Tell Me Where to Look: Guided Attention Inference Network
-------告诉我看向哪里:引导注意推理网络 (收录于CVPR-2018),论文是依据于Ramprasaath R. Selvaraju的Grad-CAM:Visual Explanations from Deep Networks via Gradient-based Localization
-
摘要:
Weakly supervised learning with only coarse labels can obtain visual explanations of deep neural network such as attention maps by back-propagating gradients. These attention maps are then available as priors for tasks such as object localization and semantic segmentation. In one common framework we address three shortcomings of previous approaches in modeling such attention maps: We (1) first time make attention maps an explicit and natural component of the end-to-end training, (2) provide self-guidance directly on these maps by exploring supervision form the network itself to improve them, and (3) seamlessly bridge the gap between using weak and extra supervision if available. Despite its simplicity, experiments on the semantic segmentation task demonstrate the effectiveness of our methods. We clearly surpass the state-of-the-art on Pascal VOC 2012 val. and test set. Besides, the proposed framework provides a way not only explaining the focus of the learner but also feeding back with direct guidance towards specific tasks. Under mild assumptions our method can also be understood as a plug-in to existing weakly supervised learners to improve their generalization performance.仅使用(粗标签的)弱监督学习可以获得深度神经网络的视觉解释,例如通过反向传播梯度的注意力图。这些注意力图可用作对象定位和语义分割等任务的先验。在同一个框架中,我们解决了此类注意力图方法的三个缺点:(1)我们第一次将注意力映射作为明确和自然组成部分用于端到端训练,(2)通过探索监督,在这些注意力图上提供自我指导并不断提高,以及(3)弥合使用弱监督和额外监督(如果可用)之间的差距。尽管它很简单,但语义分割任务的实验证明了我们方法的有效性。我们明显超越了Pascal VOC 2012 val的最新技术水平。此外,拟议的框架不仅提供了解释学习者关注点的方法,而且还提供了对特定任务的直接指导。在正常假设下,我们的方法也可以被理解为现有弱监督学习者的插件,以提高他们的泛化性能。
-
introduction
