Python���ܡ� Unix & Linux & Window & Mac ƽ̨��װ���� Python3 ��VSCode��Python������������
python����֪ʶ�����ݷ������߰�װ����ʹ��(Numpy/Scipy/Matplotlib/Pandas/StatsModels/Scikit-Learn/Keras/Gensim))
����̽����������ϴ���١������������������������е�ȱʧֵ���쳣ֵ��һ���Խ��з�����
����̽����������ϴ���ڡ�Python�������е�ȱʧֵ���쳣ֵ��һ���Խ��д���
����̽�������ݼ��ɡ����ݱ任�����ݹ�Լ���ۡ�Python�����ݹ淶����������ɢ�������Թ��졢���ɷַ��� ��ά
����̽�������������������ܡ�Python�ֲ��������Աȷ�����ͳ�������������Է��������ȷ���������Է���
�ھ�ģ�١�������Ԥ��
�ھ�ģ�ڡ�Pythonʵ��Ԥ��
�ھ�ģ�ۡ��������(��������Է������״�ͼ��)��pythonʵ��
�ھ�ģ�ܡ���������Apriori�㷨������pythonʵ��
python����֪ʶ�����ݷ������߰�װ����ʹ��(Numpy/Scipy/Matplotlib/Pandas/StatsModels/Scikit-Learn/Keras/Gensim
- ������
- ����
- ����
- �ж���ѭ��
- ѭ��
-
- while
- for
- ����
- ���ݽṹ
-
- List���б���/Tuple��Ԫ�飩
-
- �б���Ԫ��
- һЩ���������б�/Ԫ����صĺ���
- ��Ϊ������˵���б������Դ��˺ܶ�ʵ�õķ���
- Dictionary���ֵ䣩
- ����һ���ֵ�Ļ�������
- Set�����ϣ�
- ����ʽ���
- lambda
- map
- reduce
- filter
- ��ĵ���������
- Python���ݷ�������
-
- Numpy
-
- ��װ
- ʹ��
- Scipy
-
- ��װ
- ʹ��
- Matplotlib
-
- ��װ
- �����ʾ����
-
- ����
- ����
- ʹ��
- Pandas
-
- ��װ
- ʹ��
- StatsModels
-
- ��װ
- Scikit-Learn
-
- ��װ
- ʹ��
- Keras
-
- ��װ
- ʹ��
- Gensim
������
# �Ӻͼ�
print(5 + 5)
print(5 - 5)
# �˺ͳ�
print(3 * 5)
print(10 / 2)
# ָ������
print(4 ** 2)
# ȡ����
print(18 % 7)
# �������� ��������100Ԫ����ÿ��10%�Ļر���Ͷ�ʡ�����10���������ӵ�ж���Ǯ������ӡ�����
print(100 * 1.1**10)
����
���� ����������� ����ʹ����a��x Python�еı����������ִ�Сд��
height = 1.70
weight = 55
bmi = weight / height ** 2 # ���ء�����^2
print(bmi)
����
print(type(1.11)) # float
print(type(1)) # int
print(type(True)) # bool
print(type("hello")) # str
print(type("123")) # str
print(type(int("123"))) # str->int int(str)
print('12'+'34') # 1234
print(int('12')+int('34')) # 46
�ж���ѭ��
��Ҫ�ر�ָ�����ǣ�Pythonһ�㲻�û�����{}��Ҳû��end��䣬����������������Ϊ���IJ�α�ǡ�ͬһ��ε�������Ҫһһ��Ӧ��������
if ����1:���2
elif ����3:���4
else:���5
ѭ��
while
s,k = 0
while k < 101: #��ѭ�����̾�����1+2+3+...+100k = k + 1s = s + k
print s
for
s = 0
for k in range(101): #��ѭ������Ҳ����1+2+3+...+100s = s + k
print s
in��һ���dz����㡢���ҷdz�ֱ�۵���������ж�һ��Ԫ���Ƿ����б�/Ԫ���У�range�����������������У�һ���Ϊrange(a, b, c)����ʾ��aΪ���cΪ�����Ҳ�����b-1�ĵȲ����У��磺
s = 0
if s in range(4):print u's��0, 1, 2, 3��'
if s not in range(1, 4, 1):print u's����1, 2, 3��'
����
Python��def���Զ��庯����
def add2(x):return x+2
print add2(1) # ������Ϊ3
Python�ĺ�������ֵ�����Ǹ�����ʽ�����緵���б����������ض��ֵ
def add2(x = 0, y = 0): # ���庯����ͬʱ���������Ĭ��ֵreturn [x+2, y+2] # ����ֵ��һ���б�
def add3(x, y):return x+3, y+3 # ˫�ط���
a, b = add3(1,2) # ��ʱa=4,b=5
Python֧����lambda�ԼĹ��ܶ��塰���ں����������е���Matlab�еġ�������������
f = lambda x : x + 2 # ���庯��f(x)=x+2
g = lambda x, y: x + y # ���庯��g(x,y)=x+y
���ݽṹ
List���б���/Tuple��Ԫ�飩
�������Ͽ����б���Ԫ��������ǣ��б����÷����ű�ǵģ���a = [1, 2, 3]����Ԫ������Բ���ű�ǵģ���b = (4, 5, 6)�������б���Ԫ���е�Ԫ�صķ�ʽ����һ���ģ���a[0]����1��b[2]����6���ȵȡ�
c = [1, 'abc', [1, 2]]
# c��һ���б����б��ĵ�һ��Ԫ��������1���ڶ������ַ���'abc'�����������б�[1, 2]
family = ['me', 1.73, 'sister', 1.68, 'mom', 1.71, 'dad', 1.89]
# index : 0 1 2 3 4 5 6 7
# -8 -7 -6 -5 -4 -3 -2 -1
print(type(family)) # list
print(family[3]) # ȡ����Ԫ�� list_name[index]
print(family[0:2]) # ȡ������һ��Ԫ�� list_name[start:end] end ������Ԫ�ز��������ڽ����
print(family[:2]) # ʡ��ģʽ ��ͷ����ʼȡ�����������β��ʱ
print(family[-2:])
print(family[:]) # ��ʾȫ��
print(family[1:7:2]) # �����ض��IJ������ ��2��ȡ��
# ��
family[7] = 1.86
family[0:2] = ['taller_me', 1.78]
# ����
family = family + ['brother', 0.85]
# family.append("brother")
# family.append("1.79")
# ɾ��
del(family[2:4])family2 = [['me', 1.73], ['sister', 1.68], ['mom', 1.71], ['dad', 1.89]]
# index : 0 1 2 3
# -4 -3 -2 -1
print(family2[1][1])
x = ['a', 'b', 'c']
y = x
y[0] = 'd'
print(id(x)) # ��ȡ������ڴ��ַ
print(id(y))
z = list(x) # �� z = x[:]
print(id(x)) # ��ȡ������ڴ��ַ
print(id(z))
Pythonʹ�ö���ģ�����洢���ݣ��κ����͵�ֵ����һ���������ж��߱��������ԣ����ݣ�ID����ֵ��value�������ͣ�type����������б���ȻҲ�Ƕ���x��y��z�����б�������ID��������ָ������ݲ���value�����Ե�ʹ�� y = x ʱ��ֻ�ǽ�ID���д��ݣ�������ָ���ֵ��ͬһ��������ʹ�� z = list(x)�����Ǵ�����һ���µĶ���z��
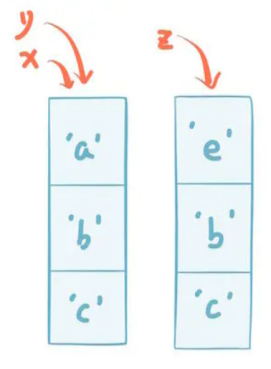
�б���Ԫ��
- �б����Ա��ģ���Ԫ�鲻���ԡ�
���磬����a = [1, 2, 3]����ô���a[0] = 0���ͻὫ�б�a��Ϊ[0, 2, 3]��
Ԫ��b = (4, 5, 6)�����b[0] = 1�ͻᱨ����
Ҫע����ǣ�����Ѿ�����һ���б�a��ͬʱ�븴��a������Ϊ����b����ôb = a����Ч�ģ���ʱ��b������a�ı���������˵���ã�����bҲ����a�ġ���ȷ�ĸ��Ʒ���Ӧ����b = a[:]��
- ���б��йصĺ�����list����Ԫ���йصĺ�����tuple�����ǵ��÷����ܼ���һ�������ǽ�ij������ת��Ϊ�б�/Ԫ�飬��list(��ab��)�Ľ����[��a��, ��b��]��tuple([1, 2])�Ľ����(1, 2)��
һЩ���������б�/Ԫ����صĺ���

��Ϊ������˵���б������Դ��˺ܶ�ʵ�õķ���

Dictionary���ֵ䣩
Python�����ˡ��ֵ䡱��һ����ĸ������ѧ����������ʵ������һ��ӳ�䡣ͨ����������Ҳ�൱��һ���б���Ȼ�����ġ��±ꡱ��������0��ͷ�����֣������Լ�����ġ�������Key����
����һ���ֵ�Ļ�������
d = {
'today':20, 'tomorrow':30}
����ġ�today����'tomorrow�������ֵ�ļ������������ֵ��б�����Ψһ�ģ���20��30���Ǽ���Ӧ��ֵ��
��������һЩ�ȽϷ���ķ���������һ���ֵ䣬��ͨ��dict()����ת��������ͨ��dict.fromkeys��������
dict([['today', 20], ['tomorrow', 30]]) # Ҳ�൱��{'today':20, 'tomorrow':30}
dict.fromkeys(['today', 'tomorrow'], 20) # �൱��{'today':20, 'tomorrow':20}
Set�����ϣ�
Python�����˼�����һ���ݽṹ������ѧ�ϵļ��ϸ����������һ�µģ������б����������ڣ�
- ����Ԫ�صIJ��ظ��ģ�����������ģ�
- ����֧��������һ������ͨ��������{}����set()����������һ�����ϣ�
s = {
1, 2, 2, 3} # ע��2���Զ�ȥ�أ��õ�{1, 2, 3}
s = set([1, 2, 2, 3]) # ͬ���أ������б�ת��Ϊ���ϣ��õ�{1, 2, 3}
���ڼ��ϵ������ԣ��ر��������ԣ�����˼�����һЩ�ر�����㣺
a = t | s # t��s�IJ���
b = t & s # t��s�Ľ���
c = t �C s # ��������t��������s��
d = t ^ s # �ԳƲ������t��s�У�������ͬʱ�����ڶ����У�
����ʽ���
����ʽ��̣�Functional programming�����ߺ���������ƣ��ֳƷ�����̣���һ�ֱ�̷��ͣ����������������Ϊ��ѧ�ϵĺ������㣬���ұ���ʹ�ó���״̬�Լ��ױ��������������ʽ�����һ�֡��㲥ʽ���ı�̣�һ����˵���ǰ���ᵽ����lambda���庯�������ڿ�ѧ�����У����Ե��ر���㡣
lambda
map
# ���б��е�ÿ��Ԫ�ض���2�õ�һ�����б�
b = [i+2 for i in a]
b = map(lambda x: x+2, a) # ���ȶ���һ��������Ȼ������map���������һӦ�õ���map���б��е�ÿ��Ԫ�أ����һ������
b = list(b) #�����[3, 4, 5]
reduce
�е���map����map������һ����������reduce���ڵݹ���㡣
# ���n�Ľ׳�
reduce(lambda x,y: x*y, range(1, n+1))
����range(1, n+1)�൱�ڸ�����һ���б���Ԫ����1~n��n��������lambda x,y: x*y������һ����Ԫ�������������������ij˻���reduce�������Ƚ��б���ͷ����Ԫ����Ϊ�����IJ����������㣬Ȼ���������������������Ϊ�����IJ�����Ȼ���ٽ�����������ĸ�������Ϊ�����IJ��������˵��ƣ�ֱ���б��������������ս����
filter
��һ��������������ɸѡ���б��з���������Ԫ��
b = filter(lambda x: x > 5 and x < 8, range(10))
b = list(b) #�����[6, 7]
ʹ��filter������Ҫһ������ֵΪbool�͵ĺ�������������lambda x: x > 5 and x < 8������һ���������ж�x�Ƿ����5��С��8��Ȼ������������õ�range(10)��ÿ��Ԫ���У����ΪTrue�����������Ǹ�Ԫ�أ������������������Ԫ�����һ���б����ء�
��ĵ���������
import math
math.sin(1) #��������
math.exp(1) #����ָ��
math.pi #���õ�Բ���ʳ���
import math as m
m.sin(1) #��������
from math import exp as e #ֻ����math���е�exp�������������e
e(1) #����ָ��
sin(1) #��ʱsin(1)��math.sin(1)�����������Ϊû������
from math import * #ֱ�ӵĵ��룬Ҳ����ȥ��math.�������������������������⣬����������������ͻ��
exp(1)
sin(1)

Python���ݷ�������
Python���������ݷ������ܲ�ǿ����Ҫ��װһЩ��������չ������ǿ����������

Numpy
Python��û���ṩ���鹦�ܡ���Ȼ�б�������ɻ��������鹦�ܣ������������������飬�������������ϴ�ʱ��ʹ���б����ٶȾͻ��������Խ��ܡ�
Ϊ�ˣ�Numpy�ṩ�����������鹦�ܣ��Լ������ݽ��п��ٴ����ĺ�����Numpy���Ǻܶ��������չ��������⣬��Scipy��Matplotlib��Pandas�ȿⶼ����������ֵ��ǿ�����ǣ�Numpy���ú����������ݵ��ٶ���C���Լ���ģ�����ڱ�д�����ʱ��Ӧ������ʹ���������õĺ���������Ч��ƿ���������������漰��ѭ�������⣩��
��װ
- pip ��װ
pip install numpy
- ��������ԨԴ���룬Ȼ��ִ�����氲װ
python setup.py install
- Linux
sudo apt-get install python-numpy
ʹ��
# -*- coding: utf-8 -*
import numpy as np # һ����np��Ϊnumpy�ı���
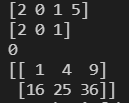
a = np.array([2, 0, 1, 5]) # ��������
print(a) # �������
print(a[:3]) # ����ǰ�������֣���Ƭ��
print(a.min()) # ���a����Сֵ
a.sort() # ��a��Ԫ�ش�С�������˲���ֱ����a�������ʱ��aΪ[0, 1, 2, 5]
b = np.array([[1, 2, 3], [4, 5, 6]]) # ����������
print(b*b) # ��������ƽ����[[1, 4, 9], [16, 25, 36]]
Scipy
Numpy�ṩ�˶�ά���鹦�ܣ�����ֻ��һ������飬�����Ǿ����統�����������ʱ��ֻ�Ƕ�ӦԪ����ˣ������Ǿ���˷���Scipy�ṩ�������ľ����Լ��������ھ�������Ķ����뺯����
SciPy�����Ĺ��������Ż������Դ��������֡���ֵ����ϡ����⺯�������ٸ���Ҷ�任���źŴ�����ͼ���������ַ�������������ѧ�빤���г��õļ��㣬��Ȼ����Щ���ܶ����ھ��뽨ģ�ر��ġ�
��װ
- pip ��װ
pip install scipy
- ubuntu
sudo apt-get install python-scipy
ʹ��
# -*- coding: utf-8 -*
# �������Է�����2x1-x2^2=1,x1^2-x2=2
from scipy import integrate # ������ֺ���
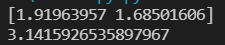
from scipy.optimize import fsolve # ������ⷽ����ĺ���def f(x): # ����Ҫ���ķ�����x1 = x[0]x2 = x[1]return [2*x1 - x2**2 - 1, x1**2 - x2 - 2]result = fsolve(f, [1, 1]) # �����ֵ[1, 1]�����
print(result) # ��������Ϊarray([ 1.91963957, 1.68501606])# ��ֵ����def g(x): # ���屻������return (1-x**2)**0.5pi_2, err = integrate.quad(g, -1, 1) # ���ֽ�������
print(pi_2 * 2) # ������֪ʶ֪�����ֽ��ΪԲ����pi��һ��
Matplotlib
Matplotlib���������Ļ�ͼ�⣬����Ҫ���ڶ�ά��ͼ����Ȼ��Ҳ���Խ��м���ά��ͼ���������ṩ��һ����Matlab���Ƶ���Ϊ�ḻ����������ǿ��Էdz���ݵ���Python���ӻ����ݣ�������������ﵽ���������Ķ���ͼ���ʽ��
��װ
- pip ��װ
pip install matplotlib
- ubuntu
sudo apt-get install python-matplotlib
�����ʾ����
����
����ͼ֮ǰ�ֶ�ָ��Ĭ������Ϊ�������壬����壨SimHei��
plt.rcParams['font.sans-serif'] = ['SimHei'] #����������������ʾ���ı�ǩ
����
������ͼͼ��ʱ�������п�����ʾ������������ͨ�����´�������
plt.rcParams['axes.unicode_minus'] = False #�������ͼ���Ǹ���'-'��ʾΪ���������
ʹ��
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt # ����Matplotlibx = np.linspace(0, 10, 1000) # ��ͼ�ı����Ա���
y = np.sin(x) + 1 # �����y
z = np.cos(x**2) + 1 # �����zplt.figure(figsize=(8, 4)) # ����ͼ���С
plt.plot(x, y, label='$\sin x+1$', color='red',linewidth=2) # ��ͼ�����ñ�ǩ��������ɫ��������С
plt.plot(x, z, 'b--', label='$\cos x^2+1$') # ��ͼ�����ñ�ǩ����������
plt.xlabel('Time(s) ') # x������
plt.ylabel('Volt') # y������
plt.title('A Simple Example') # ����
plt.ylim(0, 2.2) # ��ʾ��y�᷶Χ
plt.legend() # ��ʾͼ��
plt.show() # ��ʾ��ͼ���

Pandas
Pandas��Python����ǿ������ݷ�����̽�����ߣ�ò��û��֮һ�����������������ݽṹ�;��ɵĹ��ߣ�ʹ����Python�д������ݷdz����ٺͼ�Pandas������NumPy֮�ϣ���ʹ����NumPyΪ���ĵ�Ӧ�ú�����ʹ�á�Pandas������������������ݣ�panel data����python���ݷ�����data analysis�������������Ϊ�������ݷ������߶�������������AQR Capital Management��2008��4�¿���������2009���Դ������
Pandas�Ĺ��ܷdz�ǿ��֧������SQL����������ɾ���顢�ģ����Ҵ��зḻ�����ݴ���������֧��ʱ�����з������ܣ�֧������ȱʧ���ݣ��ȵȡ�
��װ
- pip
pip install xlrd #ΪPython���Ӷ�ȡExcel�Ĺ���
pip install xlwt #ΪPython����д��Excel�Ĺ���
���ȣ�Pandas���������ݽṹ��Series��DataFrame��Series����˼��������У�����һά���飬DataFrame�����൱��һ�Ŷ�ά�ı������ƶ�ά���飬����ÿһ�ж���һ��Series��Ϊ�˶�λSeries�е�Ԫ�أ�Pandas�ṩ��Index��һ����ÿ��Series�������һ����Ӧ��Index��������Dz�ͬ��Ԫ�أ�Index�����ݲ�һ�������֣�Ҳ��������ĸ�����ĵȣ���������SQL�е�������
���Ƶأ�DataFrame�൱�ڶ������ͬ��Index��Series����ϣ�������Series����������ÿ��Seiries������һ��Ψһ�ı�ͷ��������ʶ��ͬ��Series��
ʹ��
# -*- coding: utf-8 -*-
import pandas as pd #ͨ����pd��Ϊpandas�ı�����s = pd.Series([1,2,3], index=['a', 'b', 'c']) #����һ������s
d = pd.DataFrame([[1, 2, 3], [4, 5, 6]], columns = ['a', 'b', 'c']) #����һ����
d2 = pd.DataFrame(s) #Ҳ���������е���������������d.head() #Ԥ��ǰ5������
d.describe() #���ݻ���ͳ����#��ȡ�ļ���ע���ļ��Ĵ洢·�����ܴ������ģ������ȡ���ܳ�����
pd.read_excel('data.xls') #��ȡExcel�ļ�������DataFrame��
pd.read_csv('data.csv', encoding = 'utf-8') #��ȡ�ı���ʽ�����ݣ�һ����encodingָ�����롣
StatsModels
Pandas���������ݵĶ�ȡ��������̽������StatsModels�����ע�����ݵ�ͳ�ƽ�ģ��������ʹ��Python����R���Ե�ζ����StatsModels֧����Pandas�������ݽ�������ˣ�����Pandas��ϣ���Ϊ��Python��ǿ��������ھ���ϡ�
��װ
��װStatsModels�൱���ȿ���ͨ��pip��װ���ֿ���ͨ��Դ�밲װ������Windows�û���˵�������������Ѿ��б���õ�exe�ļ������ء�����ֶ���װ�Ļ�����Ҫ���н�����������⣬StatModel������Pandas����ȻҲ������Pandas�������ģ���ͬʱ��������pasty��һ������ͳ�ƵĿ⣩��
pip install statsmodels
Scikit-Learn
Scikit-Learn��Python��ǿ��Ļ���ѧϰ���߰������ṩ�����ƵĻ���ѧϰ�����䣬��������Ԥ���������ࡢ�ع顢���ࡢԤ�⡢ģ�ͷ����ȡ�
��װ
Scikit-Learn������NumPy��SciPy�� Matplotlib����ˣ�ֻ��Ҫ��ǰ��װ���⼸���⣬Ȼ��װScikit-Learn�ͻ�����û��ʲô�����ˣ���װ������ǰ����һ����Ҫ������pip install scikit-learn��װ��Ҫ����������Դ���Լ���װ��
pip install scikit-learn
ʹ��
- ����ģ���ṩ�Ľӿ��У�
model.fit(): ѵ��ģ�ͣ����ڼලģ����˵�� fit(X, y)�����ڷǼලģ���� fit(X) - �ලģ���ṩ��
model.predict(X_new): Ԥ��������
model.predict_proba(X_new): Ԥ����ʣ�����ijЩģ�����ã����� LR��
model.score(): �÷�Խ�ߣ�fitԽ�� - �Ǽලģ���ṩ��
model.transform(): ��������ѧ���µġ����ռ䡱��
model.fit_transform(): ��������ѧ���µĻ�����������ݰ������顰��������ת����
Keras
Scikit-Learn�Ѿ��㹻ǿ���ˣ�Ȼ������û�а���һ��ǿ���ģ�͡����˹������硣�˹��������ǹ����൱ǿ��ġ�����ԭ�����൱��ģ�ͣ������Դ�����ͼ��ʶ�����������Ҫ�����á��������������ġ����ѧϰ���㷨��������Ҳ����һ�������磬�ɼ���Python��ʵ���������Ƿdz���Ҫ�ġ�
��ʵ�ϣ�Keras���Ǽ�������⣬����һ������Theano��ǿ������ѧϰ�⣬���������������Դ��ͨ�������磬�����Դ�������ѧϰģ�ͣ����Ա�������ѭ�������硢�ݹ������硢����������ȵȡ��������ǻ���Theano�ģ�����ٶ�Ҳ�൱�졣
��װ
��װKeras֮ǰ������Ҫ��װNumpy��Scipy��Theano����װTheano������Ҫ��һ��C++������������Linux�����Դ��ġ���ˣ���Linux�°�װTheano��Keras���dz���ֻ��Ҫ����Դ���룬Ȼ����python setup.py install��װ�����ˣ�������Բο��ٷ��ĵ���
������Windows�¾�û����ô���ˣ���Ϊ��û���ֳɵı��뻷����һ��������Ȱ�װMinGW��Windows�µ�GCC��G++����Ȼ���ٰ�װTheano����ǰװ��Numpy�������⣩�����װKeras�����Ҫʵ��GPU���٣�����Ҫ��װ������CUDA������û����ѵ���ͣ���Ҫ�ٶȡ�������������ô�͵û�����˼����
ֵ��һ����ǣ���Windows�µ�Keras�ٶȻ����ۿۣ���ˣ���Ҫ�������硢���ѧϰ���������о��Ķ��ߣ�����Linux�´��Ӧ�Ļ�����
ʹ��
��Keras�������ģ�͵Ĺ����൱��࣬Ҳ�൱ֱ�ۣ�������ؾ�����ľһ�㡣���ǿ���ͨ���̶̼�ʮ�д��룬�Ϳ��Դ��һ���dz�ǿ���������ģ�ͣ����������ѧϰģ�͡���һ��MLP������֪������
Ҫע����ǣ�Keras��Ԥ�⺯����Scikit-Learn�������Keras��model.predict()�����������ʣ�model.predict_classes()������������
# -*- coding: utf-8 -*-
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.optimizers import SGDmodel = Sequential() #ģ�ͳ�ʼ��
model.add(Dense(20, 64)) #��������㣨20�ڵ㣩����һ���ز㣨64�ڵ㣩������
model.add(Activation('tanh')) #��һ���ز���tanh��Ϊ�����
model.add(Dropout(0.5)) #ʹ��Dropout��ֹ�����
model.add(Dense(64, 64)) #���ӵ�һ���ز㣨64�ڵ㣩���ڶ����ز㣨64�ڵ㣩������
model.add(Activation('tanh')) #�ڶ����ز���tanh��Ϊ�����
model.add(Dropout(0.5)) #ʹ��Dropout��ֹ�����
model.add(Dense(64, 1)) #���ӵڶ����ز㣨64�ڵ㣩������㣨1�ڵ㣩������
model.add(Activation('sigmoid')) #�������sigmoid��Ϊ�����sgd = SGD(lr=0.1, decay=1e-6, momentum=0.9, nesterov=True) #��������㷨
model.compile(loss='mean_squared_error', optimizer=sgd) #��������ģ�ͣ���ʧ����Ϊƽ�����ƽ����model.fit(X_train, y_train, nb_epoch=20, batch_size=16) #ѵ��ģ��
score = model.evaluate(X_test, y_test, batch_size=16) #����ģ��
Gensim
Gensim�������������Է�����������ı����ƶȼ��㡢LDA��Word2Vec�ȣ���Щ���������������Ҫ�Ƚ϶�ı���֪ʶ��
��Ҫһ����ǣ�Gensim��Google��2013�꿪Դ�������Ĵ��������칤��Word2Vec������ˣ���Ϊ�����ӿ⣬�����Ҫ�õ�Word2Vec�Ķ���Ҳ����ֱ����Gensim���������б����ˡ���˵Gensim�����߶�Word2Vec�Ĵ���������Ż�����������Gensim�µı��־�˵��ԭ����Word2Vec��Ҫ�졣��Ϊ��ʵ�ּ��٣���Ҫ��C++��������������ˣ������õ�Gensim��Word2Vec�Ķ�����Linux�»������С���
�ο�Python���ݷ������ھ�ʵս ������