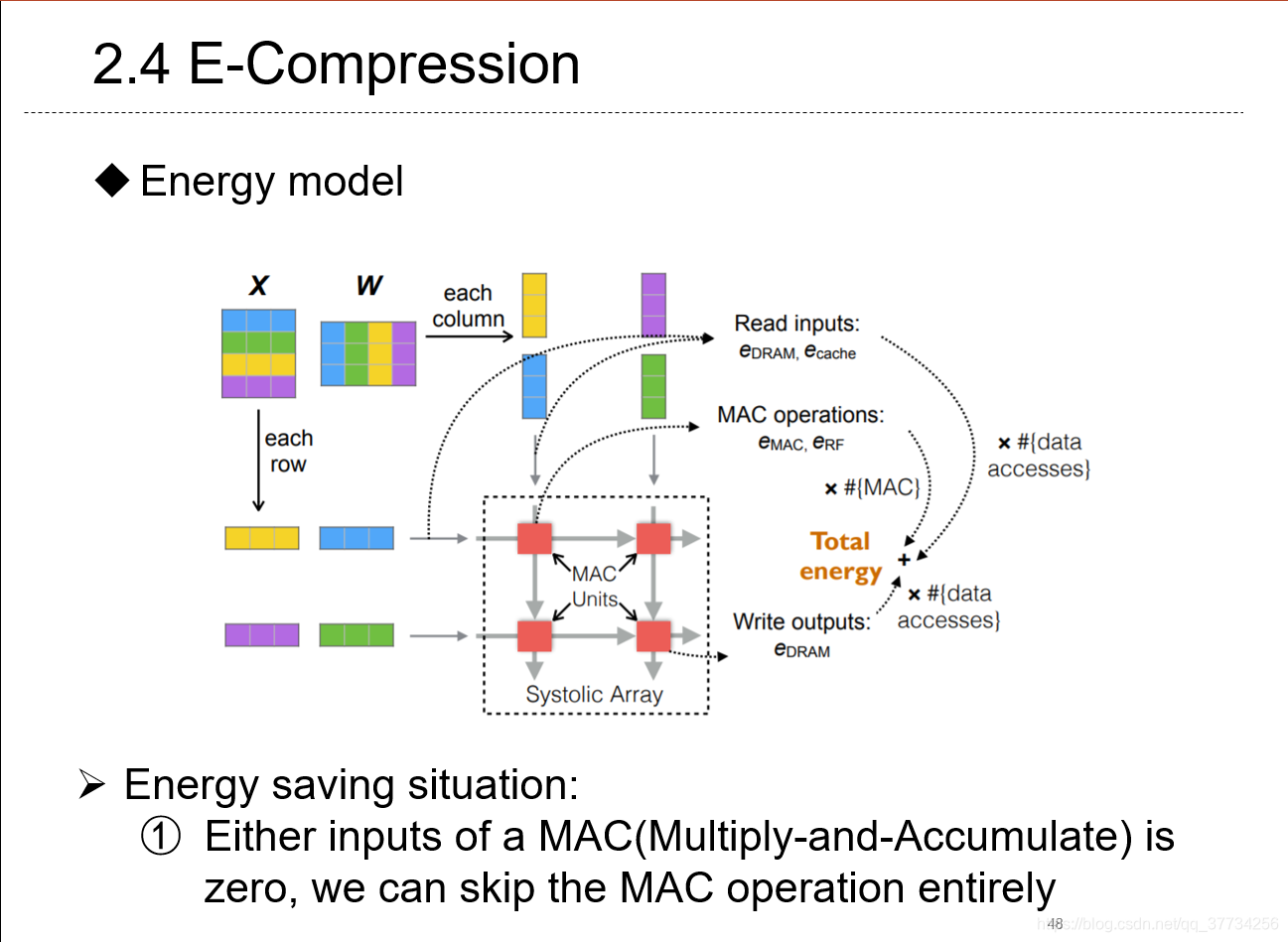
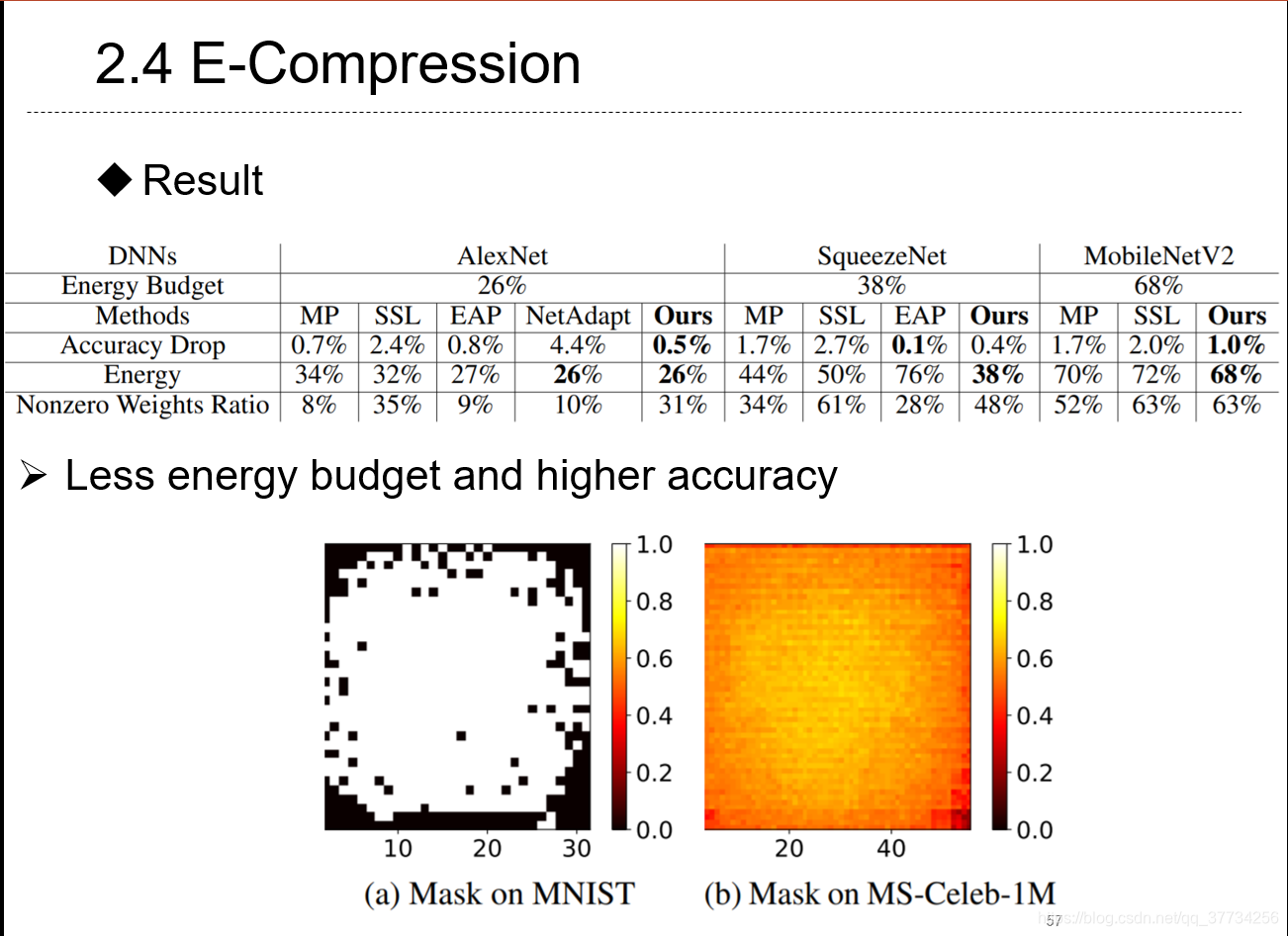
- Energy-Constrained Compression for Deep Neural Networks via Weighted Sparse Projection and Layer Inp, ICLR, 2019, ��һ������������ĽǶ��������������ƶ�ʱ���ܺĵģ������˼��پ���˼�����Ӧ��Ҫ�����ܶ����������㣬ͨ��������Ȩ�ص�ϡ��ͶӰ���Լ��״������input mask�������Զ����뱾�����С�ѵ�������ﵽ�ܺ���͡�
Reduction in Communication
- Federated Learning: Strategies for Improving Communication Efficiency, NIPS, 2016, �״������structured update��skewed update����������ѧϰ�IJ������£�����ͨ������


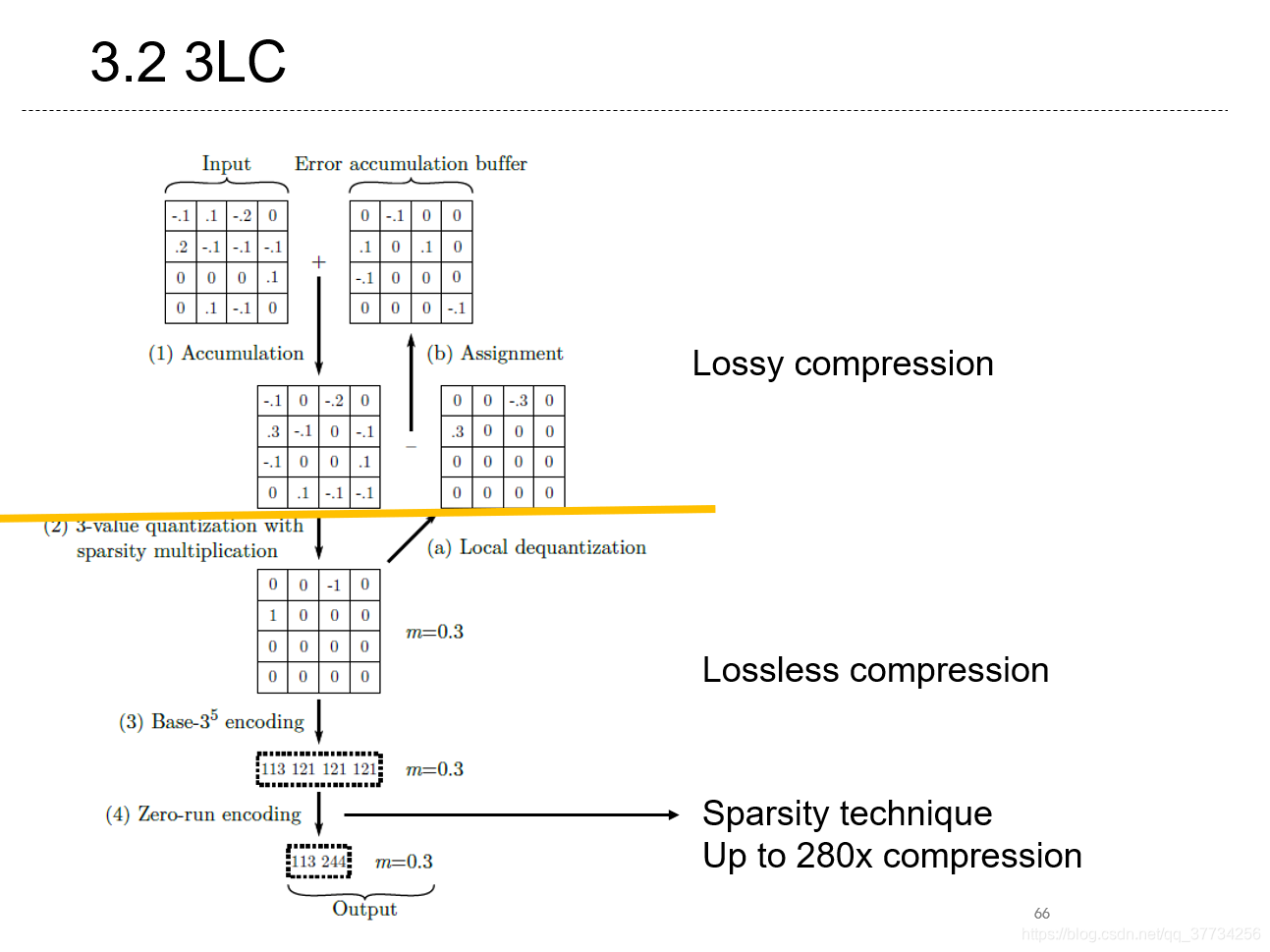
- 3LC: Lightweight and Effective Traffic Compression for Distributed Machine Learning, SysML, 2019, �����������ݶ�ѹ�����뷽�����״�ʹ�ô����ۼƾ������ʱ��ѹ��280x��
Federated Learning and Optimization
- Privacy-Preserving Deep Learning,CCS, 2015
���������Distributed Selective SGD����������ѧϰ���¶������ø����ġ�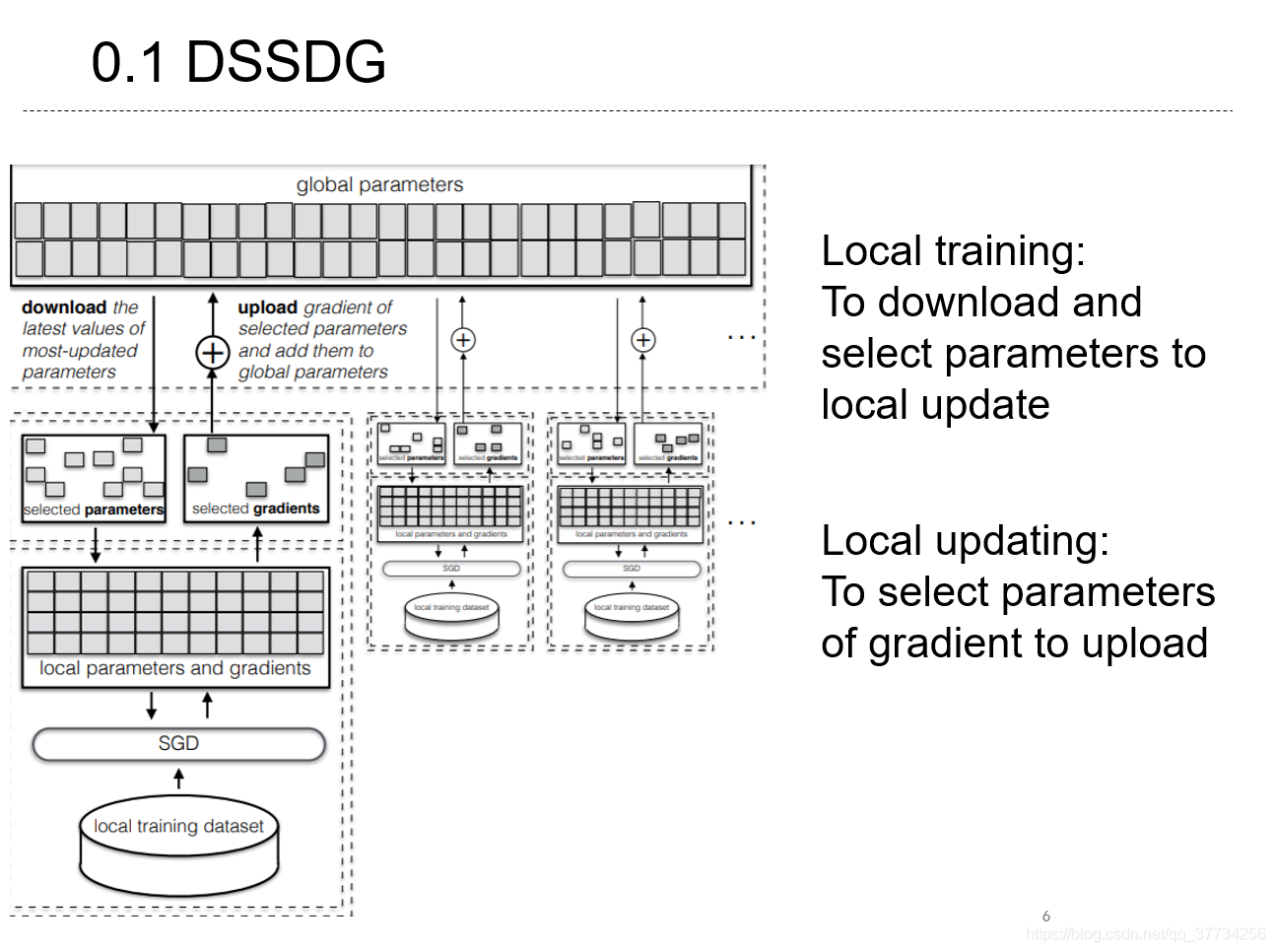
- Communication-Efficient Learning of Deep Network from Decentralized Data,AISTATS, 2017������ѧϰ��ɽ֮��֮һ�������FedAVG�IJ����ۺϷ�����

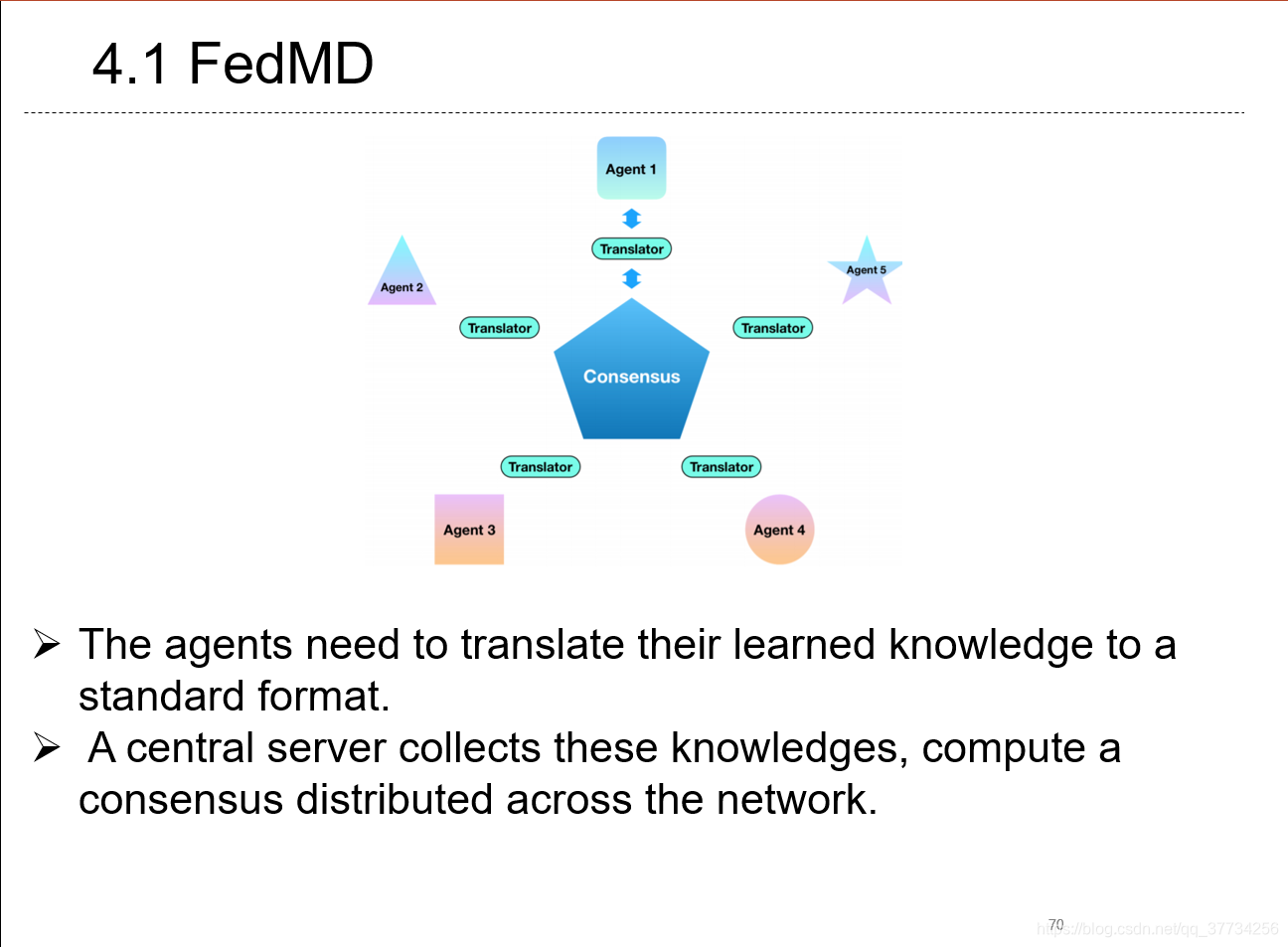