弱监督学习作为解决计算机视觉中标记数据缺乏的一种流行解决方案,最近受到了广泛关注。例如,仅使用图像级标签,就可以在卷积神经网络(CNN)上获得给定输入的反向传播注意图。这些图与网络的响应有关,给定特定的模式和训练任务。注意力图上每个像素的值显示了输入图像上相同像素对网络最终输出的贡献程度。研究表明,不需要额外的标记,就可以从这些注意力图中提取定位和分割信息。
然而,仅通过分类损失监督,注意力图通常仅覆盖感兴趣对象小且最具辨别力的区域。 虽然这些注意力图仍然可以作为分割等任务的可靠先验,但是尽可能完整地覆盖目标前景物体的注意力图可进一步提高性能。 为此,最近的一些工作要么依赖于通过( iterative erasing steps )迭代擦除步骤从网络工作中组合多个注意力图,要么整合来自多个网络的注意力图[11]。 我们设想了一个端到端的框架,而不是被动地利用训练有素的网络注意力,在训练阶段,可以将任务特定的监督直接应用于注意力图。
我们的贡献是:(a)在学习弱标签任务的同时,在训练期间直接在注意力图上使用监督的方法; (b)培训期间的自我指导计划,迫使网络将注意力集中在整体上,而不仅仅是最感兴趣部分; (c)将直接监督和自我指导结合起来,从仅使用弱标签到在一个共同框架内使用全面监督进行无缝扩展。
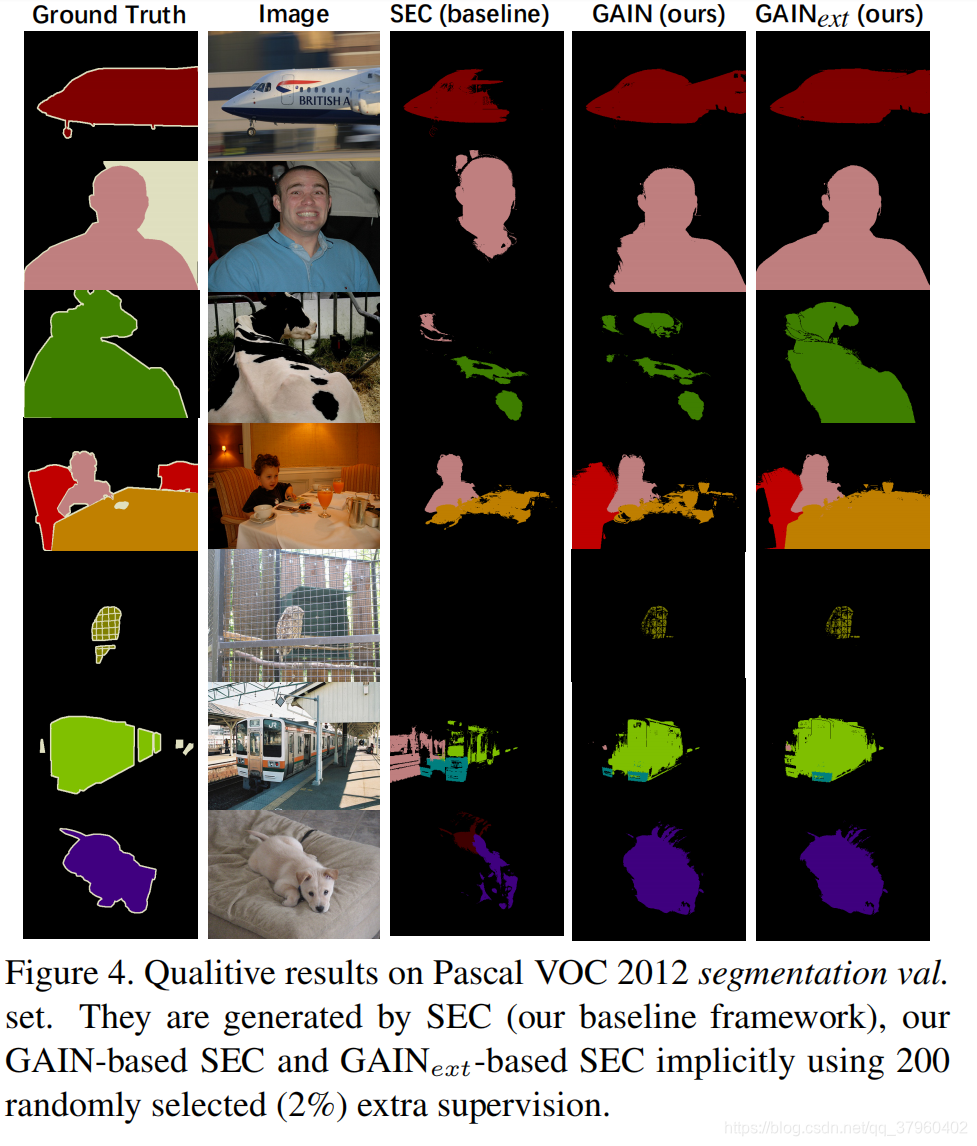
使用语义分割作为感兴趣的任务的实验表明,我们的方法分别在PASCAL VOC 2012分割基准的val和测试上达到了55.3%和56.8%。 当在训练中使用有限的像素级监督时,它也有信心地超过了可比较的现有技术,其中mIoU分别为60.5%和62.1%。 据我们所知,这些是在监督不力的情况下最新的最新成果
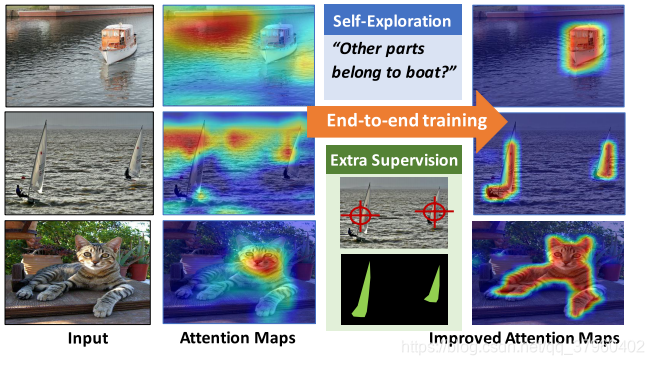
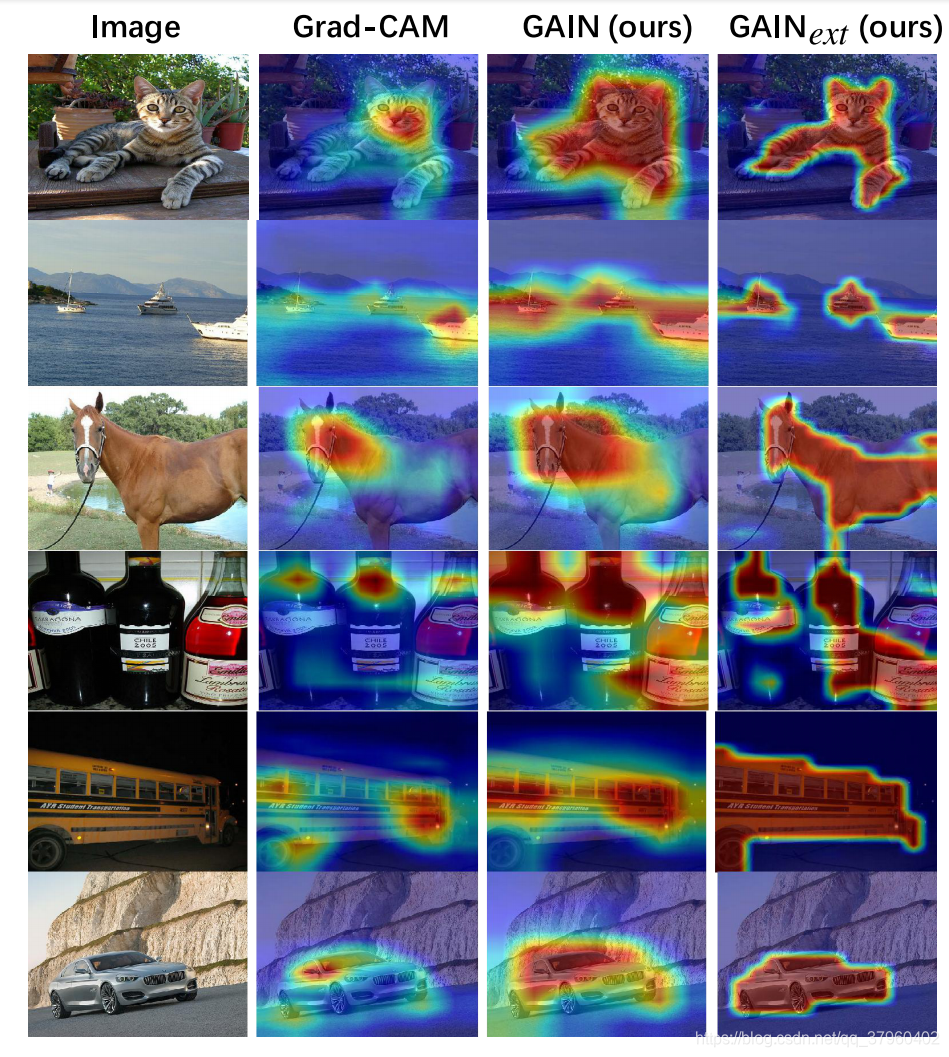
