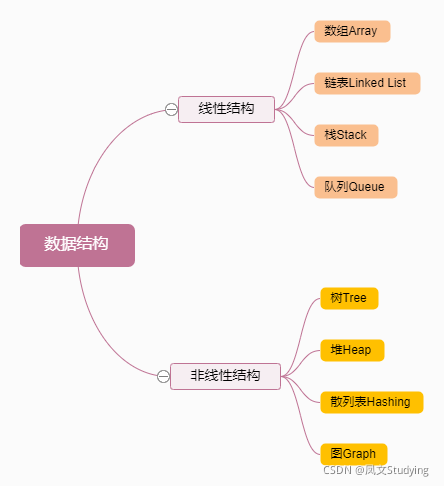
数据结构
- 数据结构介绍
-
- 常见数据结构
- 抽象数据类型(ADT)
- 线性结构
-
- 数组(Array)
- 链表(Linked List)
- 栈(Stack)
- 队列(Queue)
- 非线性结构
-
- 树(Tree)
- 堆(Heap)
- 散列表(Hashing)
- 图(Graph)
数据结构介绍
数据结构是为实现对计算机数据有效使用的各种数据组织形式,服务于各类计算机操作。
概念这么给的,其实我觉得还有点抽象,,就拿我们生活中的楼来讲,它为什么是向上堆上去的,它咋不散开来盖房呢?在这个拥挤的城市里,要想容纳更多的人住在这,那自然要这么建了。而楼一定有完善的结构才能实现稳定和大容量。
同样的,我们的计算机的内存的容量跟城市一样是空间有限的,用于运算的大量的数据当然需要有一个排列的结构才能更好的发挥内存的性能。
所以,数据结构旨在降低各种算法计算的时间与空间复杂度,以达到最佳的任务执行效率。
常见数据结构
常见的数据结构可分为「线性数据结构」与「非线性数据结构」,具体为:「数组」、「链表」、「栈」、「队列」、「树」、「图」、「散列表」、「堆」。
每一种数据结构都有着独特的数据存储方式,也有它们的各自的结构和优缺点。
抽象数据类型(ADT)
抽象数据类型(abstract data type,ADT)是带有一组操作的一些对象的集合。
首先它是一些对象的集合,这里的对象就是某个数据类型对应的具体值,如int,string都叫数据类型,而这个具体值,比如3,“医信”,这些具体的数值和字符都可以叫作对象。由于部分学弟学妹还刚接触甚至不了解面向对象相关知识,所以这里解释得这么详细。
其次它带有一组操作,在ADT的定义中没有地方提到关于这组操作是如何实现的任何解释。拿集合来说,可以有像添加(add)、删除(remove)以及包含(contain)这样一些操作。再比如链表,使链表的容量增加或减少,使添加一个元素或减少一个元素,使某两个元素换一下位置,这些针对同一链表的操作合起来就可以称作一组操作。
所以,诸如表、数组、集合、图等数据结构以及它们各自的操作一起形成的这些对象都可以被看做是抽象数据类型,这就像整数、实数、布尔数都是数据类型一样。最后我自己总结就是 ADT=某一种数据结构+对应的操作集合。
线性结构
线性结构是什么?
数据结构中线性结构指的是 数据元素之间存在着“一对一”的线性关系的数据结构。 线性结构是一个有序数据元素的集合。
这里的一对一关系意思是,每一个元素之间是首尾相接的,字面意思就是元素之间连成一条线。 当然,第一个元素和最后一个元素就不能连在一起了,否则就成了一个环了。
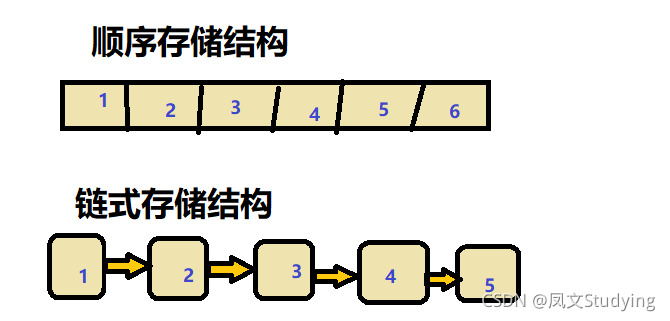
以上这两个都是线性结构,顺序表的数据在内存中的存储是连续的(靠在一起的,如数组就是这个特点),而链表的存储不一定是连续的,每个元素依靠自身节点中存放的相邻元素的地址信息来找到下一个元素。需要知道的是,不管是顺序存储还是链式存储都是元素之间连成一条线。