- FedMD: Heterogeneous Federated Learning via Model Distillation, NeuIPS WorkShop, 2019, ��֪ʶ������������ѧϰ���������ݵIJ����ݶȣ�����soft score��
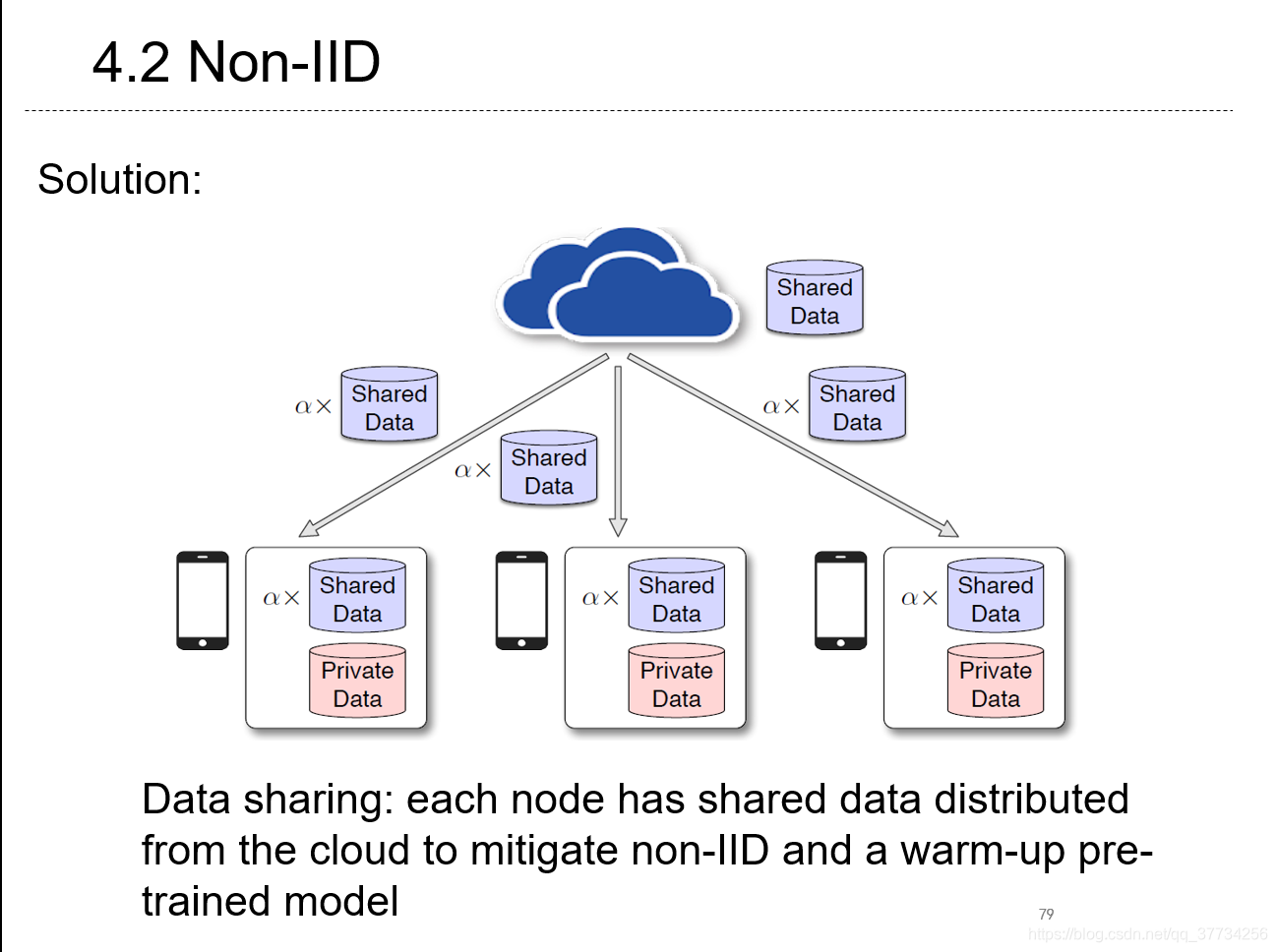
- Federated Learning with Non-IID Data, CoRR, 2018, ͨ��ʵ����Ƶ���ָ������ѧϰ��ÿ�����������ݵ�Earth mover��s distance��non-iid�Լ������½�֮���й����������ͨ���������ݽ���non-iid�̶ȡ�
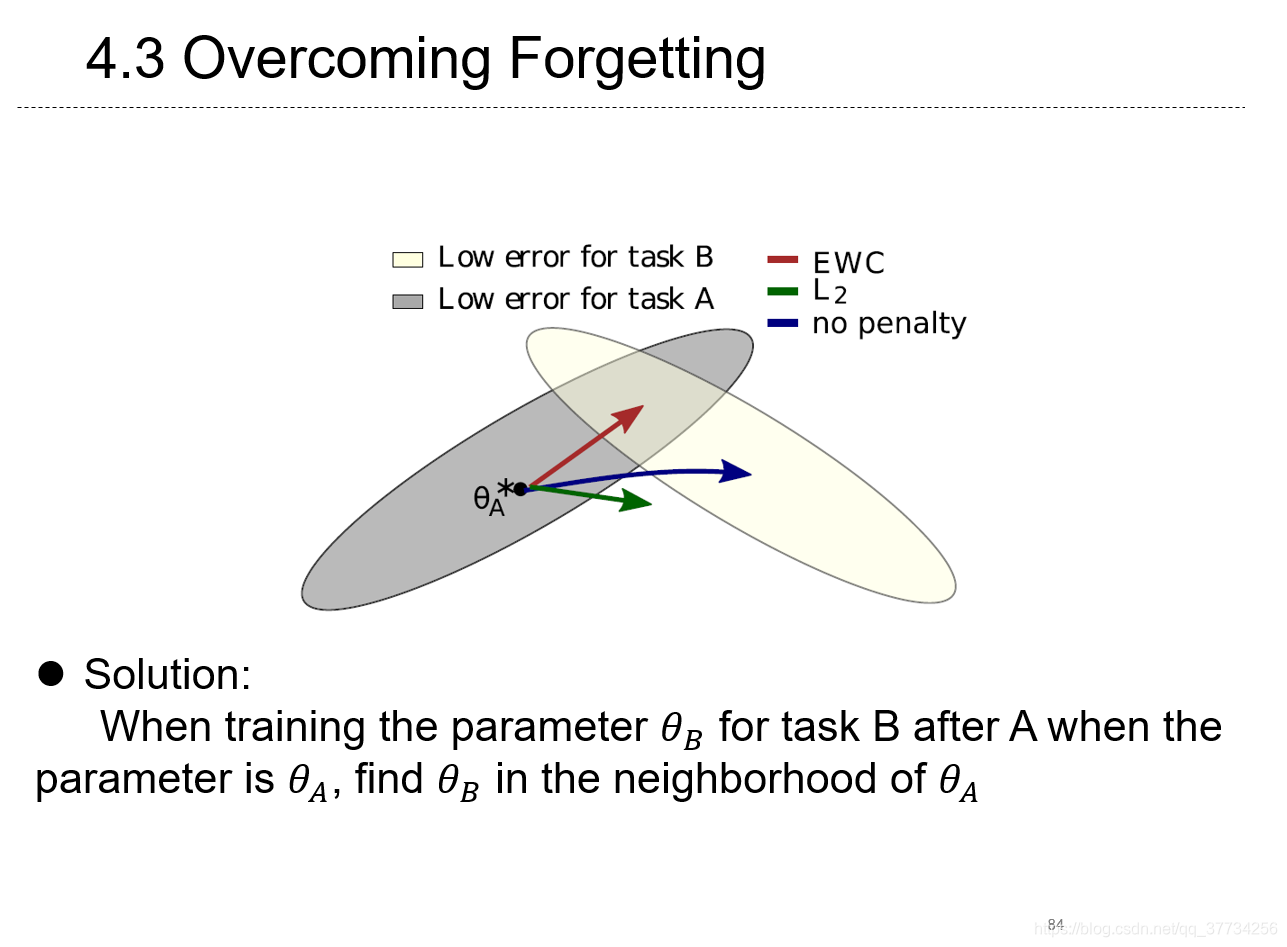
- Overcoming Forgetting in Federaerd Learning on Non-IID Data, NeuIPS WorkShop, 2019, ���ʹ�ó���ѧϰ�з�ֹ������EWC��ʧ����������ѧϰ��non-iid���⡣

