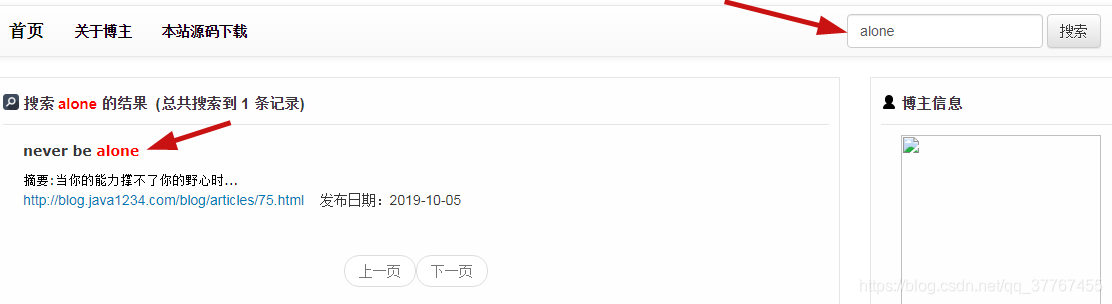
搜索效果截图:
新增一条记录时,除了数据库表数据的更新,还要额外添加索引文件:
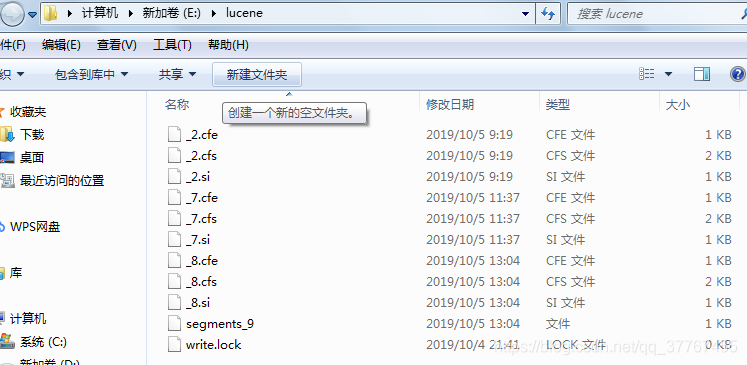
然后再查询时,就根据上面的索引来查:
一、引入依赖
<!-- 添加lucene支持 --><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId><version>5.3.1</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-analyzers-common</artifactId><version>5.3.1</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-analyzers-smartcn</artifactId><version>5.3.1</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-queryparser</artifactId><version>5.3.1</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-highlighter</artifactId><version>5.3.1</version></dependency>
二、操作索引 具体案例 代码实现
1.参考案例实体
/*** 博客实体* @author Administrator**/
public class Blog {
private Integer id; // 编号private String title; // 博客标题private String summary; // 摘要private Date releaseDate; // 发布日期private Integer clickHit; // 查看次数private Integer replyHit; // 回复次数private String content; // 博客内容private String contentNoTag; // 博客内容,无网页标签 Lucene分词用到private BlogType blogType; // 博客类型private String keyWord; // 关键字 空格隔开private Integer blogCount; // 博客数量 非博客实际属性 主要是 根据发布日期归档查询数量用到private String releaseDateStr; // 发布日期的字符串 只取年和月private List<String> imageList=new LinkedList<String>(); // 博客里存在的图片,主要用于列表展示的缩略图......
2.controller方法的处理:
/*** 添加或者修改博客信息* @param blog* @param response* @return* @throws Exception*/@RequestMapping("/save")public String save(Blog blog,HttpServletResponse response)throws Exception{
int resultTotal=0; if(blog.getId()==null){
resultTotal=blogService.add(blog);// 每新增 或修改 一条记录 同时新增或修改索引blogIndex.addIndex(blog);}else{
resultTotal=blogService.update(blog);blogIndex.updateIndex(blog);}JSONObject result=new JSONObject();if(resultTotal>0){
result.put("success", true);}else{
result.put("success", false);}ResponseUtil.write(response, result);return null;}
/*** 博客信息删除* @param ids* @param response* @return* @throws Exception*/@RequestMapping("/delete")public String delete(@RequestParam(value="ids",required=false)String ids,HttpServletResponse response)throws Exception{
String []idsStr=ids.split(",");for(int i=0;i<idsStr.length;i++){
blogService.delete(Integer.parseInt(idsStr[i]));blogIndex.deleteIndex(idsStr[i]);//执行删除操作,要把对应的索引删除,否则还是会根据索引查到数据}JSONObject result=new JSONObject();result.put("success", true);ResponseUtil.write(response, result);return null;}
/** 重点:全文搜索 高亮显示* 根据关键字查询相关博客信息*/@RequestMapping("/q")public ModelAndView search(@RequestParam(value="q",required=false) String q,HttpServletRequest request)throws Exception{
ModelAndView mav=new ModelAndView();List<Blog> blogList=blogIndex.searchBlog(q);//重点看此句对应的实现:全文搜索 mav.addObject("q", q);mav.addObject("resultTotal", blogList.size());mav.setViewName("mainTemp");return mav;}下面代码 对应上面Controller中的方法(只列出了涉及到操作索引的):
/*** 博客索引类* @author Administrator**/
public class BlogIndex {
private Directory dir;/*** 获取IndexWriter实例* @return* @throws Exception*/private IndexWriter getWriter() throws Exception{
dir=FSDirectory.open(Paths.get("E://lucene"));//打开索引文件SmartChineseAnalyzer analyzer=new SmartChineseAnalyzer();IndexWriterConfig iwc=new IndexWriterConfig(analyzer);IndexWriter writer=new IndexWriter(dir,iwc);return writer;}/*** 添加博客索引* @param blog* @throws Exception*/public void addIndex(Blog blog) throws Exception{
IndexWriter writer=getWriter();//Writer里面添加document,document里面有field列Document doc=new Document();/**添加字段; Field.Store.YES:存索引,因为后面要取索引*StringField是固定单元,使用TextField可以将长的名字分词*DateUtil.formatDate(new Date(), "yyyy-MM-dd"):将当前日期格式化为指定日期格式*/doc.add(new StringField("id",String.valueOf(blog.getId()),Field.Store.YES));doc.add(new TextField("title",blog.getTitle(),Field.Store.YES));doc.add(new StringField("releaseDate",DateUtil.formatDate(new Date(), "yyyy-MM-dd"),Field.Store.YES));doc.add(new TextField("content",blog.getContentNoTag(),Field.Store.YES));writer.addDocument(doc);writer.close();}/*** 更新博客索引* @param blog* @throws Exception*/public void updateIndex(Blog blog) throws Exception{
