目录
摘要
引言
相关工作
深度兴趣演化网络(Deep Interest Evolution Network)
BaseModel回顾
Feature Representation (特征表示)
BaseModel的结构
Loss Function
深度兴趣演化网络
兴趣抽取层(Interest Extractor Layer)
兴趣演化层(Interest Evolving Layer)
实验
数据集
方法比较
公开数据集的结果
工业数据集的结果
Application Study
Online Serving & A/B testing
结论
笔记
动机
在此之前基于神经网络的CTR模型更多的关注特征之间的交叉。在此之前的工作通常将用户行为直接看作用户的兴趣,但是显示的行为很难表征潜在的兴趣、且兴趣还会发生变化。
摘要
点击率(Click-through rate,CTR)预测是广告系统的核心任务之一,其目标是估计用户点击的概率。对于CTR预测模型,需要捕获用户行为数据背后潜在的用户兴趣。此外,考虑到外部环境和内部认知的变化,用户兴趣会随着时间的推移而动态变化。对兴趣建模的CTR预测方法有多种,但大多是将行为的表示直接视为兴趣,缺乏对具体行为背后潜在兴趣的专门建模。此外,很少有研究考虑到兴趣的变化趋势。在本文中,我们提出了一个新的模型,称为深兴趣演化网络(DIEN),用于CTR预测。具体地说,我们设计了兴趣提取层来从历史行为序列中获取目前的兴趣。在这一层,我们引入了一个辅助损失来监督每一步的兴趣提取。由于用户兴趣的多样性,特别是在电商系统中,我们提出了兴趣演化层来捕捉与目标相关的兴趣演化过程。在兴趣演化层,注意机制被用到到序列结构中,在兴趣演化过程中,相关的兴趣的作用得到加强。在公共和工业数据集的实验中,DIEN的表现明显优于最先进的解决方案。值得注意的是,DIEN已经被部署在淘宝的展示广告系统中,CTR提升了20.7%。
引言
点击计费是广告系统中最常见的计费方式之一,广告主需要为用户的每次点击付费。在CPC广告系统中,点击率预测的好坏不仅影响整个系统的最终收益,而且影响用户体验和满意度。CTR预测模型越来越受到学术界和工业界的重视。
在大多数非搜索性的电商场景中,用户不会明确的表达他们的意图。设计模型来捕捉用户的兴趣及其动态变化是提高CTR预测性能的关键。最近,许多CTR模型从传统方法论(Friedman 2001;Rendle 2010)转变为深度CTR模型(Guo et al.2017;Qu et al.2016;Lian et al.2018)。大多数深层CTR模型侧重于捕捉不同fields特征之间的交互,而较少关注用户兴趣的表示。深度兴趣网络(Deep Interest Network,DIN)(Zhou et al.2018c)强调用户兴趣的多样性,它采用基于attentio的模型来捕捉与target item相关的兴趣,来获得自适应兴趣表示。然而,包括DIN在内的大多数兴趣模型都将行为直接视为兴趣。众所周知,潜在兴趣很难通过显性行为得到充分体现。以往的方法忽视了挖掘用户行为背后的真正兴趣。此外,用户兴趣是不断变化的,关注兴趣的动态变化对于兴趣表达是非常重要的。
在此基础上,我们提出了深度兴趣进化网络(DIEN)来提高CTR预测的性能。DIEN有两个关键模块,一个是从显式用户行为中提取潜在的当前兴趣,另一个是对兴趣演化过程进行建模。良好的兴趣表示是兴趣演化模型的基石。在兴趣提取层,DIEN选择GRU(Chung et al.2014)来建模行为之间的依赖关系。在遵循兴趣直接导致后续行为的原则下,提出了一个辅助损失利用下一行为来监督对当前隐藏状态的学习(Following the principle that interest leads to the consecutive behavior directly, we propose auxiliary loss which uses the next behavior to supervise the learning of current hidden state) 。我们把这些有额外监督的隐藏状态称为兴趣状态(We call these hidden states with extra supervision as interest states)。这些额外的监督信息有助于获取更多的语义来表示兴趣,并推动GRU的隐藏状态有效地表示兴趣。此外,用户兴趣的多样性导致了兴趣漂移现象:用户的意图在相邻的访问中可能会有很大的不同,用户的一种行为可能依赖于很久以前的行为。每种兴趣都有自己的发展轨迹。同时,一个用户对不同目标的点击行为受兴趣的不同部分影响。在兴趣演化层,我们建立了相对于目标的兴趣演化轨迹模型。基于兴趣提取层得到的兴趣序列,设计了具有注意更新门(AUGRU)的GRU。AUGRU利用兴趣状态和target item计算关联度,增强了相关兴趣对兴趣演化的影响,削弱了由兴趣漂移引起的不相关兴趣的影响。在更新门引入注意力机制,AUGRU可以引导不同target item的特定兴趣演化过程。DIEN的主要贡献如下:
?我们聚焦电商系统中的兴趣演化现象,提出了一种新的网络结构来模拟兴趣演化过程。兴趣演化模型使得兴趣的表达更具表现力,对CTR的预测更为精确。
?与直接以行为做为兴趣不同,我们专门设计了兴趣抽取层。针对GRU的隐藏状态无法充分的表达兴趣,我们提出了一种辅助损失函数。辅助损失函数使用后续的行为来监督每一步隐藏状态的学习。这使得隐藏状态具有足够的表现力来表示潜在的兴趣。
?我们创造性地设计了兴趣演化层,其中带有注意更新门(AUGRU)增强了相关兴趣对目标的影响,克服了兴趣漂移的影响。兴趣演化层对与目标相关的兴趣演化过程进行了有效建模。
在公共和工业数据集的实验中,DIEN的表现明显优于最先进的解决方案。值得注意的是,DIEN已经应用于商业展示广告系统中,并在各种指标下取得了显著的改进。
相关工作
由于深度学习在特征表示和组合方面具有很强的能力,最近的CTR模型从传统的线性或非线性模型转变为深度模型。大多数深层模型遵循Embedding和多层MLP结构。基于这一基本范式,越来越多的模型关注特征之间的相互作用:Wide&Deep(Cheng et al.2016)和Deep FM(Guo et al.2017)将低阶和高阶特征结合起来,以提高表达能力;PNN(Qu et al.2016)提出了一个product层,用于捕捉不同领域类别之间的交互模式。在这些模型中,用户的历史行为经过Embedding和pooling操作后被转化为低维向量,不能很好地反映数据背后的兴趣。DIN(Zhou et al.2018c)引入了注意机制来局部激活给定候选目标下的历史行为,成功地捕捉到了用户兴趣的多样性特征。然而,DIN在捕获行为序之间的依赖关系方面是很弱的。
在许多应用程序域中,可以按时间记录user-item交互。最近的一些研究表明,这些信息可以用来建立更丰富的个人用户模型和发现额外的行为模式。在推荐系统中,TDSSM(Song、Elkahky和He 2016)联合优化了长期和短期用户兴趣,提高了推荐质量;DREAM(et al.2016)使用递归神经网络工作(RNN)的结构来研究每个用户的动态表示和物品购买历史的全局行为序。He和McAuley(2016)构建了一个视觉感知推荐系统,该系统可以展示更符合用户和社区不断发展的兴趣的产品。Zhang et al.(2014)基于用户兴趣序列度量用户相似度,提高协同过滤推荐的性能。Parsana et al.(2018)通过使用大规模event embedding和循环网络的注意力输出,改进了本地ads CTR预测。ATRank(Zhou et al.2018a)使用基于注意力机制的序的框架来建模异质行为。与不使用序列的方法相比,这些方法可以显著提高点击预测的精度。
然而,这些基于传统的RNN模型存在一些问题。一方面,它们大多将序列结构的隐层直接视为潜在兴趣,而缺乏对这些隐层表示兴趣的监督。另一方面,大多数现有的基于RNN的模型都是连续地、平等地处理相邻行为之间的所有依赖关系。我们知道,并不是所有用户的行为都严格依赖于每个相邻行为。每个用户都有不同的兴趣,每个兴趣都有自己的发展轨迹。对于任何目标,这些模型只能得到一条固定的兴趣演化轨迹,因此这些模型会受到兴趣漂移的干扰。
为了使序列结构的隐含状态能够有效地表示潜在兴趣,必须引入对隐含状态的额外监督。DARNN(Ren et al.2018)使用点击序列预测,当每个广告向用户显示时,该预测对每次点击行为进行建模。除了点击动作,还可以进一步引入排名信息。在推荐系统中,排名损失被广泛用于排名任务(Rendle et al.2009;Hidasi and Karatzoglou 2017)。类似于这些排名损失,我们提出了一个辅助损失的兴趣学习。在每一步中,辅助损失使用连续点击项和非点击项来监督兴趣表征的学习。
为了捕捉与目标相关的兴趣演化过程,我们需要更灵活的序列模型。在问答(QA)领域,DMN+(Xiong、Merity和Socher 2016)使用基于注意力的GRU(AGRU)来使注意机制对input factor的位置和顺序都敏感。在AGRU中,更新门的向量被简单地替换为注意力分数的标量。这种替换忽略了更新门的维度之间的差异,更新门包含从先前序列传输的丰富信息。受QA中新的序列结构的启发,我们提出了带有attentional gate (AUGRU) 来激活兴趣演化过程中的相关兴趣。与AGRU不同的是,AUGRU中的注意力得分作用于更新门计算出的信息。更新门和注意力得分的结合使进化过程更加specifically and sensitively。
深度兴趣演化网络(Deep Interest Evolution Network)
在本节中,我们将详细介绍深度兴趣演化网络(DIEN)。首先,我们回顾作为BaseModel的传统的Deep-CTR模型。然后我们展示DIEN的整体结构。接下来,我们将介绍用于捕获兴趣和建模兴趣演化过程的技术。
BaseModel回顾
分别从特征表示、模型结构和损失函数三个方面介绍了BaseModel。
Feature Representation (特征表示)
在我们的在线展示系统中,我们使用了四类特征:用户画像、用户行为、广告和上下文。值得注意的是,广告也是一个item。本文将广告称为target item。每个类别的特征都有几个特征域(felds),用户画像的字段是性别、年龄等;用户行为的特征域是用户访问的商品id的列表;广告的特征域是广告id、店铺id等;上下文的特征域是设备id、时间等。每个特征域中的特征值可以被编码成一个one-hot vector,例如,用户画像中的女性特征被编码为[0,1]。用户画像、用户行为、广告和上下文的这四类特征的不同特征域的one-hot向量分别进行concat表示成。在CTR的序列模型中,值得注意的是,每个特征域都包含一个行为序(each field contains a list of behaviors),每个行为对应一个one-hot vector,可以用如下表达方式表示:
其中,被编码成one-hot向量(K维),代表第t个行为,T代表用户历史性为序的个数,K代表用户可点击的商品的数目。
BaseModel的结构
大多数的深度学习的CTR模型是embedding & MLR结构的,这个结构包括以下几个部分。
Embedding:Embedding是将大规模稀疏特征转化为低维稠密特征的常用操作。在embedding层中,特征的每个字段(field)对应一个嵌入矩阵(embedding matrix),例如访问商品的嵌入矩阵可以用,其中
表示维数为
的embedding向量。对于行为特征
,如果
,则其对应的embedding向量为
,一个用户行为的有序embedding向量列表可以用
表示。类似地,
表示AD类别中特征的embedding向量的concate。
Multilayer Perceptron (MLP)首先将一个类别的embedding向量送入池化层。然后将来自不同类别的所有池化层输出的向量concat起来。最后,将concat后的向量送入后续MLP进行最终预测。
Loss Function
deep-CTR模型中广泛使用的损失函数是负对数似然函数(negative log-likelihood function),它利用target item的标签来监督整体预测
其中,D是规模为N的训练集。
表示用户是否点击target item。
是网络输出,是用户点击target item的预测概率。
深度兴趣演化网络

与赞助搜索不同的是,在许多电子商务平台上,如在线展示广告中,用户不会明确地表达自己的意图,因此捕捉用户的兴趣及其动态变化对于预测用户点击率具有重要意义。DIEN致力于捕捉用户兴趣,并对兴趣演化过程进行建模。
如图1所示,DIEN由几个部分组成:
首先,通过嵌入层对各类特征进行变换。
接下来,DIEN采取两个步骤来捕获兴趣演化:
兴趣提取层根据行为序列提取兴趣序列;
兴趣演化层模拟与target item相关的兴趣演化过程。
最后将兴趣表达和ad, user profile, context 的embedding向量concat。将级联后的向量送入MLP进行最终预测。
在本节的剩余部分,我们将详细介绍DIEN的两个核心模块。
兴趣抽取层(Interest Extractor Layer)
在电商系统中,用户行为是潜在兴趣的载体,用户采取一种行为后兴趣会发生变化。在兴趣提取层,我们从用户行为序列中提取一系列的兴趣状态。(At the interest extractor layer, we extract a series of interest states from sequential user behaviors)
电商系统中的用户行为是丰富的,即使在很短的时间内(如两周),历史行为序列的长度也是很长的。为了在效率和性能之间取得平衡,我们采用GRU来建模行为之间的依赖关系。GRU的输入是按行为发生时间排序的行为序(the input of GRU is ordered behaviors by their occur time)。GRU克服了RNN的消失梯度问题,且比LSTM(Hochreiter and Schmidhuber 1997)速度快,适用于电商系统。GRU的公式如下:
其中是sigmoid激活函数,
是按元素乘法,
,
是隐藏层单元数,
是输入层单元数,
是GRU的输入,
代表用户的第t个行为,
是隐层第t个隐层状态。
然而,隐藏状态只能捕捉行为之间的依赖关系,不能有效地表示兴趣。由于对target item的点击行为是由最后兴趣触发的,因此
中使用的标签只能监督最后的兴趣预测,而不能正确的监督历史状态
。众所周知,每一步的兴趣状态直接导致后续的行为。因此,我们提出了辅助损失,即利用
行为来监督兴趣状态
的学习。使用真实的下一步行为作为正例,从非点击的item中抽样得到负例。有N对行为序的embedding:
其中
代表点击行为序,
代表负的样本。T是行为序列的数目,
是embedding的维度,
表示用户i第t次点击的item的embedding。
是整个item的集合,
是从item集合中除去用户i第t次点击的item中采样的。辅助损失的公式如下:
其中, 是sigmoid激活函数,
代表GRU的第t个隐藏层状态,CTR模型的全局损失函数为:
其中是超参,用来平衡CTR预测和兴趣表达。
在辅助损失的帮助下,每一个隐藏层状态都能够充分的表达用户第t次行为
之后的兴趣。将T个兴趣点concat起来组成兴趣序
,这个序列可以被用作兴趣演化层对兴趣演化过程的建模。
总之,辅助损失的引入有许多优势,1.从兴趣学习的角度,辅助损失帮助GRU的隐层状态更好的学习兴趣的表达;2.从GRU的优化来说,当GRU对长的历史行为序列建模时,辅助损失能够很好的降低梯度传播的难度尤其是面对长序列(应该是指梯度消失);3.辅助损失为embedding层的学习提供了更多的语义信息,这会帮助我们得到更好的embedding矩阵。
兴趣演化层(Interest Evolving Layer)
由于外部环境和内部认知的共同影响,用户的各种兴趣随时间发生变化。以对于衣服的兴趣为例,随着流行趋势和用户穿衣品味的变化,用户对于衣服的偏好也会变化,用户对于衣服兴趣的变化,直接决定了对候选衣服的点击率预估。兴趣演化的优点如下:
- 兴趣演化模块可以为最后的兴趣的表示提供更多的相关的历史行为信息;
- 根据兴趣演化趋势预测target item的点击率是一种较好的方法。
值得注意的是,兴趣在演化过程中表现出两个特征:
- 兴趣具有多样性,兴趣可以漂移。兴趣漂移对行为的影响是,用户可能在一段时间内对各种书籍产生兴趣,而在另一段时间内则对衣服有兴趣。
- 尽管兴趣能互相影响,但是每个兴趣都有自己的演化过程,例如衣服和书籍的演化过程几乎是独立的,我们可以只考虑和target item相关的演化过程。
在第一个阶段,在辅助损失的帮助下,我们得到了兴趣序列的表达。考虑到兴趣演化的特点,我们利用了注意力机制的局部激活能力,以及GRU对序列模型的建模能力。在GRU模型引入注意力机制,注意力机制的局部激活使我们对相关兴趣更加敏感,并且削弱兴趣漂移带来的影响。这帮助了我们建模与target item相关的兴趣的演化。
与公式(3-6)类似,我们用和
表示兴趣演化层的GRU部分的输入和隐藏状态。其中,第二个GRU的输入是兴趣提取层的相应兴趣状态:
。隐藏状态
代表最后的兴趣状态。
在兴趣演化模型中用到的attention function公式如下:
其中是ad类别下的特征的embedding向量的concat,
,
是隐藏状态的维度,
是广告embedding向量的维度。Attention score能反应广告
与输入
的关系,越相关则attention score的值越大。
下面我们介绍几种可以将注意力机制和GRU结合起来建模兴趣演化过程的。
attention 作用于 input的GRU(AIGRU)。为了在兴趣演化过程中激活相关兴趣,我们提出带attention input的GRU方法。AIGRU使用attention score来影响兴趣演化层的输入。公式如下:
其中,是兴趣演化层GRU部分的第t个隐藏状态,
是兴趣演化层GRU的输入(
is the input of the second GRU which is for interest evolving),
是向量的点积。在AIGRU中,attention score能够降低不相关的兴趣的幅值。理想状态下,不相关的兴趣的幅值可以被降到0,这样我们就可以将与target item相关的兴趣演化趋势建模。然而,AIGRU表现并不好。因为即使输入为0也可以改变隐藏状态,所以就算非常不相关的兴趣也会影响兴趣演化的建模。
Attention based GRU(AGRU)。attention based GRU第一次提出是在问答领域(Xiong, Merity, and Socher 2016),用注意力机制的embedding信息来修改GRU架构,AGRU能从复杂的qury中有效的提取关键信息。受QA领域用AGRU提取query的关键信息的启发,我们利用AGRU提取兴趣演化过程的相关兴趣。在实现上,AGRU使用attention score替换GRU的update gate,并直接改变隐藏状态。公式如下:
其中,以及
是AGRU的隐藏状态。
在兴趣演化的场景下,AGRU用attention score来直接控制隐藏状态的更新。AGRU在兴趣演化的过程中削弱了不相关的兴趣的影响,并且克服了AIGRU的缺陷(The embedding of attention into GRU improves the influence of attention mechanism, and help AGRU overcome the defects of AIGRU)。
GRU with attentional update gate (AUGRU)。尽管AGRU用attention score来直接控制隐藏状态的更新,但是他用标量(attention score)来替代向量(the update gate ),忽略了不同维度的重要性不同。我们提出了带有attentional update gate(AUGRU)的GRU,来将注意力机制与GRU结合:
其中,是AUGRU初始的更新门,
是为AUGRU设计的attentional update gate,
以及
是AUGRU的隐藏状态。
在AUGRU中,我们保留了更新门的原始维度信息,它决定了每个维度的重要性(向量上各维度对应的元素)。在区分信息的基础上,利用注意得分对更新门的各个维度进行度量,使得相关性越低的兴趣对隐藏状态的影响越小。AUGRU更有效地避免了兴趣漂移的干扰,推动了相关兴趣的平稳演化。
实验
在本节中,我们将DIEN与公共和工业数据集的最新技术进行比较。此外,我们设计实验分别验证辅助损耗和AUGRU的影响。为了观察兴趣演化的过程,我们展示了兴趣隐藏状态的可视化结果。最后,我们分享了我们用于在线服务的结果和技术。
数据集
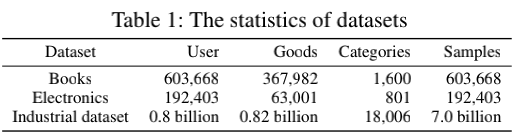
我们用公开数据集和工业数据集来验证DIEN的作用,表1给出了相关数据集的统计数据。
公开数据集:Amazon数据集(McAuley et al.2015)由来自Amazon的产品评论和元数据组成。我们使用亚马逊数据集的两个子集:Books和Electronics来验证DIEN的效果。在这些数据集中,我们将评论视为行为,并按时间对一个用户的评论进行排序。假设用户有
个行为,我们的目的是使用
行为来预测用户
是否会写T-th评论中显示的评论(Assuming there are T behaviors of user u, our purpose is to use the T 1 behaviors to predict whether user u will write reviews that shown in T-th review.)。
工业数据集:是由在线展示广告系统的曝光和点击日志构成的。对于训练集,我们以最近49天点击的广告为target item。
每个target item及其相应的行为构成一个实例。以一个target item a为例,我们将a被点击的时间设置为最后一天,该用户在前14天的行为作为历史行为。同样,测试集中的target item是从接下来的1天中选择的,并且行为的构建与训练数据相同。
方法比较
将DIEN与主流的CTR预测方法进行比较。
BaseModel: BaseModel采用与DIEN相同的embedding和MLR网络结构,并使用sum pooling操作来整合行为的embedding。
Wide & Deep: wide & Deep由两个部分组成:deep部分和Base Model相同,wide部分是配有手动设计的特征交叉的线性模型(用特征交叉来增强特征交互)。
PNN: 基于Base Model,PNN使用product layer来捕获域间类别之间(interfield categories)的交互模式。
DIN:DIN使用注意力机制来激活用户的相关的兴趣,并且依据不同的ads来自适应的调整用户兴趣表达向量(adaptive representation vector)。
Two layer GRU Attention:类似于(Parsana et al.2018),我们使用两层GRU来对行为序列建模,并用一个attention layer来激活相关行为。
公开数据集的结果
图1展示了DIEN的结构,包括了GRU、AUGRU以及辅助损失和其他的一些常规模块。每个实验都进行了5次,表2给出了实验上的平均AUC。
从表2中可以看出,wide & deep 很大程度上依赖于手工设计的特征的质量,并且表现不是很好,而特征之间的自动交互(PNN)可以提高BaseModel的性能。同时,以捕获兴趣为目标的模型能显著提高AUC:DIN激活了与ad相关的兴趣,两层GRU注意进一步激活了兴趣序列中的相关兴趣,这些探索都获得了正向收益。DIEN不仅能更有效地捕捉到兴趣序列,而且还能对与target item相关的兴趣演化过程进行建模。兴趣演化模型有助于DIEN获得更好的兴趣表示,准确捕捉兴趣动态,极大地提高了性能。
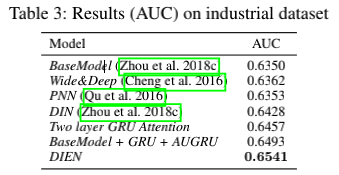
工业数据集的结果
我们进一步在真实的展示广告的环境下做实验。工业数据集的样本规模是公开数据集的千倍,并且行为也更加丰富。如表3所示,Wide & Deep和PNN获得了优于base model的表现。与Amazon数据集单一的品类不同的是,工业数据集包括了各类商品,基于这些特点。,基于注意力的方法能够极大的提高性能,例如DIN。DIEN能捕获与target item相关的兴趣演化进程,并获得很好的表现。
Application Study
本小节,我们分别展示AUGRU和辅助损失的作用。

Effect of GRU with attentional update gate (AUGRU):表4展示了不同方法在兴趣演化的表现。相对于Base Model,two layer GRU有不错的表现,但是缺乏对兴趣演化的建模极大的限制了其性能。AIGRU的基本思想是对演化过程进行建模,虽然它相对于前两种在性能上取得了优势,但在兴趣演化过程将注意力机制和演化分割开来,造成了演化过程中信息的丢失。AGRU进一步尝试融合注意力和演化,正如我们之前提出的,它在GRU中的注意力不能充分利用更新门的资源(维度问题,标量代替向量)。通过分析AIGRU和AGRU,AUGRU的性能优势是显而易见的。它将注意机制和序列学习有机地融合在一起,有效地捕捉了相关兴趣的演化过程。
Effect of auxiliary loss :在AUGRU模型的基础上,下面进一步探讨辅助损耗的影响。在公共数据集中,辅助损失中使用的负例是从没有响应评论的item集合中随机采样的。对于工业数据集,我们将曝光未点击的作为负例。
如图2所示,全局损失和辅助损失
保持相同的下降趋势,这意味着CTR预测的全局损失和兴趣表达的辅助损失都起到了作用。

在表4中,我们发现辅助损失对两个公共数据集都有很大的改善,辅助损失在公共数据集中的好的表现反映了监督信息对兴趣序列学习的重要性。此外,对GRU的每一步的监督也有助于模型获得更具表达能力的embedding表示。对于表3所示的在线数据集的结果,带有辅助损失的模型进一步提高了性能。但是,我们可以看到,这种改进并不像公共数据集中那样明显。这种差异来自几个方面。首先,对于工业数据集,它有大量的实例来学习embedding layer,这使得它从辅助损失中获得的收益较少。第二,不同于amazon数据集中所有item均来自一个类别,工业数据集中的行为是来自我们平台中所有场景和类别的点击商品。我们的目标是在一个场景中预测广告的点击率。辅助损失的监管信息可能与target item不一致,因此,相比于公共数据集,辅助损失对工业数据集的影响可能较小,而AUGRU的影响则被放大。

Visualization of Interest Evolution:AUGRU中隐藏态的动态变化可以反映出兴趣的演化过程。在本节中,我们将这些隐藏状态可视化,以探讨不同target item对兴趣演化的影响。选择的历史行为依次来自Computer Speakers, Headphones, Vehicle GPS, SD & SDHC Cards, Micro SD Cards, External Hard Drives, Headphones, Cases等类别。利用主成分分析(PCA)将AUGRU中的隐态投影到二维空间(Wold、Esbensen和Geladi 1987)。投影的隐藏状态按顺序链接。由不同target item激活的隐藏状态的移动路径如图3(a)所示。None标记的黄色曲线表示等式(12)中使用的注意力得分,这些注意力得分相同,即兴趣的演变不受target item的影响。蓝色曲线显示隐层状态由来自类别屏幕保护器的一个商品激活,这与所有历史行为的相关性都较小,因此蓝色曲线与黄色曲线的路径类似。红色曲线显示隐藏状态由 Cases类别中的一个商品激活,target item与最后一个行为有很强的相关性,这移动了一个较长的步骤(图中幅值较大),如图3(a)所示。

Online Serving & A/B testing
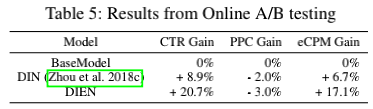
2018-06-07至2018-07-12在淘宝展示广告系统进行在线A/B测试。如表5所示,与Base model相比,DIEN将CTR提高了20.7%,eCPM提高了17.1%。此外,DIEN的PPC下降了3.0%。现在,DIEN已经部署在网上,并服务于主要流量,这为业务收入的大幅增长做出了贡献。
值得注意的是,DIEN的在线服务对商业系统来说是一个巨大的挑战。在线系统在我们的展示广告系统中拥有极高的流量,在流量峰值时,该系统每秒服务超过100万用户。为了保持低延迟和高吞吐量,我们部署了几种重要的技术来提高服务性能:
i) 元素并行GRU和内核融合(element parallel GRU & kernel fusion)(Wang、Lin和yi2010),我们融合尽可能多的独立内核。此外,GRU隐态的每个元素都可以并行计算。
ii)批处理(Batching):为了利用GPU的优势,来自不同用户的相邻请求被合并到一个批处理中。
iii)火箭发射模型压缩(Model compressing with Rocket Launching)(Zhou et al.2018b):我们使用(Zhou et al.2018b)中提出的方法来训练一个轻网络(light network),该轻网络尺寸较小,但性能接近更深更复杂的网络。例如,通过火箭发射,GRU隐态维数可以从108压缩到32。在这些技术的帮助下,DIEN服务的延迟可以从38.2ms减少到6.6ms,并且每个worker的QPS(每秒查询)容量可以提高到360。
结论
本文提出了一种新的deep network结构,即深度兴趣演化网络(DIEN)来模拟兴趣演化过程。DIEN极大地提高了在线广告系统中CTR预测的性能。具体来说,我们设计了兴趣提取层来捕获兴趣序列,利用辅助损失对兴趣状态进行更多的监控。在此基础上,我们提出兴趣演化层,其中DIEN使用AUGRU、来模拟与target item相关的兴趣演化过程。在AUGRU的帮助下,DIEN克服了兴趣漂移带来的困扰。兴趣演化模型有助于我们有效地捕捉兴趣,进一步提高CTR预测的性能。在未来的研究中,我们将尝试建立一个更具个性化的兴趣预测模型。