���ߣ�����
from: http://geek.csdn.net/news/detail/97193
Part I ��Image Caption Generation�������ѧϰ(1)
0. ǰ��Ļ�
��������дһƪ���ѧϰ���С���£�Ŀ������ǹ��ڵĿ����ߡ��սӵ��������ʱ������Ϊ�����ģ�д����Ҫ������������������ˮ֮��Ҳ���������为����Ҳ����������Ϊ����֪ˮƽ�����ޣ��ֲ�����ѧУ�Ϳ��л������о���ֻ������Ϊ�������˵���Ȥ�������ѧϰ��һ����dz���˽⣬���Ե���д�����Ķ��������������棬����������������;����������һ�룬������Լ���Ϊһ�����ѧϰ��ѧϰ�ߣ��Ͷ�������Ȥ����ͨ�����߷���һЩѧϰ�ľ���������ѧϰ���������������⣬����Ҳ����һЩ����ġ��Ͼ������Ļ�����ѧ����ţ�Ľ���ֻ�ܿ������ɹ����ľ��飬���Ҵֿ����������˵û��̫��ı���֪ʶ�����ܶ�Ȧ�ڵ��˶��Ǽ������ӵ����Щ֪ʶ�ġ����Ƕ�����ͨ�Ŀ�������˵���ܶ����֪ʶ�������Դ����������������ѧ����ƾͻ�����ʦ�ˣ���˿������������Ѷȸ���������һ���Ƕ���˵������ʦ�������ߣ��Ϳ�ѧ�ң����й����ߣ���ע�ĵ�Ҳ�Dz�һ���ġ���ѧ�Ҹ���ע���۵Ķ���������һ��ģ������ô������ģ�ΪʲôҪ��ô���ģ�ͣ�������ģ����ôת����һ���Ż����⡣������ʦ�����ע��������ܹ���ʲô����������Ż�������ô������Ч��ѧ����ÿ���д��������ķ�����������idea������������к��л����еĹ������ܿ��������ۺ�Ư������ʵ��Ӧ���������ѣ���Щ�������ܲ���̫���˹�ע����ȴ��ijЩ��ҵ��dz���Ҫ�ġ�
������˹����ܵķ�չ��˵���Ҹ��˾����ڴ�ͳ��ҵ���ռ�Ҳ�Ƿdz���Ҫ�ġ����ںܶ��˹����ܴ�ҵ��˾���ܶ������˹����ܴ���һ��ȫ�µIJ�Ʒ��������������Siri���������ֵ����ڻ��ȵĻ����ˡ����Ҹ��˾���Ŀǰ���˹����ܵ�ˮƽ�����������ﵽ�û�Ԥ�ڵIJ�Ʒ�������Ǻܶ������˾��ţ������Щ���֣������û��������ߣ�������ʹ�ò�Ʒ�����γɾ�ķ���Ҿ���Ŀǰ���˹����ܸ�����ô�����������ϵͳ�������Լ��Ļ���˵����Ŀǰ���˹�����ֻ�ǽ�������������ѩ����̼��Ҳ����˵�⿿�˹������Dz��������û���������IJ�Ʒ�ġ�
�������ڹ���ܻ��Amazon�����������ƷEcho������Ҳ�����һ�����䣬�������������˵���ҹ���Echo�������ǵ�Echo�зdz����ܵ������������ܣ������������������������ӣ�����Uber�����Կ��Ƽ�������ܱ��䡣����������빺��һ�����䣬������������ѡ��һ���Ǵ�ͳ�����䣬��һ����Echo����ô�����˵Echo�ж�ôţ�Ƶ����ܿ��ܻ���ң�����Ҳ��˶���Ǯ��������ô���������ܿ��ŵĹ���Ҳͦ�����ġ�
����Echo�ijɹ������ںܶ���Ҳ�롰ɽկ��һ�����ƵIJ�Ʒ���������ܺܶ��˺������������й���һЩϸС���죬�Ǿ��������ƺ����Ǵ���о���ıر�Ʒ�����Ҹ��˵�����Ȧ��˵��ÿ����ͥ�϶����и����ӣ�������������������Ϊʲô�������أ���Ϊ�й��Ĵ���о������ס¥�����ܶ�����С����Ч�����ܲ����������Ū���ﻹûhigh�����ӣ������ھӾ������ˡ����Ƕ�������˿�Ǽ���������ʱ�ıر�������Ҳ�����������
˵����ô�࣬�����ľ���Ŀǰ�˹�����Ӧ�ø����������в�Ʒ�������ᵽGoogle����ҿ��ܻ��뵽���չ���Deepmind��AlphaGo���������ǿ���û����ʶ���ճ�ʹ�õĺܶ��Ʒ�ж�ʹ�������ѧϰ��������������������ʼ������ܻظ����ɣ�������ʹ�������ѧϰ����AlphaGo��������������һ���г�PR��һ���������ã��ô��֪���˹�����Ŀǰ��һЩ��չ��������AlphaGo�Ŷ������뽫�似���õ�ҽ����ҵ����ҽ����ϼ�����
Ҳ����˵�˹�������δ��Ҳ���������������������Ƽ���һ����һ���dz���������ʩ�����κ���Ҫ�û�������������������ij�������������֮�صġ�Ŀǰ�����ǹ��ڻ��ǹ��⣬�˹����ܵ��˲Ŷ��Ƿdz�ϡȱ�ģ����Ҷ��Ǽ���������ѧУ��ʵ���Һʹ�˾���о�Ժ��������ͨ�����ߴ�����ص�֪ʶ���Ե���Ϊ��Ҫ�����������Ŀ��ǣ���Ȼ�Լ�������������������Ը����Լ�ѧϰ��һЩ������������ҷ�����
1. Ϊʲô����Image Caption Generation������⣿
��ƪС���²�û����ʲô��Χ��ֻҪ�����ѧϰ��صľ��С��ⷴ�����˷��գ��ͺ�����һ����ѡ��̫����Ҳ��һ�ַ��ա���Ϊ��������п�֮������ѧϰ˹̹���Ŀγ�CS231N��Convolutional Neural Networks for Visual Recognition������γ̷dz��ã������꾡��slides��notes����ֵ��һ��ľ���������ҵ��ÿ����ҵ����������ģ�ͣ�����CNN��LSTM�����е�ģ�͵Ĵ��붼ֻ�������python����ʵ�֣����������ֳɵĿ����TensorFlow/Theano/Caffe��ֽ�ϵ����վ�dz����֪����Ҫ���С��ܶ����ۣ������ο�slides���ƺ������Լ����ˣ���ʵ����һ֪��⣬����Ҫ���գ��͵��Լ����֣������ȫ���Լ�ʵ�֡�����ȫ���Լ�ʵ����Ҫ����ʱ��̫�࣬���Ҵ�ʵ�ʹ����ĽǶ���˵���ֿ����߿϶�������TensorFlow�����Ĺ��ߡ�������γ̵ĺô����ǣ���һЩ���������Ĵ��벻��صIJ��ְ���ѧϰ�Ŀ�ܶ��Ѿ�ʵ���ˣ�Ȼ����IPython notebook�ѹؼ��Ĵ���ĺ��������������������ķdz������ѧϰ��ֻ��Ҫʵ��һ��һ�������ĺ��������ˣ�����ÿ���������������Ƶ�Ԫ���Եļ�������ȷ�Ե����ݣ��Ӷ���֤���ǵ�ÿһ�������ڳ�����ȷ�ķ���ǰ����
�����ƪС���´��㽲һ�����е�Assignment3��Image Caption Generation���֡�Ŀ������ͨ��һ�����������������ҽ������ѧϰ��һЩ֪ʶ���ô�Ҷ����ѧϰ��һЩ�������Ȥ��ѡ��Image Caption Generation��ԭ��һ���������ͦ����˼�ģ��ڶ��������漰���ܶ����ѧϰ���е�ģ����CNN��RNN/LSTM��Attention��
����������һ��ʲô����Image Caption Generation��
���ڼ�����Ӿ���ص�����ͼƬ����Ͷ�λ��ҿ��ܱȽ���Ϥ��ͼƬ������Ǹ���һ��ͼƬ���ü����������������һֻè����һֻ������ͼƬ��λ���˸�����������һ�Ź���ͼƬ������Ҫ����һ�����ο�ѹ���λ�ñ�ʶ��������Ȼ����Ҫ����ߵ�Image Segmentation����Ҫ����������һЩ�������ڹ���������һЩ���ڱ�����
ͼ1������Щ��������ӣ�
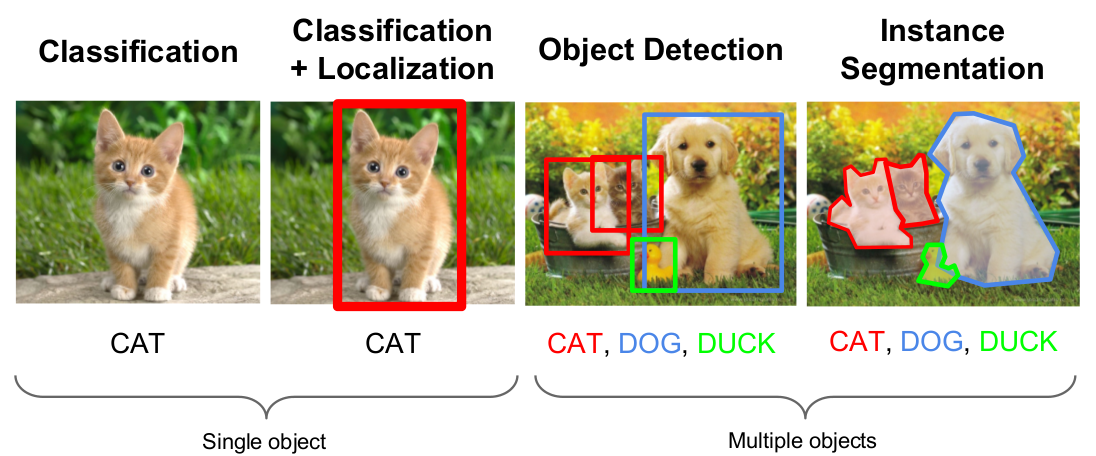
ͼ1�����������Ӿ����� ͼƬ���� http://cs231n.stanford.edu/slides/winter1516_lecture8.pdf
��Image Caption Generation�����Ǹ���һ��ͼƬ����Ҫ�ü������һ�仰����������ͼƬ��
��ͼ2��ʾ��

ͼ2��Caption Generation����ʾ�� ͼƬ���� http://mscoco.org/dataset/#captions-challenge2015
��ʵ�ʵ�Ӧ����˵���������Ҳ�Ǻ����ô��ġ�����һ���ֻ�������Ƭ֮�����ǿ����������������һ�仰���������ͼƬ������������Ժ���ҡ�
���������о��ĽǶ���˵��Caption Generation�����֮ǰ��task��˵��Ҫ�������롰���⡱ͼƬ������֮��Ĺ�ϵ����������һЩ����ĸ������һ����Ϣ�������ͼƬѹ���ɶ̶�һ�仰��
��������Ȼ���Դ���(NLP)��ع����ģ�֮ǰ�Լ�����Ӿ���һЩ����Ŀ�������Ϊ�Ӿ��ź��Ǹ��ײ��ԭʼ���źţ��������࣬����Ҳ�к�ǿ���Ӿ�������Ҳ�ֱܷ治ͬ���塣�����������ഴ��ķ���ϵͳ�����ڸ��߲�ij���������ڸ������˹��������⣬�ƺ������˻������ƵĹ۵㡣
��������������һЩ��ͬ�Ŀ���������Ĵ��Բ�û��ʲô����֮����һ��С����һ��֮ǰһ�㲻��˵��������ʶ�������Ҫ��ʽ������Ҫͨ���Ӿ�ϵͳ���������壬Ҳ�������������ƣ�ͨ�����ӵ���Ԫ�������������⡱���硣��Щ��ͬ��ε�������Dz�ͬ��ε�����������������ġ��ںС��������Լ�Ҳ�����þ�ȷ�������������Ǵ��Ե���ѧϰ����ʲô�������������Һܿ���ÿ����ѧ���������������ǵײ���������Dz���ͬ�ġ�
������ͼ��һ����������ײ�����������Dz�ͬ��������������м������������Ǹ��ֻ�������״�������ϲ���������dz��������ĸ��ϲ���

ͼƬ���� http://cs231n.stanford.edu/slides/winter1516_lecture7.pdf
һ�����ӵĸ�����һЩ�ĸ�����϶��ɣ����ĸ���������������ԭ�Ӹ�����϶��ɡ����Ծ��Ƕ���Щ���������������˵����һ����ǩ��һ������������������һ���ص��������������ͨ�ͽ����ģ��������Ե�ʹ������Ҫ���һ���̶ȵĹ�ʶ������ô��ɹ�ʶ�أ����������ڽ�С������ʱ����ô������ɹ�ʶ���أ�����һ�����ӣ�����ͨ����ָ��һ����������������С��˵������������ʣ���ʵ��������Ϊ�˼��������ҵ������֣����������Ǿͺ�С������˹�ʶ��������������ָ����һ�����Ȼ����ָ������һ��������Ҳ˵����������С����ѧ����һ���ࡱ���嶼�ǹ�������������Ҫ����������Ԫ���ӣ�ʹ����Щ����ij�����������嶼��ʶ��ɹ��������ھ������ʶ����������IJ�����ʲô���ģ����Ǻ���֪����Ҳ���տ�ʼ����Ҫ�����������٣�����ֻ�С��ְ֡��������衱�͡�����������ô��������Ҫ������ô�����ʡ������������֣�������������Ϊ�������ߵ��ǡ���������������ֱ�����ߵľ��ǡ��ְ֡��͡����衱����������Ҫʶ����������࣬�������ˡ�èè��������һ����������ΪҲ�ǡ�������������ĸ��������������ⲻ�ǡ����������ǡ�èè������ô��������Ҫ�������������èè������Ҳ����ѧ�����ǣ��������߲�����ܳ����ǹ�������������Բ������èè��
��Ϊ���ܹ�����èè������С�����в������������Ҫ��ȡ���ơ�����������������˵�������Ҳ����������ǹ�������������èè���������ǰְֵ�������������Ҫѧϰ�����Ĺ��Ե�������
������Ĺ������ǿ��Է��֣������ֻ��һ�֡���������ָ���������ǵĸо�ϵͳ���Ӿ�����һ������ķ�Ӧ����������һ�������Ƶ������ͬһ��/�������ɹ�ʶ��һ��ָ������ÿ���˵ĸо�ϵͳ��������ṹ���Dz�һ���ģ�����Ҳֻ���ڷdz��ֲڵij̶ȴ�ɱȽ�һ�µĹ�ʶ�����ڷdz���ϸ�ĸ������Ǻ��Ѵ�ɹ㷺��ʶ�ġ�������ǻ����Χ���˴��ϸ��ֱ�ǩ���ֳɸ�������ɴ˸��ָ���Ҳ�Ͳ���������ɫ�����ԣ��ڽ̣��Ա𣬽