IndexWriter writer=getWriter();Document doc=new Document();doc.add(new StringField("id",String.valueOf(blog.getId()),Field.Store.YES));doc.add(new TextField("title", blog.getTitle(),Field.Store.YES));doc.add(new StringField("releaseDate",DateUtil.formatDate(new Date(), "yyyy-MM-dd"),Field.Store.YES));doc.add(new TextField("content",blog.getContentNoTag(),Field.Store.YES));writer.updateDocument(new Term("id",String.valueOf(blog.getId())), doc);writer.close();}/*** 删除指定博客的索引* @param blogId* @throws Exception*/public void deleteIndex(String blogId) throws Exception{
IndexWriter writer=getWriter();writer.deleteDocuments(new Term("id",blogId));writer.forceMergeDeletes();// 强制删除(合并索引片),如果不执行此步骤,索引暂时是不会被删除的writer.commit();//提交writer.close();}/*** 查询博客信息* @param q* @return* @throws Exception*/public List<Blog> searchBlog(String q) throws Exception{
dir =FSDirectory.open(Paths.get("E://lucene"));IndexReader reader=DirectoryReader.open(dir);//打开索引目录IndexSearcher is=new IndexSearcher(reader);//IndexSearcher用来查询索引BooleanQuery.Builder booleanQuery=new BooleanQuery.Builder();SmartChineseAnalyzer analyzer=new SmartChineseAnalyzer();QueryParser parser=new QueryParser("title", analyzer);Query query=parser.parse(q);//解析查询条件 将 输入的查询条件与博客标题匹配QueryParser parser2=new QueryParser("content",analyzer);Query query2=parser2.parse(q);//解析查询条件 将输入的查询条件与所有博客内容匹配//BooleanClause.Occur.SHOULD:表明条件之间是或的关系,只要满足条件都拉过来booleanQuery.add(query,BooleanClause.Occur.SHOULD);booleanQuery.add(query2, BooleanClause.Occur.SHOULD);//多条件查询 is.search(查询的条件,查询记录数) 得到最佳得分TopDocs hits=is.search(booleanQuery.build(), 100);QueryScorer scorer=new QueryScorer(query);//计算得分/** 对得分高的片段高亮显示*/Fragmenter fragmenter=new SimpleSpanFragmenter(scorer);//根据得分生成片段SimpleHTMLFormatter simpleHTMLFormatter=new SimpleHTMLFormatter("<b><font color='red'>", "</font></b>");Highlighter highlighter=new Highlighter(simpleHTMLFormatter,scorer);highlighter.setTextFragmenter(fragmenter);//为片段设置高亮List<Blog> blogList=new LinkedList<Blog>();for(ScoreDoc scoreDoc:hits.scoreDocs) {
Document doc=is.doc(scoreDoc.doc);//scoreDoc.doc:获取docId,通过id获取塞进去的docBlog blog =new Blog();blog.setId(Integer.parseInt(doc.get("id")));blog.setReleaseDateStr(doc.get("releaseDate"));/** 对 title 和 content单独特殊处理*/String title=doc.get("title");//过滤掉html标签String content=StringEscapeUtils.escapeHtml(doc.get("content"));if(title!=null) {
//把title读进去然后解析TokenStream tokenStream=analyzer.tokenStream("title", new StringReader(title));//得到最佳的片段String hTitle=highlighter.getBestFragment(tokenStream, title);if(StringUtil.isEmpty(hTitle)) {
blog.setTitle(title);}else {
blog.setTitle(hTitle);}}if(content!=null) {
TokenStream tokenStream=analyzer.tokenStream("content", new StringReader(content));String hContent=highlighter.getBestFragment(tokenStream, content);if(StringUtil.isEmpty(hContent)) {
if(content.length()<=200) {
blog.setContent(content);}else {
blog.setContent((String) content.subSequence(0, 200));}}else {
blog.setContent(hContent);}}blogList.add(blog);}return blogList;}}import java.io.StringReader;
import java.nio.file.Paths;
import java.util.Date;
import java.util.LinkedList;
import java.util.List;import org.apache.commons.lang.StringEscapeUtils;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.BooleanClause;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.highlight.Fragmenter;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.QueryScorer;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
import org.apache.lucene.search.highlight.SimpleSpanFragmenter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;import com.java1234.entity.Blog;
import com.java1234.util.DateUtil;
import com.java1234.util.StringUtil;