所提出的引导注意推理网络(GAIN)使得网络的注意力可以在线训练,并且可以以端到端的方式直接在注意力图上插入不同类型的监督。 我们从网络本身探索自我监督,并在有额外监督时提出GAINext。 这些指导可以优化针对感兴趣的任务的注意力图。图1显示了“船”,其中水可作为具有高相关性的干扰物。 在这种情况下,训练并不会将注意力仅集中在前景类上,并且当测试数据不具有相同的相关性(“船只离开水”)时,泛化性能可能受到影响。 虽然已经尝试通过重新平衡训练数据来消除这种偏见,但我们建议将注意力图明确地建模为训练的一部分。 作为这样做的一个好处,我们能够明确地控制注意力, 这样做的一个好处是,我们能够明确地控制注意力,并且可以手动提供对注意力的最小监督,而不是重新平衡数据集。 虽然并不清楚如何手动平衡数据集以避免偏差,但通常可以直接引导对感兴趣区域的关注。 我们还观察到,即使没有额外的监督,我们的自我引导注意模型也已经提高了泛化性能。
- 提出的模型GAIN
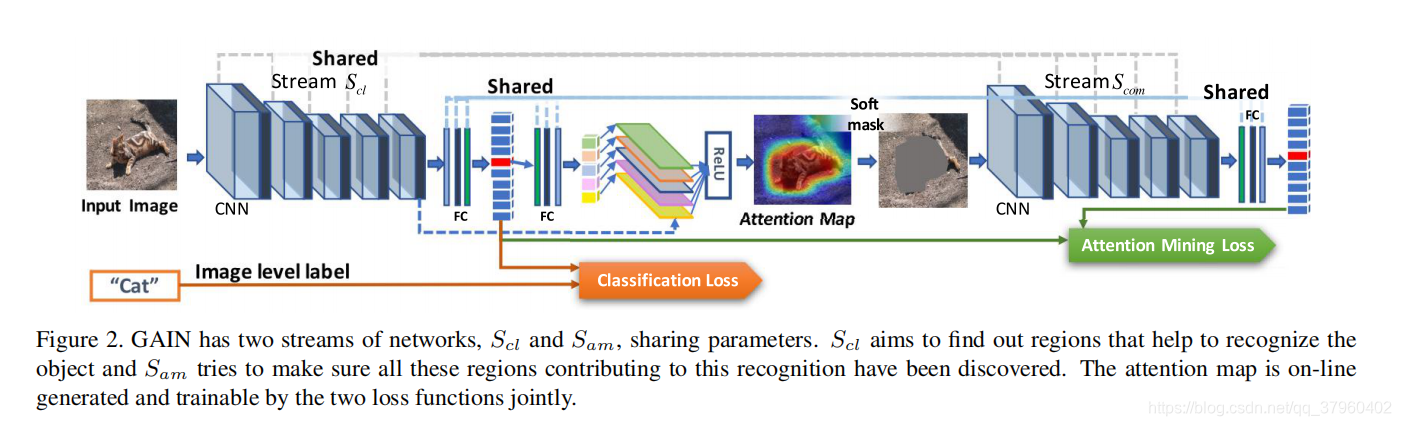
图2. GAIN有两个网络流,Scl和Sam,共享参数。 Scl的目的是找出有助于识别物体的区域,Sam试图确保所有这些有助于识别的区域都被发现。 注意图由两个损失函数联合生成和训练。这里的关键是我们使注意力图可以通过两个损失函数联合生成和训练,通过后向传播得到的W。
(通过偏导求出W权重)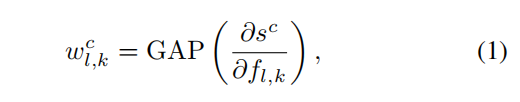
GAP表示全局平均磁化,这里就是一般卷积神经网络求参数的过程,所求出的参数Wc并不急于通过后向传播在网络中应用。利用得到的Wc和最后一层feature_map fl做卷积运算,得到的Ac就是attention_map,公式如下
(注意力图与卷积特征图具有相同的大小) 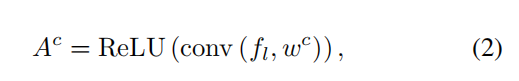
在得到注意力图Ac之后,作者要用这个Ac对原始输入图片进行掩盖(soft mask),通过公式
(I表示此刻网络关注的区域()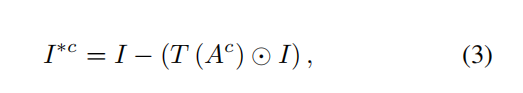
T(Ac)是基于阈值处理操作的掩蔽函数。 为便于导出,我们使用Sigmoid函数作为方程式中定义的近似值-公式4。
(σ是阈值矩阵,w是比例参数)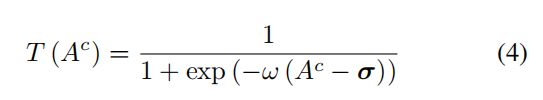