那么总结一下线性结构的特点:
线性结构有唯一的首元素(第一个元素)
线性结构有唯一的尾元素(最后一个元素)
除首元素外,所有的元素都有唯一的“前驱”
除尾元素外,所有的元素都有唯一的“后继”
数据元素之间存在“一对一”的关系,即除了第一个和最后一个数据元素之外,其它数据元素都是首尾相接的。
数组(Array)
数组是可以再内存中连续存储多个元素的结构,在内存中的分配也是连续的,数组中的元素通过数组下标进行访问,数组下标从0开始。
代码实现:
// 初始化一个长度为 5 的数组 array
int[] array = new int[5];
// 元素赋值
array[0] = 2;
array[1] = 3;
array[2] = 1;
array[3] = 0;
array[4] = 2;
优点:
1、按照索引访问元素速度快
2、按照索引遍历数组方便
缺点:
1、数组的大小固定后就无法扩容了
2、数组只能存储一种类型的数据
3、添加,删除的操作慢,因为要移动其他的元素。
就比如,你想要在索引为0的位置(首位置)添加一个元素,由于数组大小固定无法直接扩容,你只能创建一个比原数组容量大一个空间的新数组,然后把第一个数组放进去,再把原数组的元素挨个放到新数组里面。这一套过程下来,速度慢的一批!等会你看到链表的介绍你就会发现链表在这方面的优势。
适用场景:
频繁查询,对存储空间要求不大,很少增加和删除的情况。
链表(Linked List)
链表是物理存储单元上非连续的、非顺序的存储结构(链式),数据元素的逻辑顺序是通过链表的指针地址实现,每个元素包含两个结点,一个是存储元素的数据域 (内存空间),另一个是指向下一个结点地址的指针域。
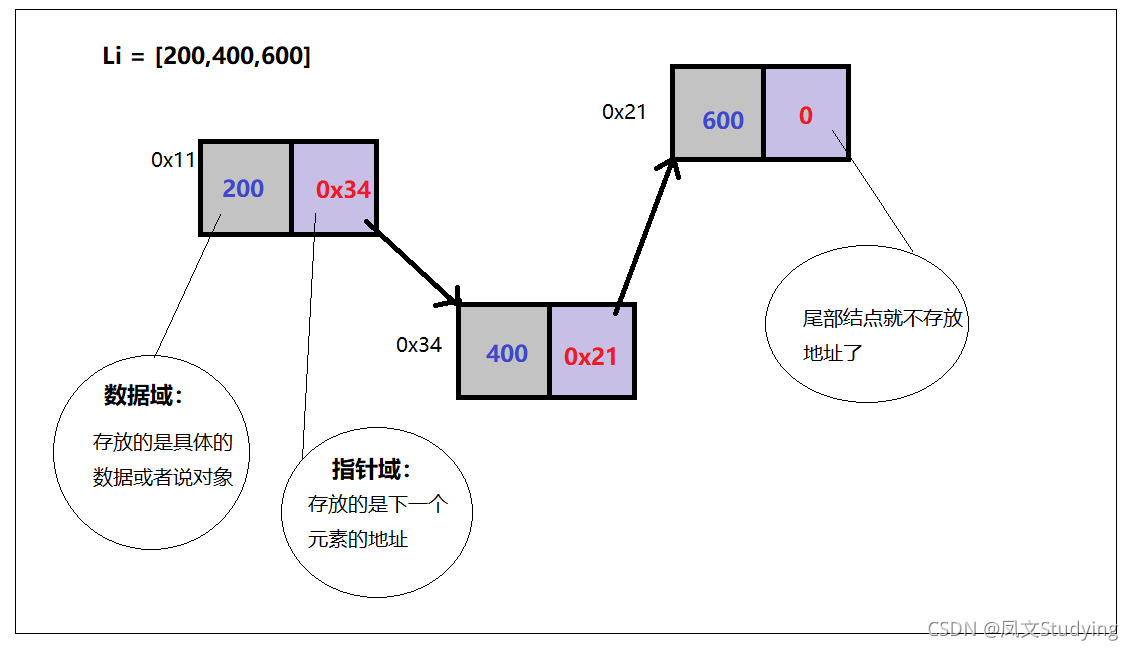 根据指针的指向,链表能形成不同的结构,例如单链表,双向链表,循环链表等。
根据指针的指向,链表能形成不同的结构,例如单链表,双向链表,循环链表等。
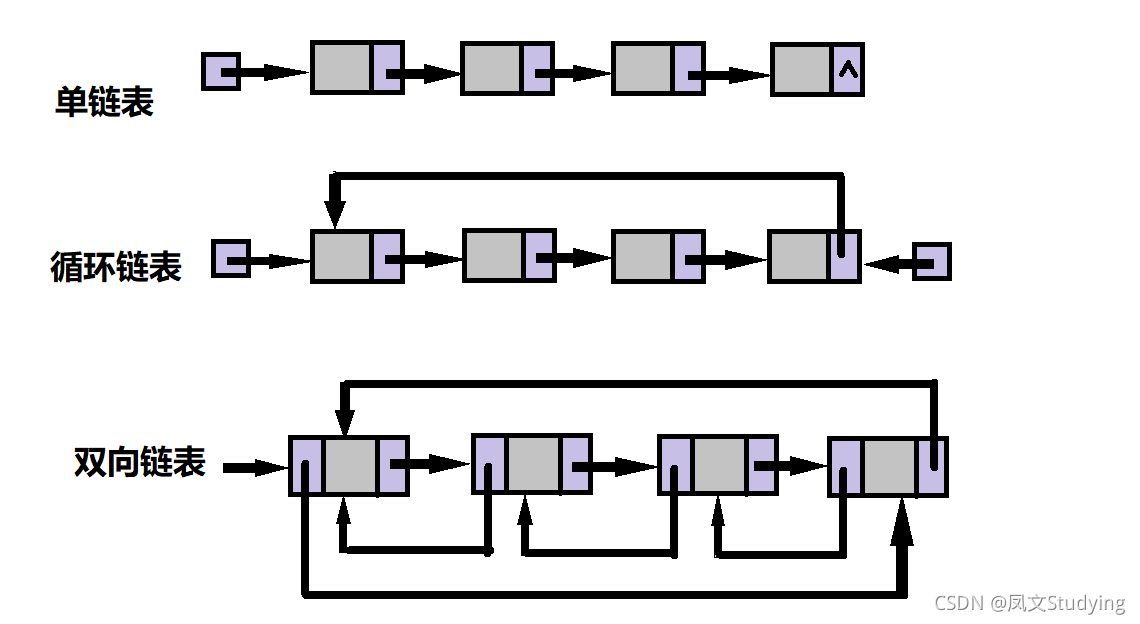
代码实现:
链表以节点为单位,每个元素都是一个独立对象,在内存空间的存储是非连续的。链表的节点对象具有两个成员变量:「值 val」,「后继节点引用 next」 。
class ListNode {
int val; // 节点值ListNode next; // 后继节点引用ListNode(int x) {
val = x; }
}
如下图所示,建立此链表需要实例化每个节点,并构建各节点的引用指向。
// 实例化节点
ListNode n1 = new ListNode(4); // 节点 head
ListNode n2 = new ListNode(5);
ListNode n3 = new ListNode(1);// 构建引用指向
n1.next = n2;
n2.next = n3;