- Variational Federated Multi-Task Learning, CoRR, 2019, ̽������ѧϰ�Ŀ���µĶ�����ѧϰ,ʹ���˱�Ҷ˹����ķ������ܱ�Ҷ˹��


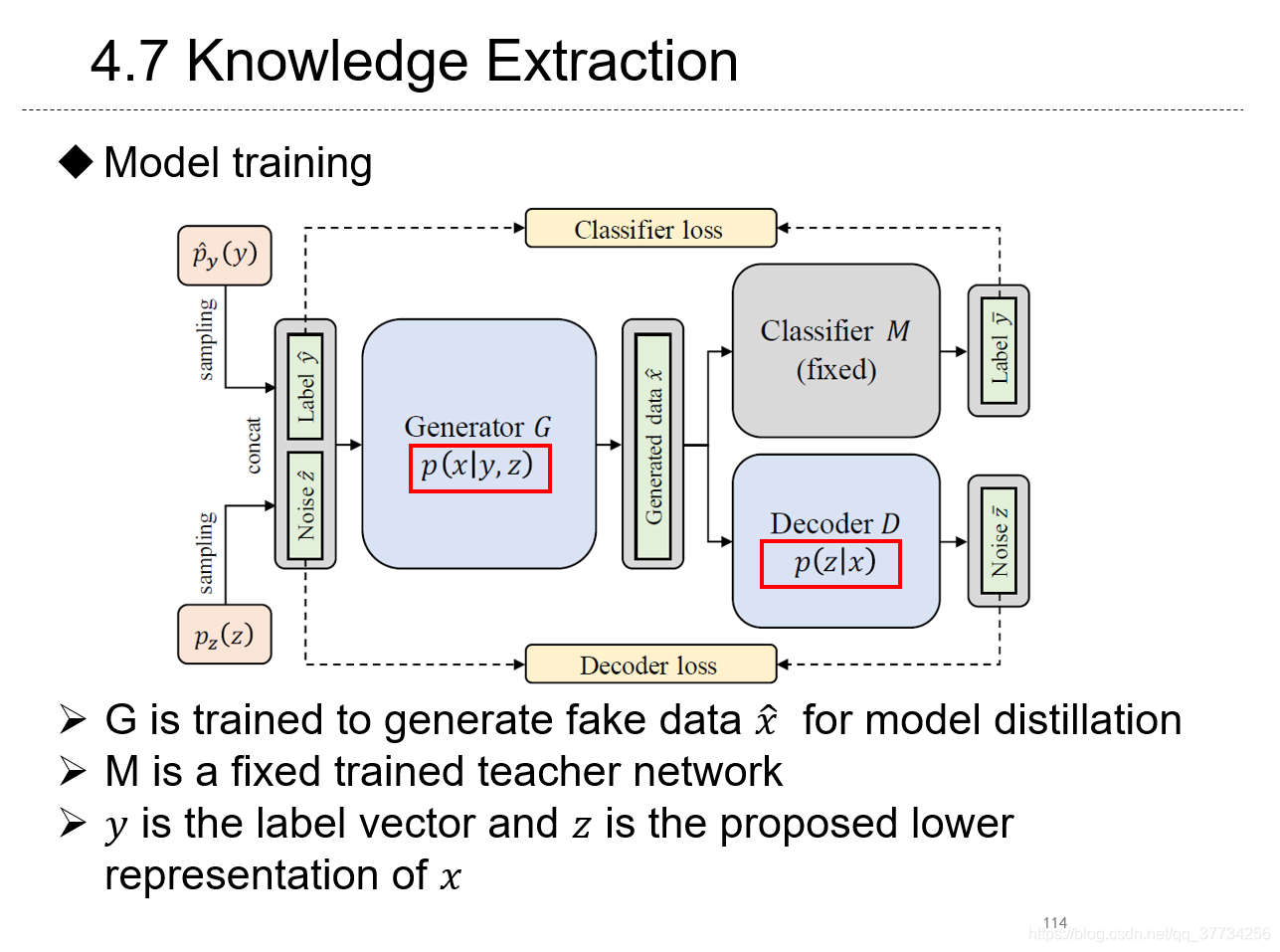
- Knowledge Extraction with No Observable Data, NeurIPS, 2019, �������Ҫ�۲����ݣ�Ҳ�ܴ�һ��������ģ���л�ȡ����Ϣ������֪ʶ��������������GAN�ķ��������ɵ����ݱ�ʾ��������ѧϰ����˽й¶�õ������ݾ�ֵ��

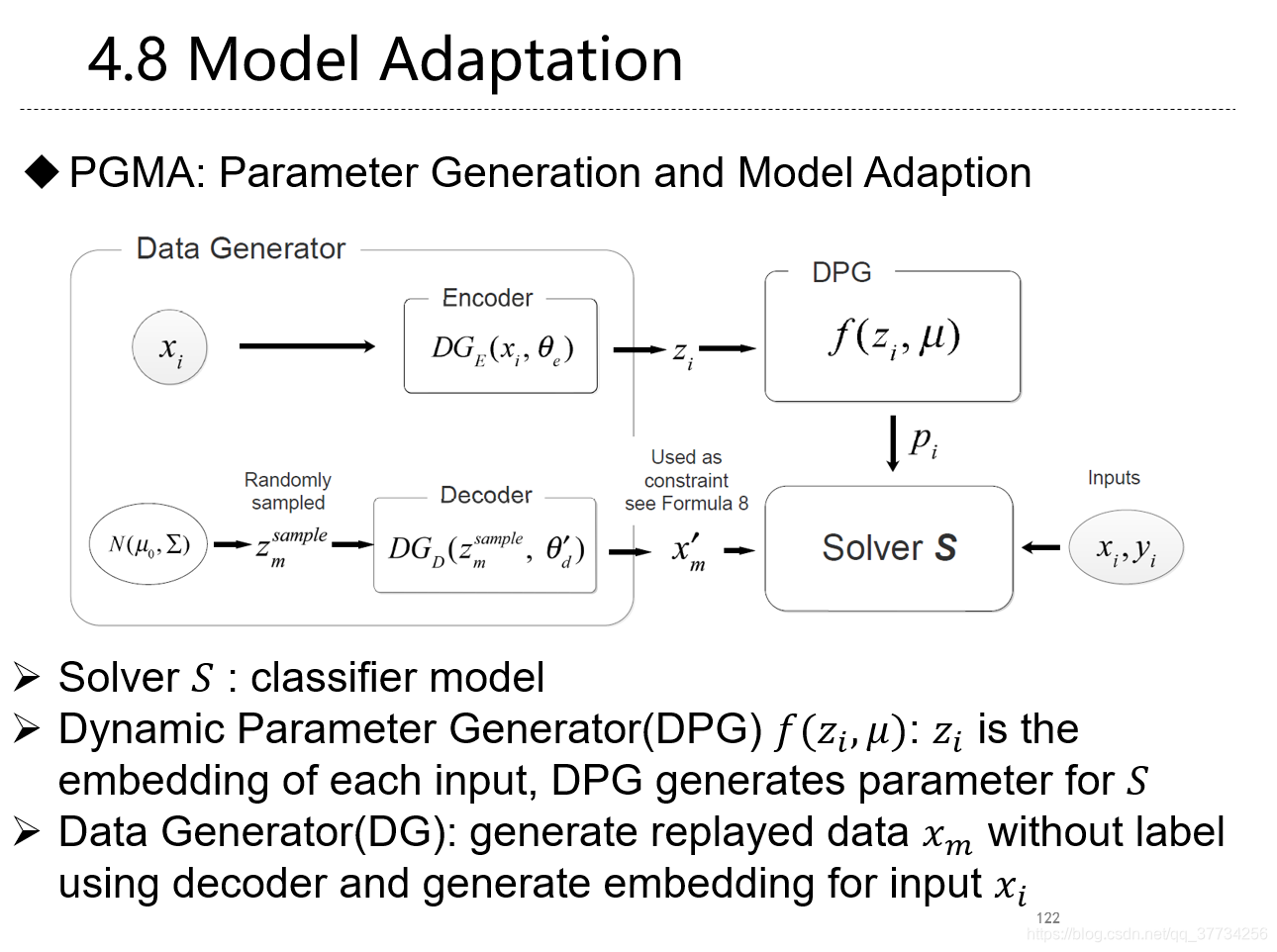
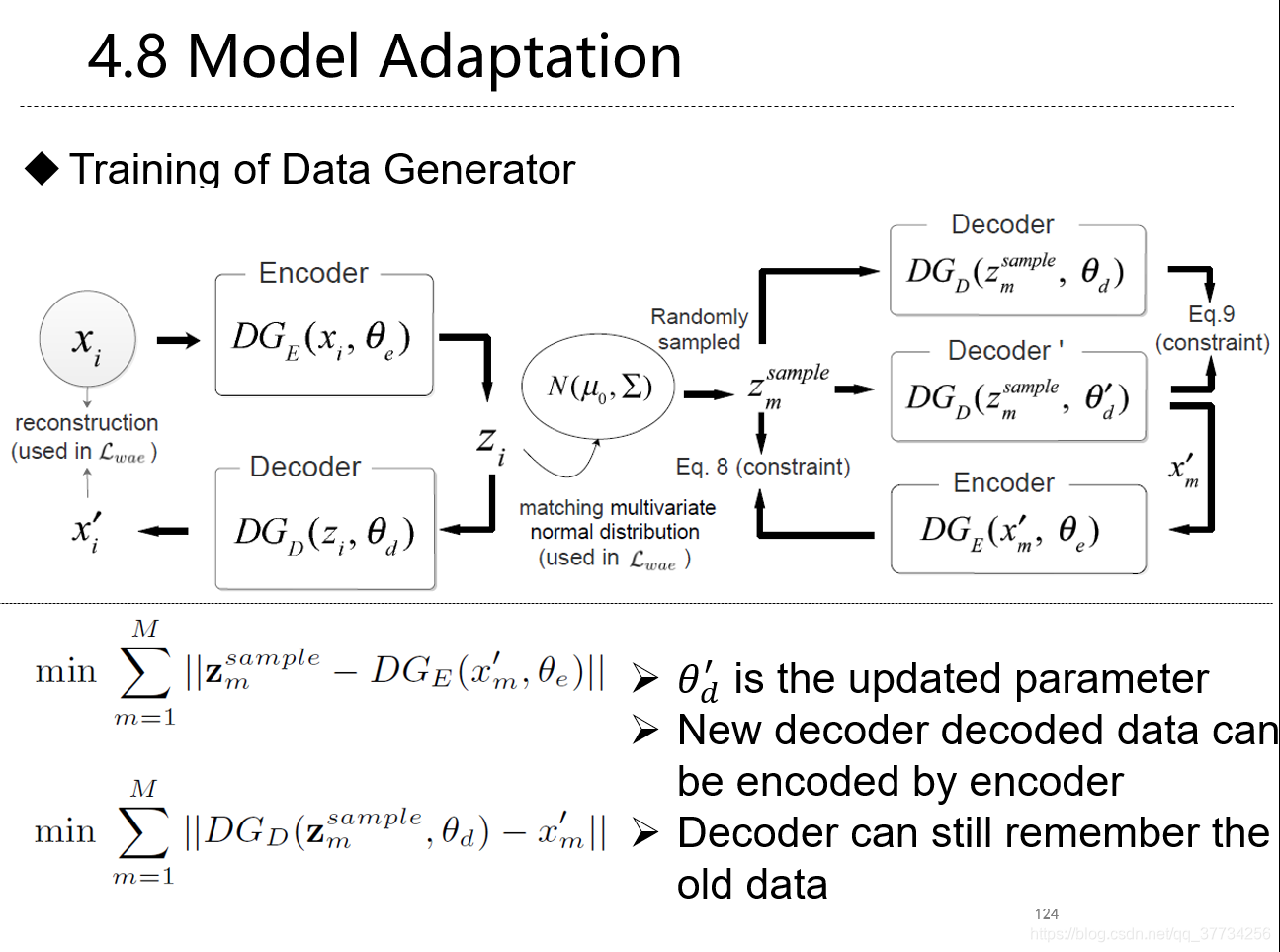
- Overcoming Catastrophic Forgetting for Continual Learning via Model Adaptation, ICLR, 2019, ���ʹ��ģ��������������ÿ��������ȷ�ȣ�ʹ���������������лطţ���ֹ������
Federated Learning and security
- Abnormal client Behavior Detection in Federated Learning, NeuIPS WorkShop, 2019, ��һƪ������������ķ������������ѧϰ���쳣�ݶȣ�ʹ���Զ��������������ǻ��ڷ����ķ�����

- SignSGD with Majority Vote is Communication Efficient and Fault Tolerant, ICLR, 2019, �����ʹ�ö���ͶƱ�ķ�ʽ�������ݶȸ��£��ݶ�λֻ��1λ��������ͨ������������³���ԡ�ͬʱ���л���Adam�������Խ�����˵����

- Exploiting Unintended Feature Leakage in Collaborative Learning, S & P, 2019, �������ѧϰ�У����������ص����Իᱻй¶�����������������й¶�Ա��Ա��������й¶���Dz��Ǵ��۾���
- Property inference attacks on fully connected neural networks using permutation invariant representations, CCS, 2018, ���������ƶϹ�����������������磬��Ϊ������Ŀ�����̫�� û�취�����ô�࣬�ֱ����Щģ��*2���ṩ1��ģ�;���ij���ԣ��������ϵͳ�����۶�©��������1��������ij���ԣ������и�©������ģ�ͣ�2��ģ�ͷֱ�ѵ���õ��ݶȣ��ݶ��ٷֱ���Ϊlabel�˵����ݣ��������ƶϹ�������������ѵ�������ʹ��DeepSet�ķ�������������n���Ŀ����Խ����˴��ѹ����
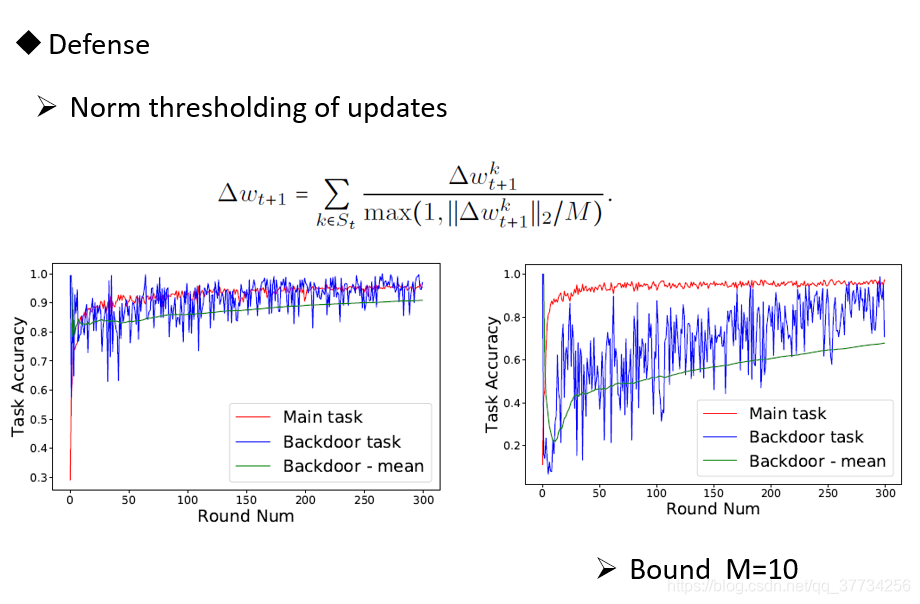
- How To Backdoor Federated Learning, CoRR, 2018, �����ģ�Ͷ�����������ѧϰ�������ݶ���������Ч�������У�ģ�Ͷ���û�к���Ч�ķ���������ͻ�������е��������������
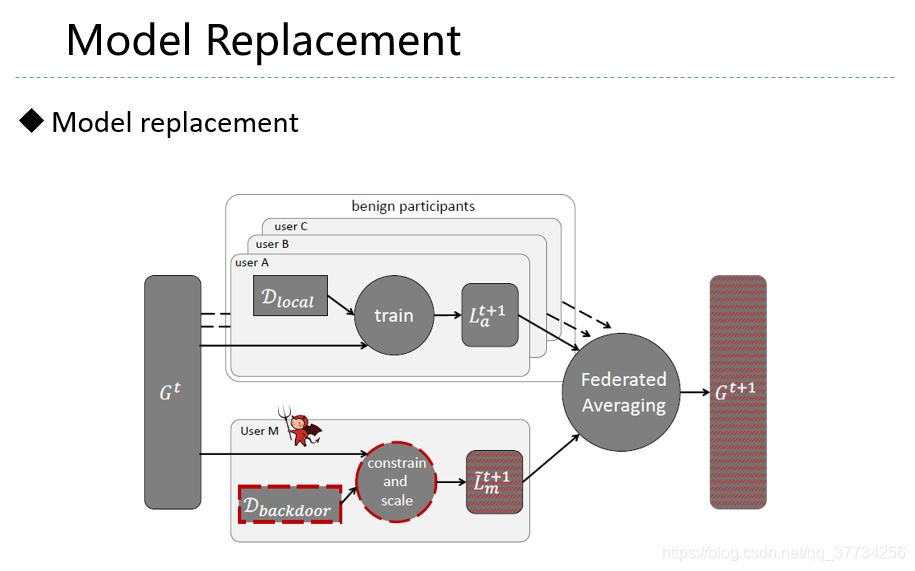
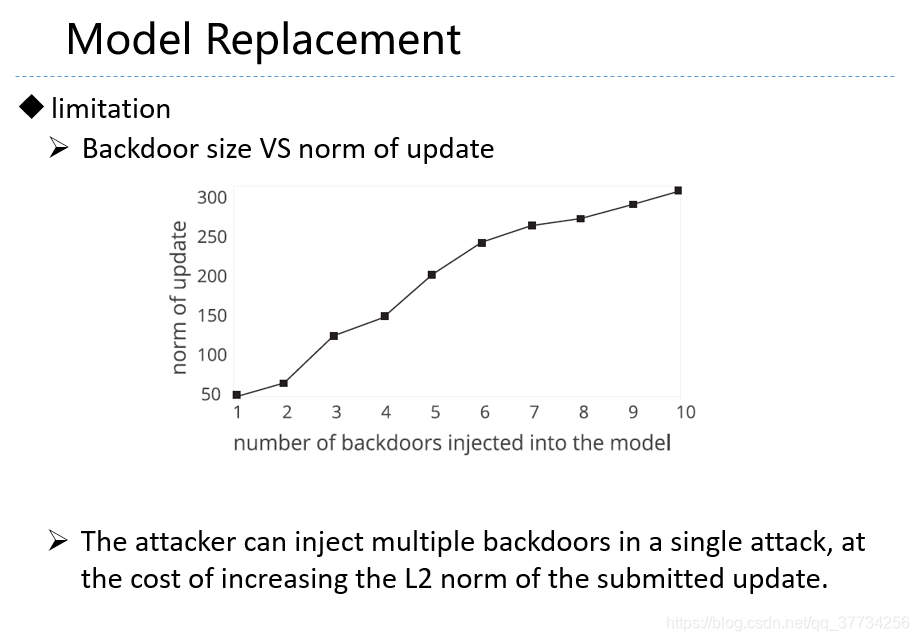
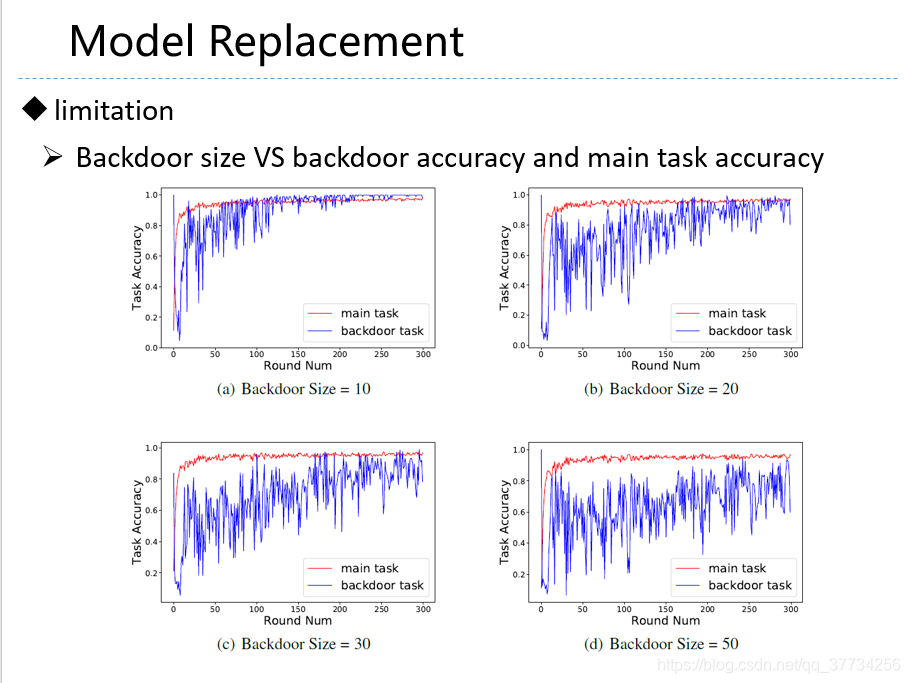
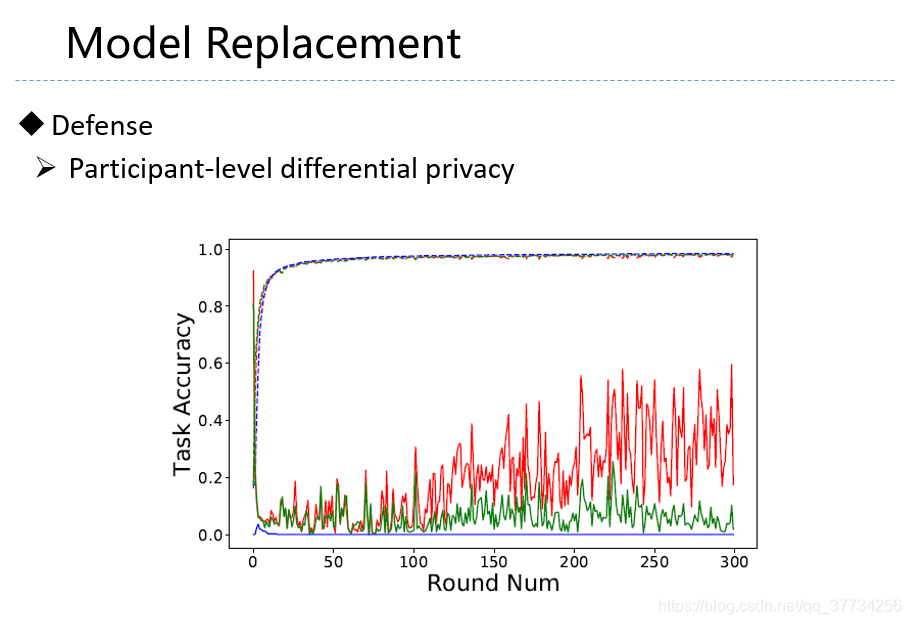
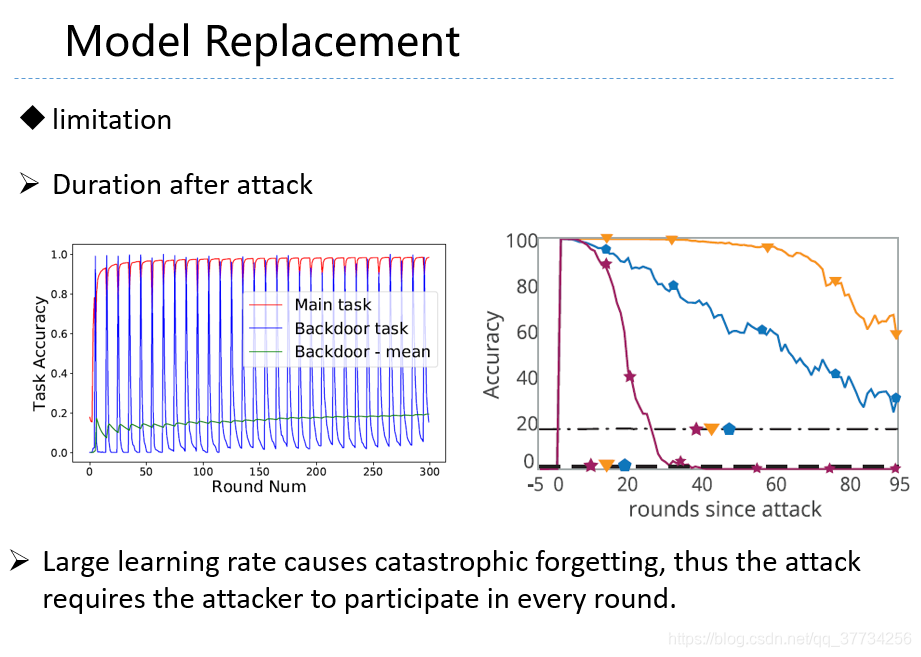
- Analyzing Federated Learning through an Adversarial Lens, ICML, 2019, �����ĵĵ�1��Ļ����ϣ���ѧϰ�ʽ��������������Ӧ���ô��ѧϰ�ʣ����ĵĵ�2��ָ���������ô��ѧϰ�ʵķ����������������ʹ����Ҫ������ѧϰģ��һֱ���й������ܱ��ֽϸߵĺ�������ȷ�ʡ�
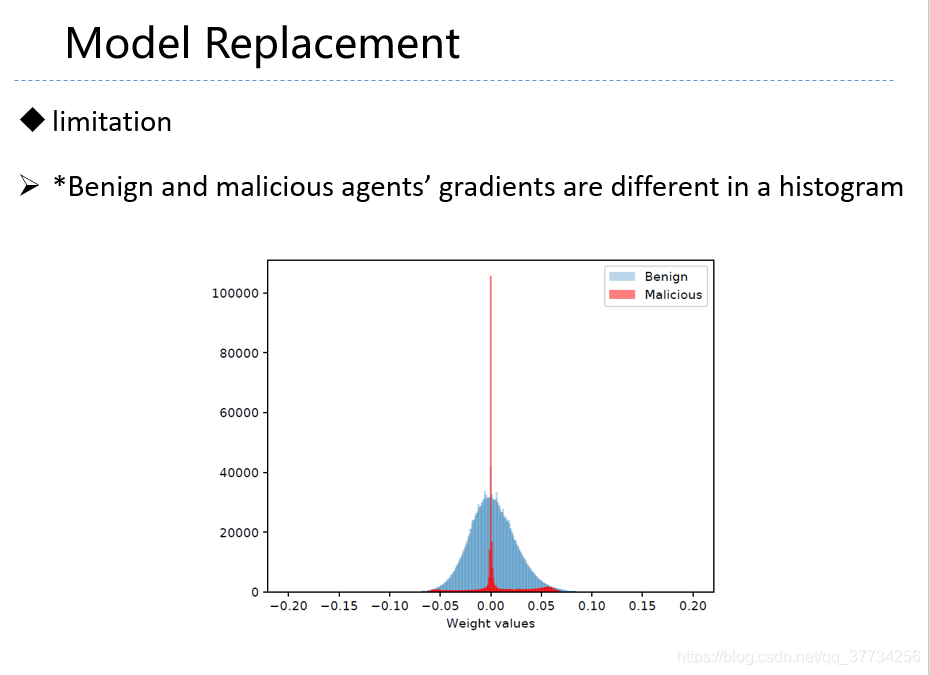
- Can You Really Backdoor Federated Learning, CoRR, 2019, ������ѧϰ���Ź��������˷�����������ʵ��ʵ�������У�ָ�������˽�ͻ����ݶȷ���ֵ�ķ������Ժ��Ź�����һ��Ч����
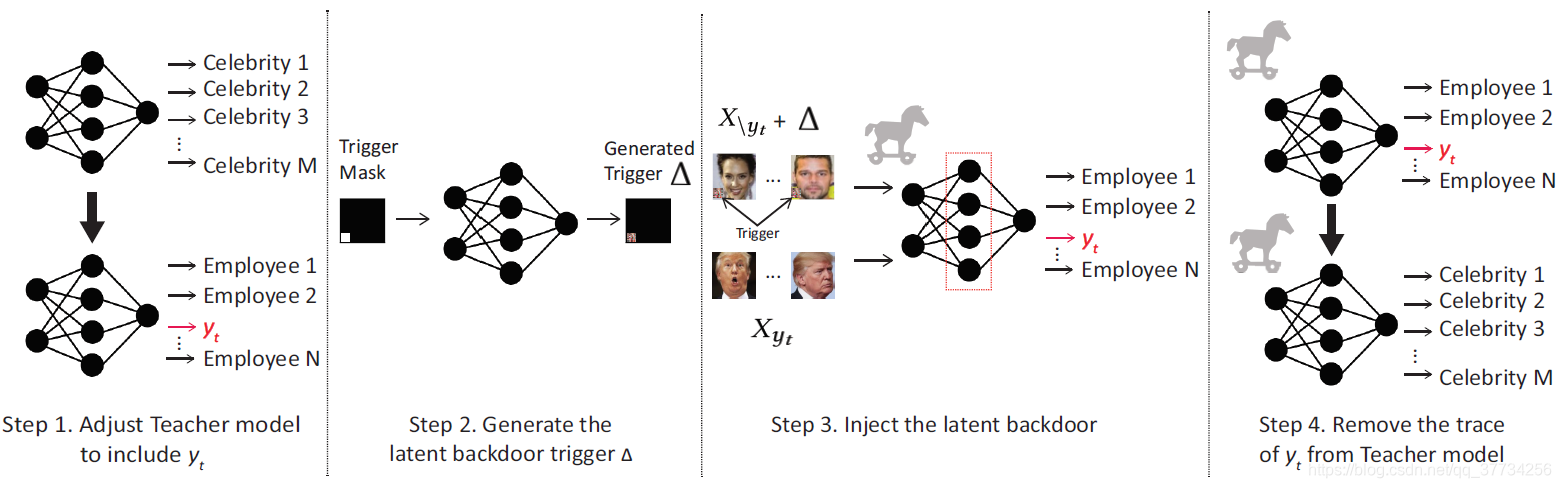
- Latent Backdoor Attacks on Deep Neural Networks, CCS, 2019, �����һ�������ŵĹ������������ģ�Ͳ�û�к��������label���Ѻ��Ų����м��ʾ�������Ը��ã����з�����������ģ��һ����Ǩ��ѧϰ��һ��Ǩ�ƺ��ģ�������к�������ı�ǩ����������ͻᱻ���

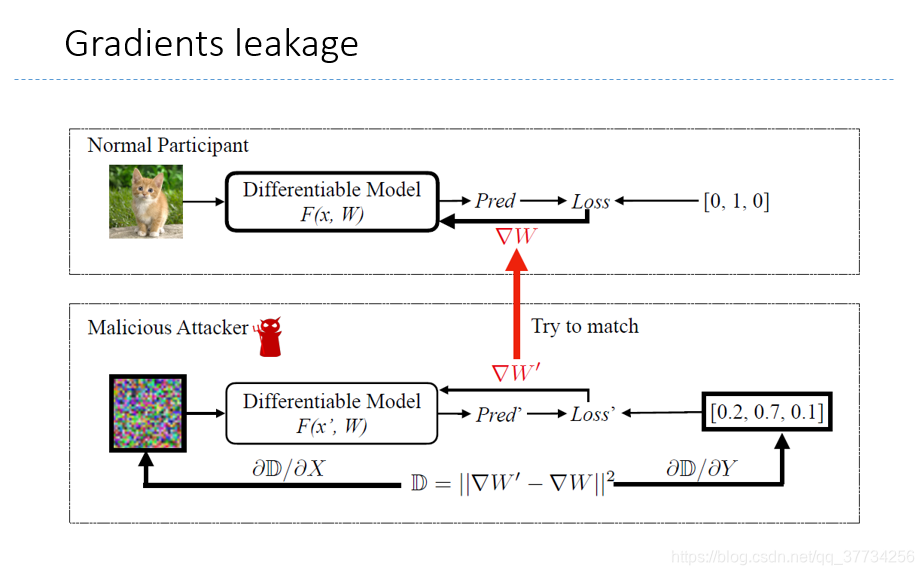
- Deep leakage from gradients, NeurIPS 2019, ���ݶ�й¶���ؼ����ͼƬ������ͨ���ݶȣ��ָ�ԭ��ͼƬ����������ѧϰ��Ӧ�û��ǻ���а�ȫ�ۺϡ