Abstract
�Կ���ѵ��������ģ�ͣ�GAN���������������ŷ���ͼ��ϳɽ�������ǣ��������ڳɹ���ʹ��GAN�����ල�ı�ʾ��ѧϰ�������Ǻܿ�ͱ��������Ҽල�ķ�����ȡ������������У����DZ���ͼ����������������ת��Ϊ����ѧϰ���ܵ���ߡ����ǵķ�����BigBiGAN�����������Ƚ���BigGANģ��֮�ϣ�ͨ�����ӱ��������ļ���������չ������ѧϰ�����ǹ㷺������ЩBigBiGANģ�͵ı�ʾѧϰ������������֤����Щ�������ɵ�ģ�Ϳ���ʵ����ImageNet�Ͻ����ල����ѧϰ�����м������Լ�������ͼ�����ɡ�
1��Introduction
�������������Ѿ������Ӿ����ݵ�����ģ�͵Ŀ��ٽ�չ����Ȼ��Щģ����ǰ�����ھ��е�ģ����ģ�Ľṹ�ṹ���ͷֱ��ʣ������Ž�ģ��Ӳ���Ľ����������Ѿ�����������ŷ������ɸ��ӣ���ģ̬���߷ֱ���ͼ��ֲ�������[1,17,19]��
ֱ�۵أ����ض������������ݵ�������Ҫ�߶���������������塣����뷨���г��ڵ�����������Ϊԭʼ���ݼȱ����ֿ��Դӻ���������Դ�������Ӧ - ���ҷḻ��ͼ���������ϢԶԶ���ڵ��͵������Ի���ѧϰģ��ѵ������Ԥ������ǩ��Ȼ������������ģ�͵Ľ����Dz��ɷ��ϵģ����Դ�����߶�����⣺��Щģ��ѧϰ��ʲô���壬�Լ�����������ڱ���ѧϰ��
����ԭʼ������Ϊ����������ֶε����ɵ����뼸��û��ʵ�֡��෴����ɹ����ලѧϰ���������˼ලѧϰ������õļ�����һ����֪�ķ��� - �ලѧϰ[3,38��35��8]����Щ����ͨ���漰��ij�ַ�ʽ�ı����ֹ���ݵ�ijЩ���棬��ѵ��ģ����Ԥ�������ȱʧ��Ϣ�ķ��档���磬[37,38]����˲�ɫ����Ϊ�ලѧϰ���ֶΣ�����ģ�ͱ���������ͼ���еIJ�ɫͨ�����Ӽ������ұ�ѵ����Ԥ�ⶪʧ��ͨ����

��Ϊ�ලѧϰ�ֶε�����ģ���ṩ�˶����Ҽල���������������������������Ϊ�����ܹ�ѵ����ģ�����������ݷֲ����������ԭʼ���ݽ����κ��ġ��Ѿ�Ӧ���ڴ�����ѧϰ��һ������ģ���������ԶԿ����磨GAN��[10]��GAN����е��������Ǵ����������DZ�ڱ�����Ҳ��Ϊ���������������ɵ����ݵ�ǰ��ӳ�䣬��һ���������ṩѧϰ�ź�������ʵ�ʺ����ɵ�����������ָ���������������ѭ���ݷֲ����Կ��ƶ�ѧϰ��ALI����˫��GAN��BiGAN����������������ΪGAN�����չ�������ʹ��һ��encoderģ�齫ʵ������ӳ�䵽DZ����������ǿ��GAN������������ѧϰ��ӳ����档
�����ż������ļ����У�[4]����ȷ����BiGAN����Ϊ�������Զ�����������С��L0�ع���ʧ;Ȼ�����ؽ�����������״�ɲ�����������������������L2��������ļ����ؼ����������ڼ�����ͨ����һ��ǿ��������磬����ϣ�����ᵼ�´������ǿ���ؽ��еġ����塱�������ǵͼ�ϸ�ڡ�
��[4]��֤���˱�����ͨ��BiGANѧϰ��ALI�����ImageNet��������������Ŀ��ӻ���ʾѧϰ����Ч������Ȼ������ʹ����DCGAN [28]��ʽ�����������ڸ����ݼ������ɸ�����ͼ����˱��������Խ�ģ����Щ��ַdz����ޡ���������У�����ʹ��BigGAN [1]��Ϊ�����������������ַ���������һ���ִ�ģ�ͣ����ƺ��ܹ�����ImageNetͼ���д��ڵ������ֽںʹֽṹ�����ǵĹ������£�
- ����֤����BigBiGAN������BigGAN��������BiGAN����ImageNet�����Ƚ����ල��ʾѧϰ��ƥ�䡣
- ����ΪBigBiGAN�����һ�����ȶ������ϼ������汾��
- ���Ƕ�ģ�����ѡ�������ȫ���ʵ֤�����������о���
- ����֤������ʾѧϰĿ��Ҳ������������ͼ�����ɣ���չʾ������ImageNet���ɵ����½����
2��BigBiGAN
BiGAN [4]��ALI [7]�����������ΪGAN [10]��ܵ���չ����ʹ���ܹ�ѧϰ������������ģ��[7]��������ʾ[4]�ı�����������һ��Px�ֲ���x�����磬ͼ��һ��Pz�ֲ���DZ��z��ͨ����һ���������ֲ��������ͬ��Gaussian N��0; I������x�������ֲ�P��x|z��DZ�������DZ�ڵ�Prior Pz���������ڱ�GAN������[10]��������Eģ���������ֲ�P��z|x���������ݷֲ�PDԤ��latentszgiven dataxsampled��
��������E��BiGAN����ж�GAN����һ���������ϼ�����D�������������� - DZ�ڶԣ�x; z�������������DZ�GAN�е�x����Ϊ���룬��ѧϰ�������ݷֲ��ͱ������еĶԣ�����������DZ�ڷֲ��������˵�����������Ƕԣ�x -Px; ^ z- E��x�����ͣ�^ x -G��z��; z -Pz��������G��E��Ŀ����ͨ�������������Ϸֲ�PxE��PGz������ƭ����������Щ�ԵIJ����������֡�[4,7]�еĶԿ��Բ���Ŀ�꣬������GAN���[10]��Ŀ�꣬��������
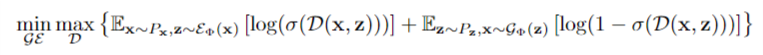
�����Ŀ���£�[4,7]������ʹ������D��G��E��С�����Ϸֲ�PxE��PGz֮���Jensen-Shannonɢ�ȣ������ȫ�����ţ��������Ϸֲ�PxE = PGzƥ�䣬�����ڱ�GAN�Ľ��[10]�����⣬[4]��������E��G����ȷ���Ժ���������ѧϰ�������ֲ�PG��x|z����PE��z|x����Dirac������������£�������������ȫ�����ŵģ����磬���з���supp��Px����x = G��E��x�������������ϼ�������Ч�������x�ع��Ľ���ɱ���
��Ȼ���ǵķ����Ĺؼ���BigBiGAN����Ȼ��BiGAN [4,7]��ͬ�������Dz��������Ƚ���BigGAN [1]����ͼ��ģ�͵ķ������ͼ������ܹ���
����֮�⣬���Ƿ��ָĽ��ļ������ṹ�����ڲ�Ӱ�����ɵ�������ṩ���õĴ�����ѧϰ�����ͼ1����Ҳ����˵������[4,7]������Ľ����ݺ�DZ�ڷֲ���ϵ��һ������ϼ�������ʧ֮�⣬������ѧϰĿ��������˶����һԪ�����Щ����������ݻ���DZ�����ݵĺ�������Ȼ[4,7]֤��ԭʼBiGANĿ���Ѿ�ǿ��˵�������Ϸֲ���ȫ������ƥ�䣬����ζ��x��zƥ��ıʷֲ�����ЩһԪ����ͨ����ȷ��ִ���������ֱ�۵������ˡ���ȷ�����Ż������磬��ͼ�����ɵ��������У�һԪ��ʧ����ԭʼGANĿ����ƥ�䣬���ṩѧϰ�źţ����źŽ������������Զ�������DZ�������ƥ��ͼ��ֲ����������ǵ������У����ǽ�ƾ����֤������Щ��������ӿ��Ը������ɺʹ�����ѧϰ����
����أ�������lossLD�ͱ����� - ������lossLEG���ǻ��ڱ������������÷֡���������Ӧ��ÿ������ʧ���������£�

��h��t��= max��0; 1 - t�������ڹ淶������[23,33] �ġ���������Ҳ����BigGAN [1]������������������ģ�飺F��H��.J��F������x��Ϊ���롢H����z�������ò���x��zѧϰ���ǵ������ͶӰ�����ҷֱ��DZ���һԪ�÷�Sx��Sz�������ǵ�ʵ���У�x����ͼ���DZ�ڵ�z���Ƿǽṹ����ƽ������;��ˣ�F��ConvNet��H��MLP����x��z�µ����ϵ÷�Sxz��ʣ���D��ģ�������J������FandH������ĺ���.