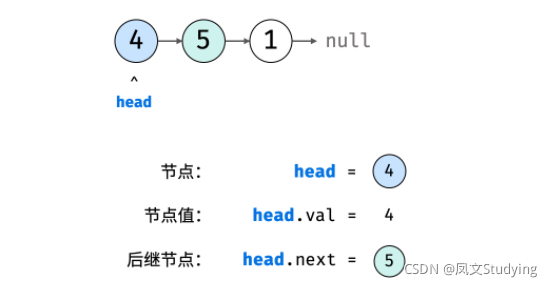
链表的优点:
链表不需要初始化容量,因为是它是一种无序的组织,所以可以任意加减元素;添加或者删除元素时只需要改变前后两个元素结点的指针域指向地址即可,所以添加,删除效率高;
缺点:
因为含有大量的指针域,占用空间较大;
查找元素需要遍历链表来查找,非常耗时。
适用场景:
数据量较小,需要频繁增加,删除操作的场景。
现在来看,貌似它的特性跟数组正好相反,所以呢,我们在写算法的时候,根据需求,应该选择合适的存储方式。这里总结一下,数组访问遍历快,增删慢;链表增删快,访问遍历慢。
栈(Stack)
栈是一种特殊的线性表,或者说被限制操作的线性表,它只允许在栈顶进行操作,也就是说,你不能从栈的中间或者栈底进行添加、删除、访问元素等操作,只有栈顶可以。
栈的特点是:先进后出,或者说是后进先出,从栈顶放入元素的操作叫入栈,取出元素叫出栈。
栈的结构就像一个集装箱,越先放进去的东西越晚才能拿出来,所以,栈常应用于实现递归功能方面的场景,例如斐波那契数列。
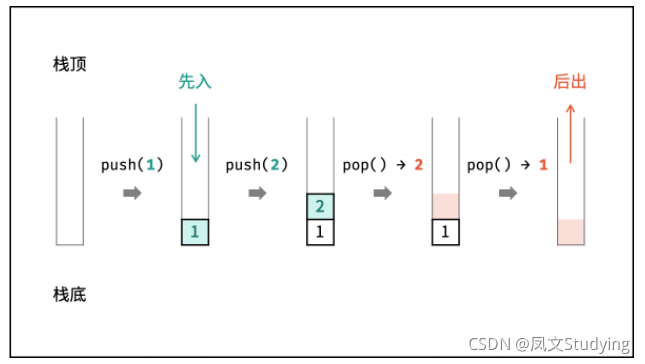
代码实现:
Stack<Integer> stack = new Stack<>();
LinkedList<Integer> stack = new LinkedList<>();stack.addLast(1); // 元素 1 入栈
stack.addLast(2); // 元素 2 入栈
stack.removeLast(); // 出栈 -> 元素 2
stack.removeLast(); // 出栈 -> 元素 1队列(Queue)
队列与栈一样,也是一种线性表,不同的是,队列可以在一端添加元素,在另一端取出元素,也就是:先进先出。从一端放入元素的操作称为入队,取出元素为出队。
队列也好理解,就跟它的名字一样,比如你中午去食堂干饭,有时候去了不能直接打饭,需要排队,而你排队需要遵循一个规则,就是只能去这个队的队尾去排队,这个就是入队,等你这排的第一个人打完饭了,那么这个人就可以从队首离开了,这个就是出队,接着后面的人依次顶替上来,直到轮到你在队首时才能离开。所以呢,先到的可以先打饭,先离开。
示例图如下:
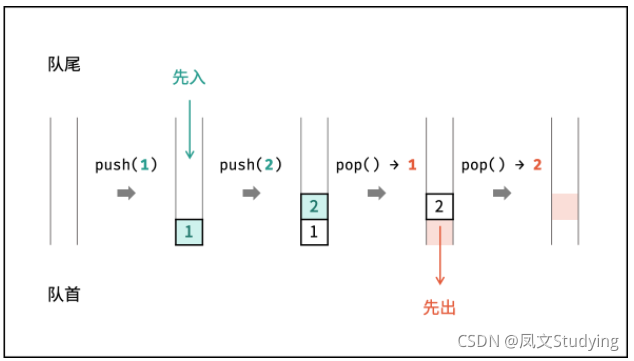
代码实现:
队列是一种具有 先进先出 特点的抽象数据结构,可使用链表实现。
Queue<Integer> queue = new LinkedList<>();queue.offer(1); // 元素 1 入队
queue.offer(2); // 元素 2 入队
queue.poll(); // 出队 -> 元素 1
queue.poll(); // 出队 -> 元素 2使用场景:因为队列先进先出的特点,在多线程阻塞队列管理中非常适用。
非线性结构
刚才说的线性结构是“一对一”的首尾相接的结构,那么非线性结构就是除线性结构以外的数据结构了。
线性结构是什么?
非线性结构中各个数据元素不再保持在一个线性序列中,每个数据元素可能与零个或者多个其他数据元素发生联系。根据关系的不同,可分为层次结构(树)和群结构(图)。
常见的非线性结构有二维数组,多维数组,广义表,树(二叉树等),图。(其中多维数组是由多个一维数组组成的, 可用矩阵来表示,他们都是两个或多个下标值对应一个元素,是多对一的关系,因此是非线性结构。)
相对应于线性结构,非线性结构的逻辑特征是一个结点元素可能对应多个直接前驱和多个后继。
树(Tree)
树
如图,是一颗倒挂的树,下面的每一个字母都是一个节点,每个相连的节点之间都有关系,比如A与B的关系,A是B的父节点,B是A的子节点;再比如E和J之间,E是父节点,J是子节点;A是这个树的根,根特征是没有父节点,并且一课树有且只有一个根;B、C、H、I、P、Q、K、L、M、N是这个树的叶,叶的特点是没有子节点。
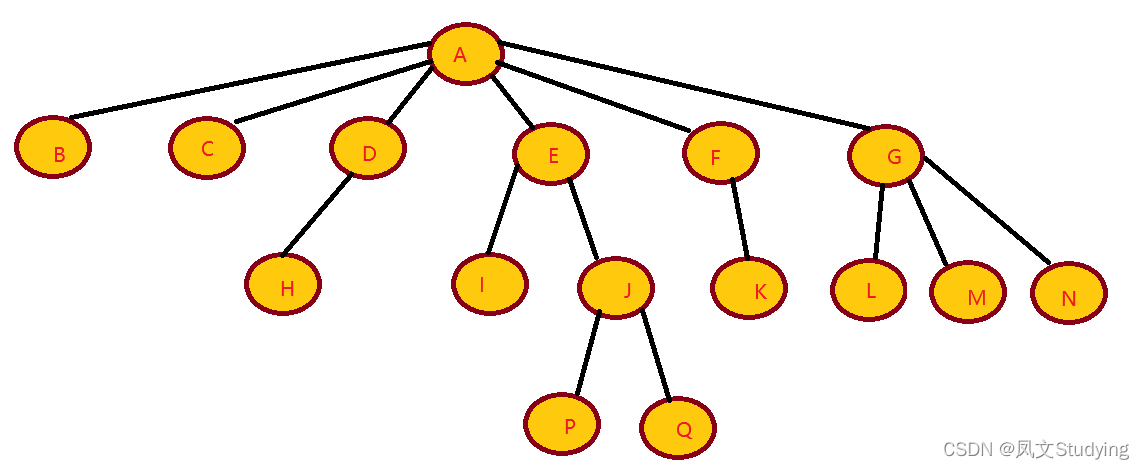
每个节点之间的连线姑且称他们为边,对于路径的概念,举一个例子,从E到Q的路径为E-J-Q,这条路径的长为2,也就是路径中的边数;相对于树的根A的节点的路径长称作深度,比如C的深度为1,H的深度为2,J的深度为2,P的深度为3,对于根A的深度自然就是0了;一颗树的深度就等于最深的叶的路径的长,比如这颗树最深为P、Q,所以这颗树的深度为3;某个节点相对当前路径的叶的长度称作高度,所以所有的叶的高度都为0;这棵树的深度也总是等于这颗树的高度。
二叉树
二叉树就是每个节点的子节点不超过两个。
一般的二叉树:
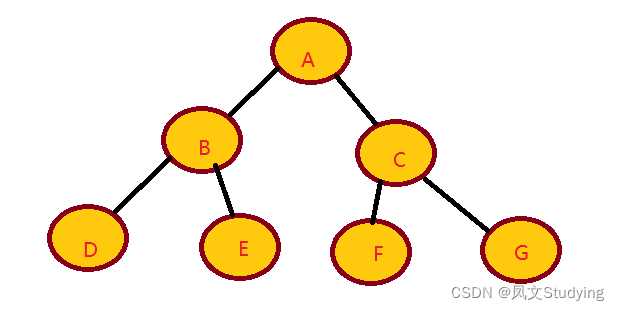
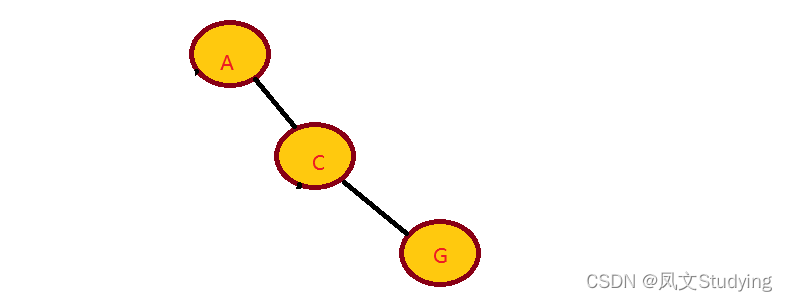
最坏的二叉树:
二叉树代码示例:
class TreeNode {
int val; // 节点值TreeNode left; // 左子节点TreeNode right; // 右子节点TreeNode(int x) {
val = x; }
}
节点实例化
// 初始化节点
TreeNode n1 = new TreeNode(3); // 根节点 root
TreeNode n2 = new TreeNode(4);
TreeNode n3 = new TreeNode(5);
TreeNode n4 = new TreeNode(1);
TreeNode n5 = new TreeNode(2);// 构建引用指向
n1.left = n2;
n1.right = n3;
n2.left = n4;
n2.right = n5;

二叉查找树
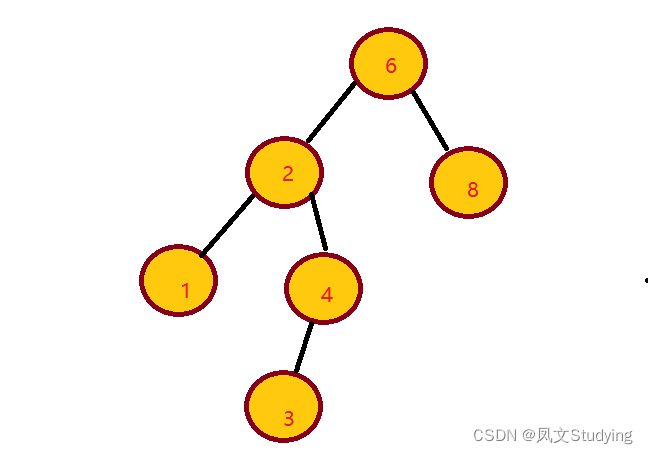
二叉查找树是对于二叉树中的每个节点x,它的左子树中所有项的值都小于x项的值,而它右子树中所有项的值都大于x项的值。例如:
这个是一个二叉查找树:
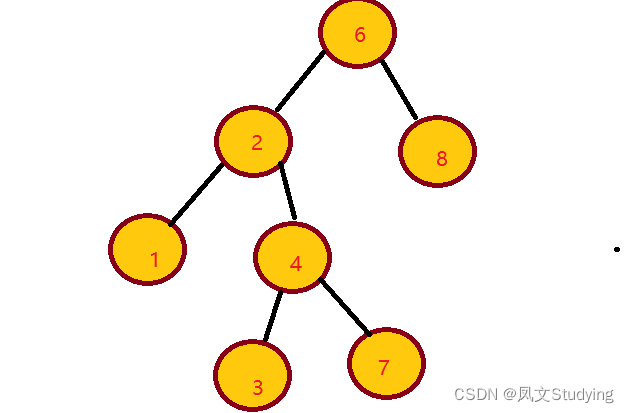
下面这个不是二叉查找树,7属于6的左子树,但7比6大。
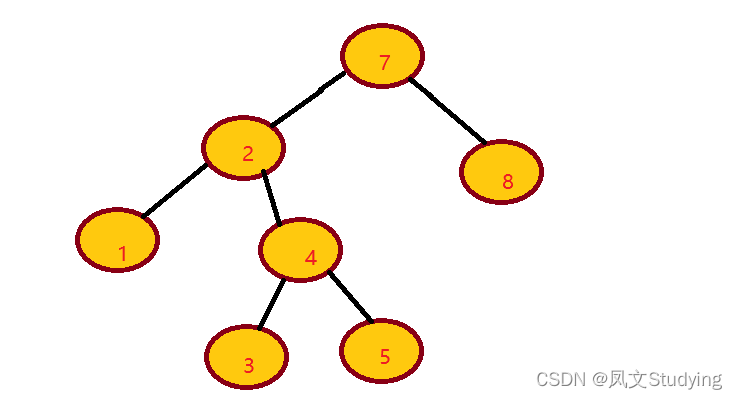
AVL树
AVL树是带有平衡条件的二叉查找树,AVL树的每个节点左子树和右子树的高度最多差1。例如:
如图是一个AVL树
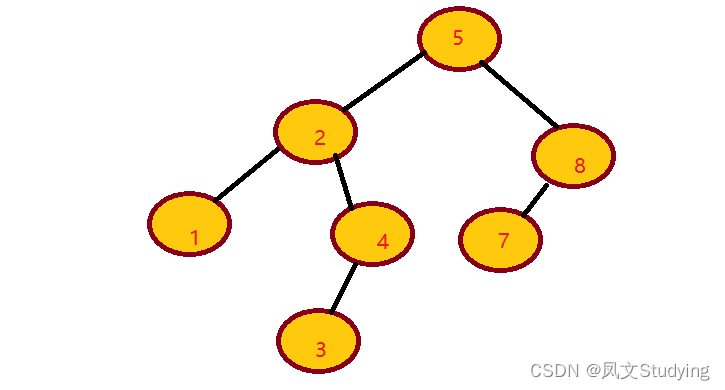
下面这个不是AVL树,因为节点7的左子树高度3,右子树高度为1,相差大于1。
对于AVL树的旋转还是挺常见的算法,读者可以深入研究一下。
还需要了解一下伸展树、再探树、B树,相比前面的这些较复杂一些,本文章目的是带你入门数据结构,若深入还得等我后面的博客。
如果你对基本的数据结构已经掌握得很好了,推荐去研究一下红黑树!
堆(Heap)
堆(具体说是二叉堆)是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右子结点的值,称为大顶堆,(没有要求结点的左子节点的值和右子节点的值的大小关系),每个结点的值都小于或等于其左右子结点的值,称为小顶堆。
下面这个是大顶堆:

从图上看,大顶堆就是数值大的在靠近顶部,顶部值最大。
我们对堆中的结点按层进行编号,映射到数组中就是下面这个样子(arr):

大顶堆特点:
arr[i] >= arr[2*i+1] && arr[i] >= arr[a*i+2]
//i对应第几个节点,i从0开始编号
下面是小顶堆:
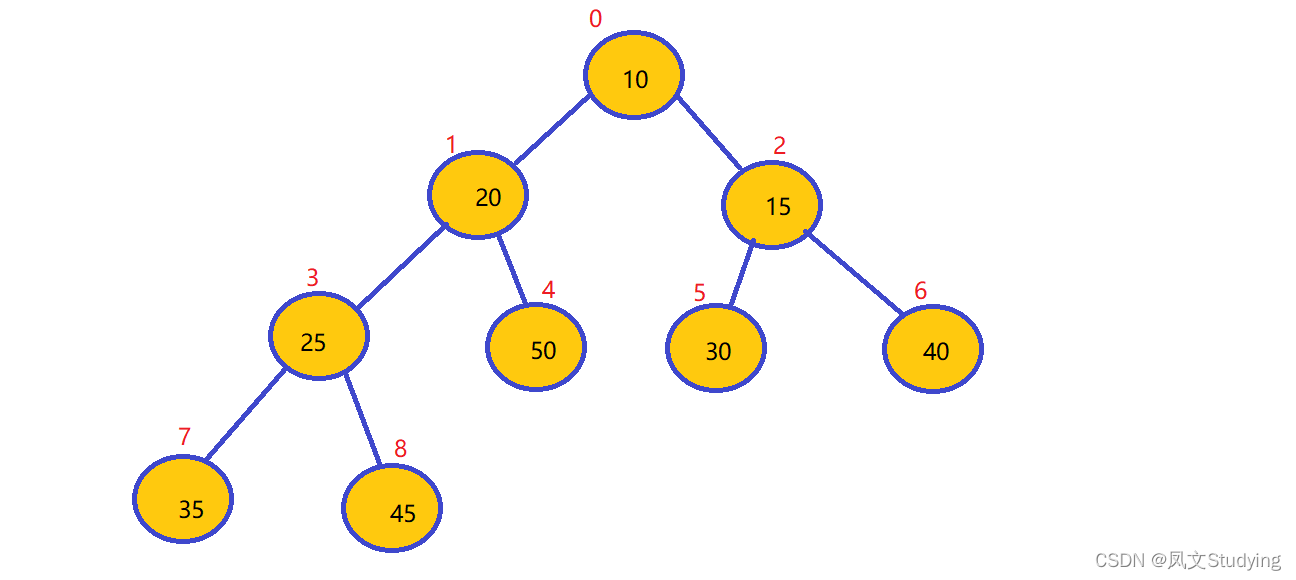
小顶堆特点:
arr[i] <= arr[2*i+1] && arr[i] <= arr[a*i+2]
//i对应第几个节点,i从0开始编号
通过使用优先队列的 push()和弹出 pop()操作,即可完成堆排序,实现代码如下:
// 初始化小顶堆
Queue<Integer> heap = new PriorityQueue<>();// 元素入堆
heap.add(1);
heap.add(4);
heap.add(2);
heap.add(6);
heap.add(8);// 元素出堆(从小到大)
heap.poll(); // -> 1
heap.poll(); // -> 2
heap.poll(); // -> 4
heap.poll(); // -> 6
heap.poll(); // -> 8
散列表(Hashing)
散列表是根据给定的关键字来计算出在表中的地址的数据结构。也就是说,散列表建立了关键字和存储地址之间的一种直接映射关系。
这个映射关系是如何反映的呢?