w的目的是保证当Ac大于σ时,Ac近似于1;或者为0,I c用来当做Sam的输入来获取预测分数。 由于我们的目标是引导网络专注于所感兴趣区域的所有部分(比如识别水上的船,关注在船而不是水),因此我们强制执行I * c以尽可能少地包含属于目标类的特征(水)。
Lam就是关于Ic的预测分数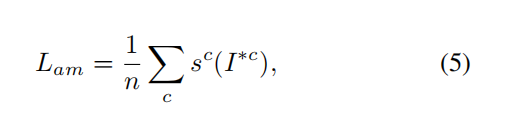
定义了loss函数,两部分的损失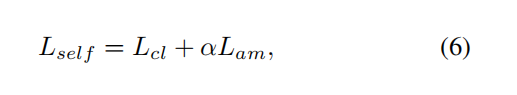
其中Lcl用于多标签和多类别分类,我们在这里使用多标签multi-label soft margin loss。 替代损失函数可用于特定任务。 α是加权参数,在实验中使用α= 1。
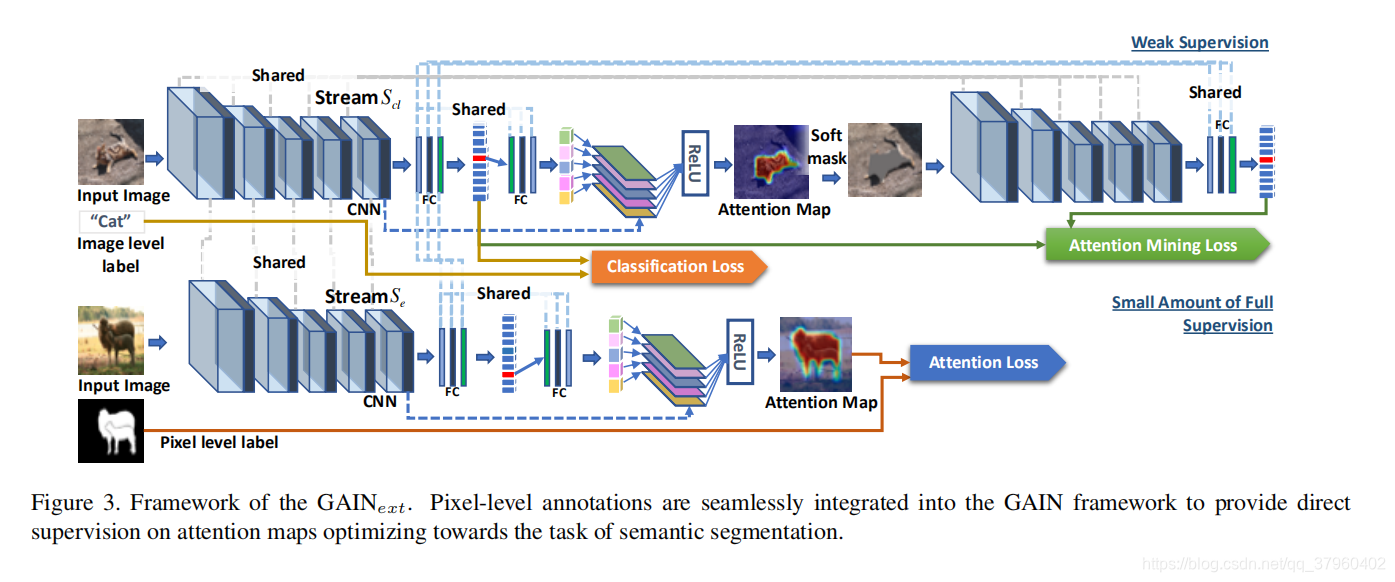
像素级注释集成到GAIN框架中,以直接监控注意力图,优化语义分割任务。
3.2. GAIN: integrating extra supervision
除了让网络自己探索注意力图的指导之外,我们还可以通过使用少量的额外监督来控制注意力图学习过程,从而定制网络中应该关注图像的哪个部分。作者将之前的注意力机制的方法称为弱监督学习(weak supervision),作者提出在弱监督学习的基础上添加了基于pixel-level图像分割数据的监督部分,这部分的损失为
Hc表示额外监督(extra supervision)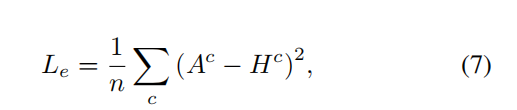
在图三中。我们添加外部流Se并共享所有参数。 流Se的输入图像包括图像级标签和像素级分割掩模。
(8)是最终的loss公式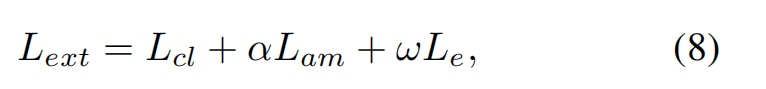
w是权重,决定我们对额外监督的重视程度(论文中取w=10)
4.语义分割实验
4.1:数据集和实验参数设置
我们根据PASCAL VOC 2012图像分割基准评估我们的结果,使用VGG作为基本网络来得到注意图,使用pytorch语言。
实验结果: