���ĵ�ַ��https://arxiv.org/pdf/1911.09516v2.pdf
Դ�����ӣ�https://github.com/ruinmessi/ASFF
������������ʾ�ǽ��Ŀ�����г߶ȱ仯����ij��÷�����Ȼ������ͬ�����߶�֮��IJ�һ�����ǻ��������������ļ��������Ҫ���ơ���������У����������һ���µ����������Ľ����������ںϲ��ԣ���Ϊ����Ӧ�ռ������ںϣ�ASFF������ѧϰ�˿ռ���˳�ͻ��Ϣ�����Ʋ�һ���Եķ������Ӷ�����������ij߶Ȳ����ԡ��Խ����������������������еIJ�һ����
������ķ���ʹ�����ܹ�ֱ��ѧϰ�������������϶��������пռ���ˣ��Ӷ�ֻ�������õ���Ϣ������ϡ�����ijһ���������������������������ȱ����ɲ�����Ϊ��ͬ�ķֱ��ʣ�Ȼ�����ѵ�����ҵ�����ںϡ���ÿ���ռ�λ�ã���ͬ���������������Ӧ���ںϣ�Ҳ����˵��һЩ�������ܻᱻ���˵�����Ϊ�����ڸ�λ��Я��ì�ܵ���Ϣ����һЩ�������ܻ��Ը��߱����������ռ��������λ��
ASFF���������ŵ���
��1���������������ںϵIJ����Dz�ֵģ���˿��Է�����ڷ�����ѧϰ��
��2�� ��������ģ���أ������ھ��������������ṹ�ĵ���̽������
��3��ʵ�ּ����ӵļ�������С��
һ��Strong Baseline
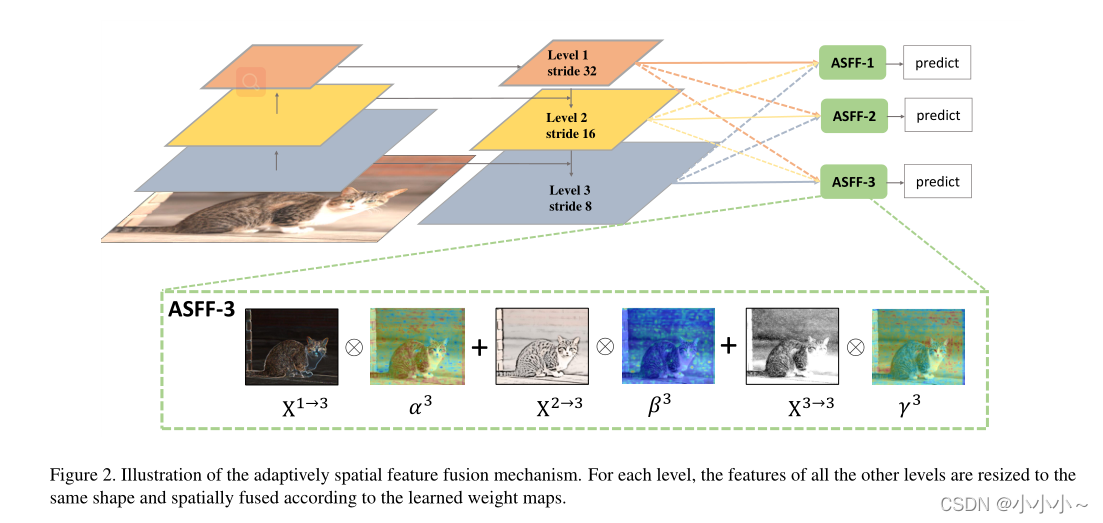
�������Ļ���Ԫ����ͻ����Ķ��������ںϷ�����ͬ�����ĵĹؼ�˼��������Ӧ��ѧϰ���߶�����ͼ�ںϵĿռ�Ȩ�ء����ͼ��ʾ���������������裺��ͬ�ij߶����ź�����Ӧ�ںϡ�
�� x l x^l xl��ʾl���ֱ��ʵ�����(l�� {1,2,3}��������l��������һ��n����N������l�������� x n x^n xn����Ϊ�� x l x^l xl��ͬ����״������YOLOv3������������������в�ͬ�ķֱ��ʺͲ�ͬ��ͨ�����������Ӧ������ÿ��������ϲ������²������ԡ������ϲ���������ʹ��1��1�����㽫������ͨ����ѹ����l����Ȼ��ͨ����ֵ�ֱ���߷ֱ��ʡ�����1/2���ʵ��²�����ֻ��ʹ��3��3�����㣬����Ϊ2������ͬʱ��ͨ�����ͷֱ��ʡ�����1/4�ı������ڲ���Ϊ2�ľ���֮ǰ������һ������Ϊ2�����ز㡣
����Ӧ�ں��� x i j n �� l x^{n��l}_{ij} xijn��l?��ʾ��n��������l��������ͼ��λ�ã�i��j������������������������Ӧ��l���ں�������������ʾ��

���У� y i j l y^l_{ij} yijl?��ʾͨ��֮���������ӳ��yl�ĵڣ�i��j���������� �� i j l ��^l_{ij} ��ijl?�� �� i j l ��^l_{ij} ��ijl?�� �� i j l ��^l_{ij} ��ijl?��������ͬ����l���������ͼ�Ŀռ���Ҫ��Ȩ�أ�����������Ӧѧϰ��ע�⣬���ͦö��Ǽı������ܵ��������� �� i j l ��^l_{ij} ��ijl?+ �� i j l ��^l_{ij} ��ijl?+ �� i j l ��^l_{ij} ��ijl?=1�� �� i j l ��^l_{ij} ��ijl?�� �� i j l ��^l_{ij} ��ijl?�� �� i j l ��^l_{ij} ��ijl?�� [0,1]�������壺