散列函数:一个把查找表中的关键字映射成该关键字对应的地址的函数,记为Hash(key)=Addr,这个Hash()叫哈希函数,或者叫散列函数,key就是关键字,Addr代表对应的地址。
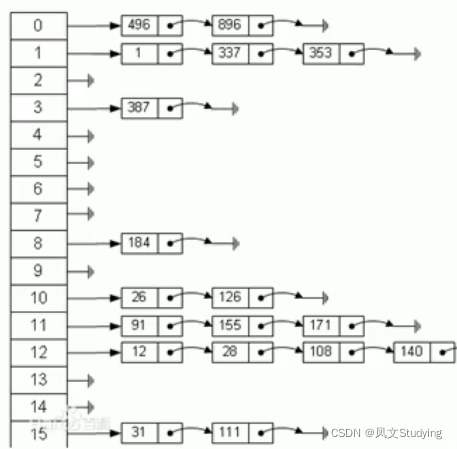
上面这个图是一个数组+链表形成的hash表。
散列函数可能会把两个或两个以上的不同关键字映射到同一地址,这种情况叫“冲突”,这些发生碰撞的不同关键字称为同义词。
就是说关键字和地址得是一一对应的,像多个key的Hash(key)结果可能为同一地址Addr的情况是需要解决的。
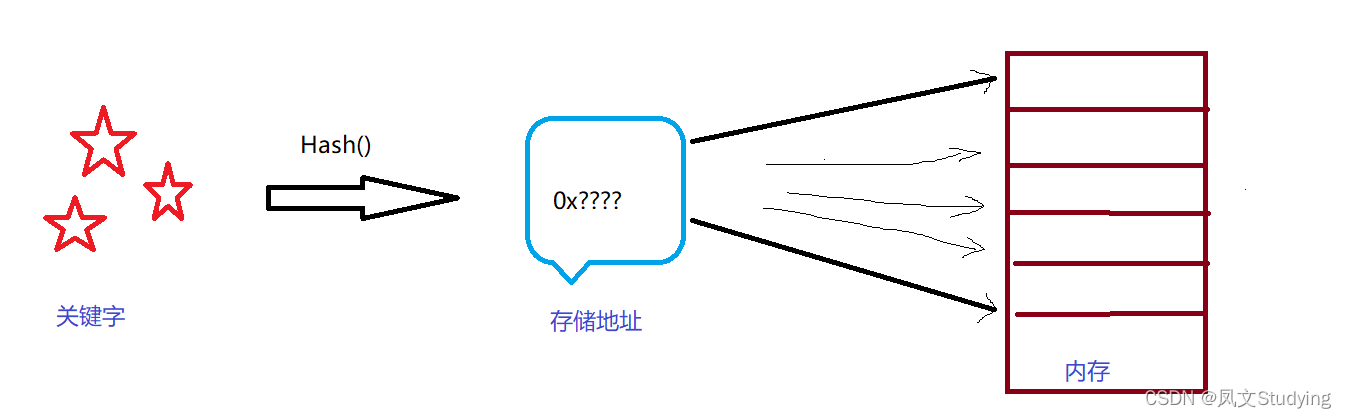
就比如说,有一堆关键字,它们通过Hash的运算获得一个存储地址,根据这个存储地址,我们就能找到内存中对应的关键字。
散列函数的注意
散列函数的定义域必须包含全部需要存储的关键字,值域依赖于散列表的大小或地址范围;散列函数计算出来的地址应该能等概率、均匀地分布在整个地址空间,从而减少冲突的发生。
常用的Hash函数的构造方法:
1.直接定址法:直接取某个线性函数值为散列地址,Hash(key)=a * key + b。这种方式最简单,不会发生冲突。
2.除留余数法:假定散列表表长为m,取一个不大于m但最接近或等于m的质数p,Hash(key)=key % p。选好了p,才能等概率地映射到散列空间的任一地址,从而尽可能减少冲突的可能性。
3.数字分析法:设关键字是r进制数(如十进制),而r个数码在各位上出现的概率不一定相同,可能在某些位上分布均匀些,每种数码出现的机会均等;而在某些位上分布不均匀,只有某几种数码经常出现,则应选取数码分布较为均匀的若干位作为散列地址。这种方法适合于已知的关键字集合。
额好吧,这么一大长串,我举个例子秒懂:

假如某个公司员工的电话,因为一个公司电话号前面的7位是相似甚至都一样,很明显这部分不适合用于查找,我们应该找分布均匀的后四位,因为后四位完全不同的概率大,更适合用于查找。所以,数字分析法就是找合适位置的若干位(区分度较大)作为散列地址。
图(Graph)
前面我们了解了线性表和树,但是线性表局限于一个直接前驱和一个直接后继的关系,而树虽然有多个后继,但只有一个前驱(即只能有一父节点),那当我们需要表示多对多的关系时,这里就引入了图的数据结构。
图的由顶点集和边集组成,其中顶点(vertex,也可以叫结点)可以有零个或多个相邻的元素。两个顶点之间的连接称为边(edge)。
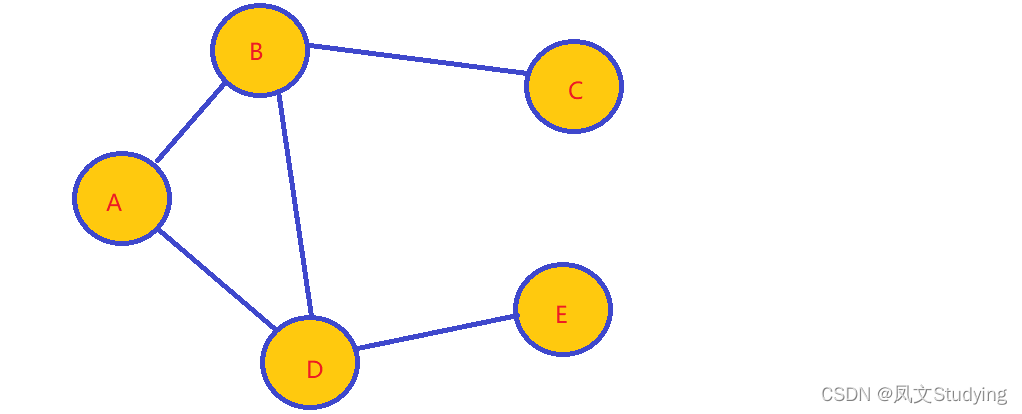
这个图中,ABCDE就是顶点,它们之间的连线就是边。
路径:当一个顶点沿着边移动到另一个顶点,期间经过的边集就是路径。
比如说从C到D,我可以走CB,BD到达D,也可走CB,BA,AD到D,所以路径可以有多个。