E��G�IJ������Ż�����С��lossLEG�����Ҳ������Ż�����С��lossLD��������һ�������ؿ�����Ƶ�����ֵ����С�����Ͻ��еġ�
3��Evaluation
���ǵĴ����ʵ�鶼��ѭ���������ලѧϰ�����ı�Э�飬��һ����[37]�������������δ��ǵ�ImageNet��ѵ��BigBiGAN��������ѧϰ�ı�ʾ��Ȼ�����������ѵ�����Է�������ʹ������ѵ������ǩ����ȫ��ල�����ǻ�����ͼ���������ܣ������ʼ����[31]��IS���������س�ʼ����[15]��FID����Ϊ����ı�ָ�ꡣ
3.1 Ablation
3.2 Comparison with prior methods
3.3 Reconstruction
4 Related work
�������Ҽල��ͼ�����ල��ʾѧϰ��������ѱ�֤���Ƿdz��ɹ��ġ����Ҽලͨ���漰����ij�ַ�ʽ���Ϊ�����ڼලѧϰ��������ѧϰ���������С���ǩ�������Զ��ش����ݱ��������������˹�������һ�����ڵ����������λ��Ԥ��[2]������ģ����ͼ�����������ѵ����Ԥ�����ǵ����λ�á���Ӧ��Ԥ����루CPC��[35,14]���������ط��������У�����һ��image patch��ģ��Ԥ����Щ��������������ͼ��λ�á���������������ɫ[37,38]���˶��ָ�[27]����תԤ��[8]������ƥ��[5]������������Щ�����������ϸ��ʵ֤�Ƚ�[3,21]��BigBiGAN�ṩ��һ���ؼ����ƺͻ�������ģ�͵�������������Ը����Լල�����������ǵ����������ȫ�ֱ���ͼ��������źţ�����Ҫ�ü�������������ݣ�������Щ�Ŀ����������������ǿ��������ζ�Ž����ʾͨ������ֱ��Ӧ�������������е�ȫ���ݣ������ᷢ������λ��
�������������ص��Զ���������GAN���塣����ѹ�����磨ACN��[12]ѧϰͨ������������ǰ�ڴ���ռ������ƵĴ������ݵ�������ѹ�����ݼ����𣬴Ӷ��������ԡ�ģ������������������ģ�ͣ�������BigBiGAN�ؽ���VQ-VAE [36]����ɢ��ʸ�����������������Իع��������ԣ��Ը�ѹ�����Ӳ�����ʵ���ؽ�������ǿ��ѧϰ������չʾ��ʾѧϰ������ڶԿ��Կռ��У��Կ����Զ�������[25]�����һ���Զ�������ʽ������ - �������ԣ������ؼ��ؽ��ɱ�ѵ�����ü���������VAE��ʹ�õ������KL-��ɢ����[20]������һ�������VAE-GAN���[22]�У��ڴ����VAE��ʹ�õ����ؿռ��ؽ����滻Ϊ��GAN���������м��������ռ���롣 AGE [34]��-GAN [29]��������Ϸ��������˱��������ȶ�GANѵ����������Щ������BiGAN [7,4]���֮���һ����Ȥ��������BiGANû��ѵ����������������������ȷ���ؽ��ɱ�����Ȼ����֤����Big��BiGAN�����ؽ��ؽ��ɱ���С�����������ؽ��������3.3�ڣ����������ع��ɱ����в�ͬ�ķ��ǿ�������ؼ�ϸ�ڵĸ����塣
5 Discussion
�����Ѿ�֤����BigBiGAN��һ�ִ����������ģ�͵��ලѧϰ����������ImageNet��ʵ����ͼ���ʾѧϰ�����Ƚ���������ǵ������о���һ��֤ʵ��ǿ�������ģ�Ϳ��������ڴ���ѧϰ��������ѧϰ����ģ�Ϳ��ԸĽ����ģ������ģ�͡���δ������ϣ����ʾѧϰ���Լ��������ڽ�һ���Ľ���ģ�ͺ�����ģ�ͣ��Լ���չ�������ͼ�����ݿ�.
������������������