��� �� i j l ��^l_{ij} ��ijl?�� �� i j l ��^l_{ij} ��ijl?�� �� i j l ��^l_{ij} ��ijl?�ֱ��� �� �� i j l ��^l_{��_{ij}} ����ij?l?�� �� l �� i j ��^l{��_{ij}} ��l��ij?�� �� �� i j l ��^l_{��_{ij}} ����ij?l?��Ϊ���Ʋ�����ͨ��ʹ��softmax���������塣ʹ��1��1������� x 1 �� l x^{1��l} x1��l�� x 2 �� l x^{2��l} x2��l�� x 3 �� l x^{3��l} x3��l����Ȩ�ر���ӳ�� �� �� l ��^l_�� ����l?�� �� �� l ��^l_�� ����l?�� �� �� l ��^l_�� ����l?����˿���ͨ�����ķ�����ѧϰ��
ͨ�����ַ�������ÿ���߶�������Ӧ�ؾۺ����м�������������{y1��y2��y3} ����Ŀ����.
����Consistency Property
������ʽ����ASFF�ݶȼ������£�

ֵ��ע����ǣ������ߴ����ͨ��ʹ�ò�ֵ�����ϲ�����ʹ�óػ������²�������ˣ����� ? x i j 1 �� l / ? x i j 1 �� 1 ?^{1��l}_{x_{ij}}/?^1_{x_{ij}}�� 1 ?xij?1��l?/?xij?1?��1.Ϊ�˼��������ô��ʽ��3������д�ɣ�

���ڻ��ڽ����������ļ��������Ԫ����ͺͼ�������ʹ�õ����ֳ����ںϲ���������ʹ�� ? y i j 1 / ? x i j 1 = 1 ?^{1}_{y_{ij}}/?^1_{x_{ij}}= 1 ?yij?1?/?xij?1?=1�� ? x i j 1 / ? x i j 1 �� l = 1 ?^1_{x_{ij}}/?^{1��l}_{x_{ij}}= 1 ?xij?1?/?xij?1��l?=1

�������һ���ı���ƥ����ƣ���level1����λ�ã�i��j��ָ��Ϊ��������IJ��� ? L / ? y i j 1 ?L/?y^1_{ij} ?L/?yij1?�����������������ݶȡ�������Ӧ��λ��������������Ϊ������ ? L / ? y i j 2 ?L/?y^2_{ij} ?L/?yij2?�� ? L / ? y i j 3 ?L/?y^3_{ij} ?L/?yij3?�����Ը��������ݶȡ����ֲ�һ�����������ݶ� ? L / ? y i j 1 ?L/?y^1_{ij} ?L/?yij1?������ԭʼ����ӳ�� x 1 x^1 x1��ѵ��Ч�ʡ�
�����������һ�ֵ��ͷ����ǽ������������Ӧλ������Ϊ���������� ? L / ? y i j 2 ?L/?y^2_{ij} ?L/?yij2?= ? L / ? y i j 3 = 0 ?L/?y^3_{ij}=0 ?L/?yij3?=0��Ȼ�������� x i j 1 x^1_{ij} xij1?�еij�ͻ�ѱ��������� y i j 2 y^2_{ij} yij2?�� y i j 3 y^3_{ij} yij3?����ɢ�����ᵼ�¸����Ԥ�⡣
����ASFF��������ʾ��

ʽ�� �� i j 1 �� �� i j 2 �� �� i j 3 �� [ 0 , 1 ] ��^1_{ij}����^2_{ij}����^3_{ij}�� [0, 1] ��ij1?����ij2?����ij3?��[0,1]. ����������ϵ������� �� i j 2 ��^2_{ij} ��ij2?�� 0�� �� i j 3 ��^3_{ij} ��ij3?�� 0.�����ںϲ�������ͨ�����ķ����㷨ѧϰ���������õ�����ѵ�����̿��Բ�����Чϵ����ͬʱ�������Ϣ�ı����� y i j 2 y^2_{ij} yij2?�� y i j 3 y^3_{ij} yij3?���������������������
��������ѵ������
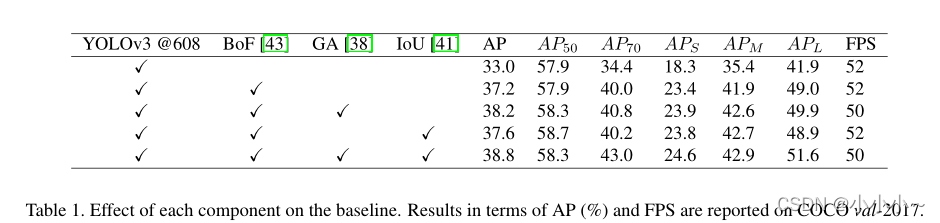
�� �� �� ����ʾ�������������������˲�����Ȩ�أ��� �� = �� �� l �� �� �� l �� �� �� l �O l = 1 �� 2 �� 3 ��={��^l_������^l_�£���^l_��| l=1��2��3} ��=����l?������l?������l?�Ol=1��2��3�ǿ���ÿ���߶ȵĿռ��ںϵ��ںϲ�������ͨ����С����ʧ���� L �� �� �� �� L�������� L�����������������Ż���������������� L L L��ԭʼYOLOv3Ŀ�꺯������anchor shapeԤ���bounding box�ع��IoU�ع���ʧ����DarkNet53�ķ���Ԥѵ��Ӧ���� mixup�������µľ����㶼������MSRAȨ�س�ʼ��������Ϊ�˼��ٹ�����ϵķ��ղ��������Ԥ��ķ�����������YOLOv3�еĶ�߶�ѵ���������������˵����N��ѵ��ͼ���С��������ΪN��3��H��W������H��W��{320��352��384��416��448��480��512��544��576��608}�����ѡȡ��
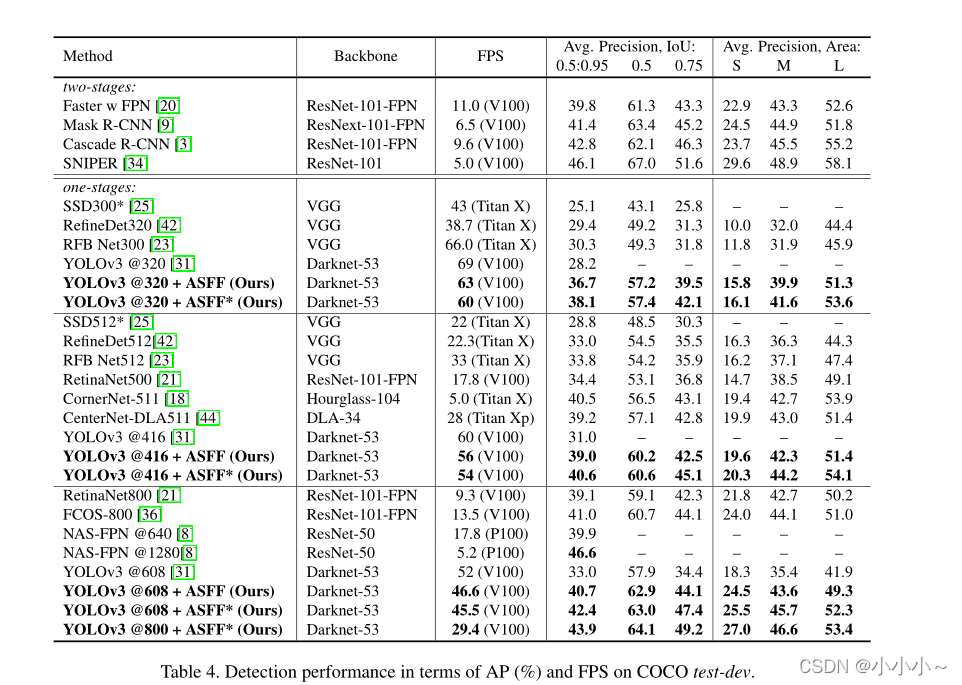
����ʵ�飺
ASSFԴ�룺
class ASFFmobile(nn.Module):def __init__(self, level, rfb=False, vis=False):super(ASFFmobile, self).__init__()# ����ASSF�ij߶ȼ���self.level = level# ��ASFF��ͬ�����ͨ������self.dim = [512, 256, 128]# ָ���ض������ͨ������self.inter_dim = self.dim[self.level]if level==0:#��ͨ��3*3����Ϊ2�ľ����˽����²������ҽ�ά��ͨ��3*3�ľ�����ͨ�����е���self.stride_level_1 = add_conv(256, self.inter_dim, 3, 2, leaky=False)self.stride_level_2 = add_conv(128, self.inter_dim, 3, 2, leaky=False)self.expand = add_conv(self.inter_dim, 1024, 3, 1, leaky=False)elif level==1:self.compress_level_0 = add_conv(512, self.inter_dim, 1, 1, leaky=False)self.stride_level_2 = add_conv(128, self.inter_dim, 3, 2, leaky=False)self.expand = add_conv(self.inter_dim, 512, 3, 1, leaky=False)elif level==2:self.compress_level_0 = add_conv(512, self.inter_dim, 1, 1, leaky=False)self.compress_level_1 = add_conv(256, self.inter_dim, 1, 1, leaky=False)self.expand = add_conv(self.inter_dim, 256, 3, 1,leaky=False)compress_c = 8 if rfb else 16 #when adding rfb, we use half number of channels to save memory#1*1�ľ���Ϊ��ͬ�ȼ���Ȩ��self.weight_level_0 = add_conv(self.inter_dim, compress_c, 1, 1, leaky=False)self.weight_level_1 = add_conv(self.inter_dim, compress_c, 1, 1, leaky=False)self.weight_level_2 = add_conv(self.inter_dim, compress_c, 1, 1, leaky=False)self.weight_levels = nn.Conv2d(compress_c*3, 3, kernel_size=1, stride=1, padding=0)self.vis= visdef forward(self, x_level_0, x_level_1, x_level_2):if self.level==0:level_0_resized = x_level_0level_1_resized = self.stride_level_1(x_level_1) #�²���������ͨ��level_2_downsampled_inter =F.max_pool2d(x_level_2, 3, stride=2, padding=1) level_2_resized = self.stride_level_2(level_2_downsampled_inter)elif self.level==1:level_0_compressed = self.compress_level_0(x_level_0)level_0_resized =F.interpolate(level_0_compressed, scale_factor=2, mode='nearest')level_1_resized =x_level_1level_2_resized =self.stride_level_2(x_level_2)elif self.level==2:level_0_compressed = self.compress_level_0(x_level_0)level_0_resized =F.interpolate(level_0_compressed, scale_factor=4, mode='nearest')level_1_compressed = self.compress_level_1(x_level_1)level_1_resized =F.interpolate(level_1_compressed, scale_factor=2, mode='nearest')level_2_resized =x_level_2level_0_weight_v = self.weight_level_0(level_0_resized)level_1_weight_v = self.weight_level_1(level_1_resized)level_2_weight_v = self.weight_level_2(level_2_resized)levels_weight_v = torch.cat((level_0_weight_v, level_1_weight_v, level_2_weight_v),1)levels_weight = self.weight_levels(levels_weight_v)levels_weight = F.softmax(levels_weight, dim=1)fused_out_reduced = level_0_resized * levels_weight[:,0:1,:,:]+\level_1_resized * levels_weight[:,1:2,:,:]+\level_2_resized * levels_weight[:,2:,:,:]out = self.expand(fused_out_reduced)#�Ƿ�Խ�����п��ӻ�if self.vis:return out, levels_weight, fused_out_reduced.sum(dim=1)else:return out