上面这个是无向图,无向图就是边是没有方向的,或者是双向的,比如说B和C,可以从B到C,也可以从C到B。
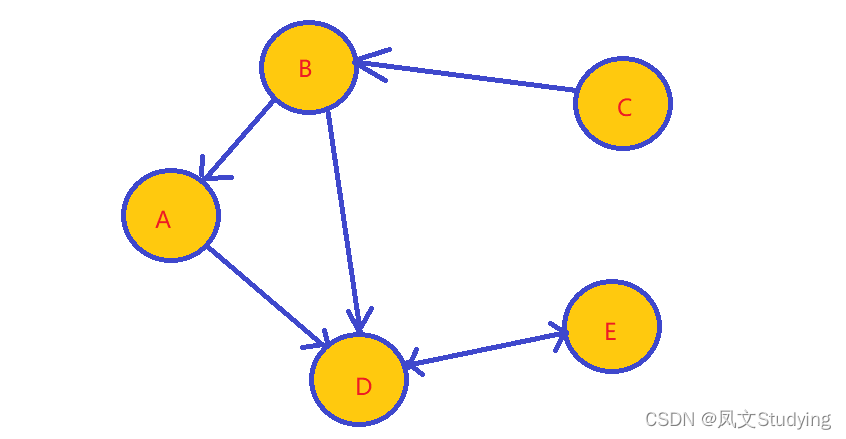
看这个加了箭头的就是一个有向图,比如B和C顶点,C可以到B,但B不可以到C。
下面这个是带权图,带权图(也可以叫网)就是边有一个值;比如说从北京到上海距离是1463公里。
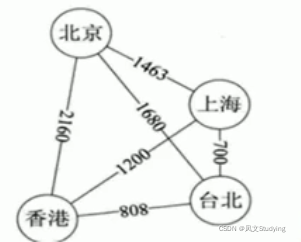
图的表示方式,有以下两种:
邻接矩阵
就是用一个矩阵来表示顶点之间的关系。
如下面这个图,0和2之间用1来表示,代表有连接(或者说有一条边),2和3之间用0来表示,代表无连接。
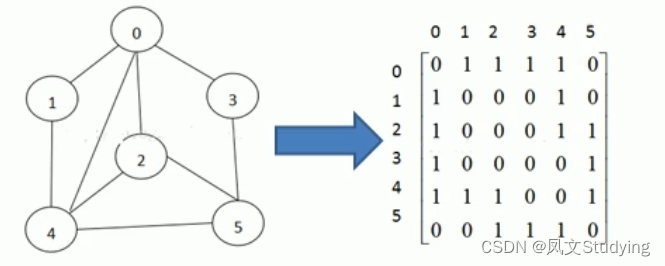
然后来看这个例子,以及代码实现:

int[] vertices = {
1, 2, 3, 4, 5};
int[][] edges = {
{
0, 1, 1, 1, 1},{
1, 0, 0, 1, 0},{
1, 0, 0, 0, 1},{
1, 1, 0, 0, 1},{
1, 0, 1, 1, 0}};
邻接表
如下面这个例子,邻接表是由数组+链表组成,对于它表示的意思,举个例子:如0顶点,它跟1,2,3,4顶点有连接,再比如,1顶点只与0,4有连接,很明显邻接表就是哪个顶点跟它有连接,就把这个顶点加到它所在数组位置的链表上。

来看这个例子以及代码实现:

int[] vertices = {
1, 2, 3, 4, 5};
List<List<Integer>> edges = new ArrayList<>();List<Integer> edge_1 = new ArrayList<>(Arrays.asList(1, 2, 3, 4));
List<Integer> edge_2 = new ArrayList<>(Arrays.asList(0, 3));
List<Integer> edge_3 = new ArrayList<>(Arrays.asList(0, 4));
List<Integer> edge_4 = new ArrayList<>(Arrays.asList(0, 1, 4));
List<Integer> edge_5 = new ArrayList<>(Arrays.asList(0, 2, 3));
edges.add(edge_1);
edges.add(edge_2);
edges.add(edge_3);
edges.add(edge_4);
edges.add(edge_5);
邻接矩阵需要为每个顶点都分配n个边的空间,其实有很多边都是不存在,会造成空间的一定损失,而邻接表的实现只关心存在的边,不关心不存在的边,因此没有空间浪费。因此,邻接表 适合存储稀疏图(顶点较多、边较少); 邻接矩阵 适合存储稠密图(顶点较少、边较多)。