���ÿ����Ҳֻ�ܺ�ͬһ����ǩ������ij�������ɹ�ʶ������Ҫ�ҵ�һ����ȫ���˽⡱�Լ����������֮�ѣ�����ͬ�����ֵĹ�ʶ���ܾ����ˡ����Ծ���ׯ�ӡ������ۡ���˵�ġ�ë�͡���������֮����Ҳ�����֮���룬���֮�߷ɣ���¹��֮���衣������֪����֮��ɫ�գ����ҹ�֮������֮�ˣ��Ƿ�֮Ϳ����Ȼ���ң������֪��磡��ë�͡������������������е���������������㿴��ֻ�ǿ��µĵ��ˡ���Ц��������������ȴ��Ҫ����ׯ�ӵ�Ը�⣬��Ϊ��������Ϊ���������ǵ������ų�������������ġ���˵�����ʹ��������ԣ���Ҳ�Ǻ��Ѵ�ɹ�ʶ�ģ���Щ���˹��ҵ���Ů�������й����Ǻ��ٻ���Ϊ��������Ů�ġ�
��˴������������˵������Ҳ����û�����������е���ô�ߴ��ϡ� ��Ŀǰ�˹����ܻ������ѧϰ��ˮƽ��˵��Ҳ���о�С���ڽ������Ӹ���֮ǰ����Ϊ�����ô���
Part II ��Image Caption Generation�������ѧϰ(2)
2. ����ѧϰ���������ǰ��������
2.1 ����ѧϰ��������
��ҿ���ƽʱ��д���ܶ����д����ͻ���ѧϰ��˼·������һЩ��ͬ��д����ʱ�������ǡ��ϵۡ������ǹ涨�������ÿһ�����裬��һ����ʲô�ڶ�����ʲô�����dz�֮Ϊ�㷨�������ܹ��������е��������������κ����⣬�϶����dz���Ա�����Ρ����ڻ���ѧϰ��ʱ������ֻ�ǡ���ʦ�������Ǹ���ѧ�����������������ʲô�������ʲô��Ȼ���������ܹ�ѧ�����������Ƶ�֪ʶ���������Ǹ�С��˵���ǹ�������è������û�а취���ϵ��������š�������������ȥ���������� ��Ԫ�����ӷ�ʽ������ֻ�ܲ��ϵĸ�С����ѵ�����ݡ���Ȼ���������ܹ�ѧ��ʲô��è����ʹ���Ǿ�������ѧ�ᡱ��ʶ��è������Ҳû�а취֪�����ǡ���ô��ѧ�� �ģ�����ͬ����ѵ�����̿��ܻ�һ���˾Ͳ���ʹ��
����ѧϰ�������ѧϰ�����Ƶġ�������Ҳ�Ǹ���ѵ�����ݣ�Ȼ����������ѧ�ᡣ���ǻ��������һ��ģ�ͣ�����ѧ�ĽǶ���˵һ��ģ�;���һ����������������һ����һ����������Ȼ�����Ƕ�ά�ľ�����ͼƬ������ά������������Ƶ�������������������ɢ�ı�ǩ�硰è�����������������������dz�֮Ϊ���ࣻ�������� ��������ֵ���������ģ����Ԥ�����£���ô���Ǿͳ�֮Ϊ�ع顣��ʵ����ĺܶ��ѧ����ճ���������ڡ�ѧϰ��ģ�ͺ͡�Ӧ�á�ģ�͡����翪����ͨ���۲� �����������ݡ����ɡ������ǵ��˶����ɡ��ӱ����Ͻ������ܾ��Ǵӡ���ȥ��ѧϰ��Ȼ����ݡ����ڡ���Ԥ����ܵĽ����������Լ���Ŀ��ѡ���������Լ���Ϊ��ֻ����֮ǰ���ƺ�ֻ�������ܹ��������С�ѧϰ�������ɣ����˹����ܵ�Ŀ������û���Ҳ�����Ƶ�ѧϰ������
ģ������ѧ��˵����һ���������������Եĺ�������Ԫ�����ӹ��ɣ���������һ���ܸ��ӵĺ������������ڻ����ѳ����о�����������������ͼͨ��������� ģ��ͽ���������ģ�ͣ�������������Ҫ����������֮�⣬����ѧϰ�����и��ָ�����ģ�ͣ����Ǹ����ص㡣��������ʽ��ô�仯�����ʶ���һ��������һ�������߸�ȷ����һ�֣�ģ��һ�㶼��һ�ֺ�����ʽ������һЩ�����������Ըı䡣��ѧϰ�Ĺ��̾��Dz��ϵ�����Щ������ʹ��������������ӽ�����ȷ���Ĵ𰸡� ����һ������º������е��������Ƕ���Ԥ����ȷ������һ�����ǻᶨ��һ��loss function����������Ϊ�����ij̶ȣ�����Խ�����ס���loss��Խ�����ǵ�Ŀ����ǵ�������ʹ��loss��С��
�����������ڡ�ѵ���������ϵ����IJ�������ô�����ڡ����ԡ�������Ҳ���ֵĺ����������ģ�͵ġ������������ˡ��ͺ�����ѧУѧϰһ�����е�ͬѧ������һ ģһ������ͻᣬ���ǿ���ʱ���ı�һ�¾Ͳ����ˣ�����ǡ�����������̫�ѧ���IJ�����ʵĶ���������ƽʱ�ᶨ����һЩ��ģ�⿼�ԡ���������ѧ���Dz� �����ѧ���ˣ�������ò��ã��Ǿʹ��ȥ����ѵ��ģ�͵������������ڻ���ѧϰ���Ӧ�ľ���validation�ĽΡ�������յĿ����ˣ��������ռ��� ��ʱ���ˣ�����Ծ������Ŀ�Dz�����ǰ���˿����ģ�ֻ���ó�����һ�Σ�������������ˡ���Ӧ������ѧϰ�����test�Ρ�
��Ȼ������ͨ�Ļ������˻���ѧϰ����Ҫ���мල��ѧϰ����ʵ����ѧϰ�����ල��ѧϰ��ǿ��ѧϰ��ǰ�߾��Dz����𰸣�ֻ�����ݣ������ܽ���ɣ��������д𰸣����Ǵ𰸲������ھ����㡣�Ҹ��˾�����������������Ǽලѧϰ��ǿ��ѧϰ�����������������˵��ǿ��ѧϰ�ǻ�ȡ��֪ʶ��Ψһ;����Ҳ�������� Ȼѧϰ����������һ�����ߣ���û�����Ҫ�ܳ�һ��ʱ��������ֳ�������ѧϰ��������Щ֪ʶͨ���ල�ķ�ʽ��ͨ����ͥ��ѧУ�Ľ����̸���һ����
����������˼ķ�Ϊ��ɢ�������������������У�ʱ�ģ�������Ȼ���ԣ��ı�����һ���ַ��������� ���������ǵ�Image Caption Generation��������һ���������С�����и����ӵ����������parsing�������һ�������
2.2 ���������
ǰ������˻���ѧϰ�Ļ���������������Ǿ���ѧϰһ�������硣�������е�˵�������ѧϰ������ʵ���ָ�ľ��ǡ���������硱����ô�����������˽�һ�¡�dz�������硱��Ҳ���Ǵ�ͳ�������硣�����������Ҫ����http://neuralnetworksanddeeplearning.com��ǰ���¡�
2.2.1 ��д����ʶ������
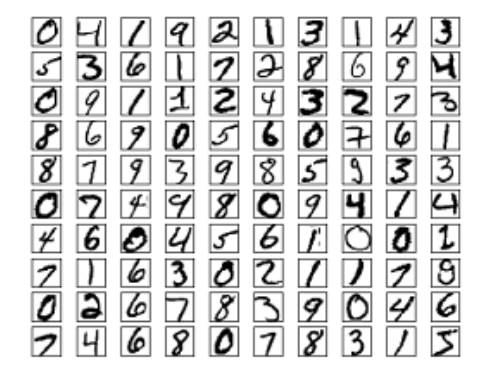
������ѧϰһ���µ�����ʱ��дһ��hello world����mnist���ݵ���д����ʶ�����һ���ܺõ�ѧϰ����ѧϰ���������ѧϰ����һ��hello world����
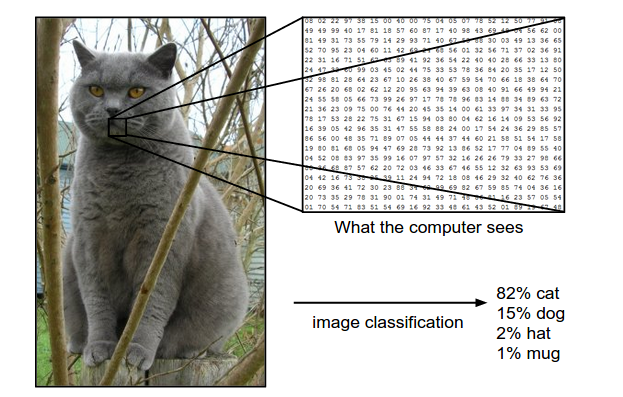
���������������ƺ��кܴ�IJ�ͬ���ܶ�������Ϊ���ӵĹ��������������Ϊ�ܼ���������Ϊ�ܼ������������ܷdz��Ѵ������������ֵļ��㣬���䣬�����ȷ�Ⱥ��ٶȶ�ԶԶ��������������ʶ��0-9����д���֣����Ǿ��ú�����ٵ����飬�ü��������������ȴ�쳣���ѡ�����������������������Ӿ�ϵͳ�����Ǵ���û����ʶ����ʱ����Ѿ���������������ֵ�ʶ�𣬰���Щ���ӵ��Ӿ���������������ڲ��������������������Լ�дһ��������ʶ�����ֵ�ʱ����Щ���Ѳ������ֳ��������ȣ����ڼ������˵�������������IJ������֣��������DZʻ���������������ֻ��һ����λ�ľ������飩��ÿ���㶼��һ�����֡�������ͼ�����ǡ�������������ߵġ�è������ʵ������������������ұߵ����ػҶ�ֵ����Ȼ�����Ӿ�ϵͳ������Ĥ������Ҳ�����Ƶ�һЩ����ֵ����ֻ�������ǵ��Ӿ�ϵͳ�Ѿ���������Щ��Ϣ���Ұ���ʶ����ˡ�è�������������Ի�����ӳ�䣩��
MNIST���ݽ��ܣ�MNIST��ÿ��ͼƬ�������ź;��е�Ԥ����֮��С��28*28��ÿ���㶼��0-255�ĻҶ�ֵ����ͼ��һЩ�������ܹ���60,000��ѵ�����ݣ�0-9��10�����ÿ�����6,000������10,000���������ݡ�һ�����60000���е�50000������ѵ��������ʣ�µ�10000����������֤��������ѡ��һЩ����������
��������Լ���дһ�����㷨��ʶ�����֡�9�������ǿ��ܻ���ô���壺9�������и�ԲȦ�������ԲȦ�����²�����һ����ֱ�ıʻ���˵�����ܼ�������㷨 ��ʵ�־ͺ��鷳�ˣ�ʲô��ԲȦ��ÿ���˻���ԲȦ����ͬ��ͬ����ֱ�ıʻ���ôʶ��ԲȦ����ֱ�ʻ����Ӵ���ôѰ�ң��������ģ�����������Ȥ���Գ���һ���� ����ķ�������ʵ����������ʶ�����������˼·��
����ѧϰ��˼·��ͬ��������Ҫ��ôϸ�ڵġ�ָʾ�������Ӧ����ô�������Ǹ�������㹻�ġ�ѵ����������������������ͬ��10�����֣�Ȼ��������ѧ���� ����ǰ������Ҳ���ˣ����ڵĻ���ѧϰһ����һ����������ģ�͡��������һ������ģ�ͣ�f(w;x)=w0+ w1*x1+w2*x2��������ǵ�������������������x1��x2����ô���ģ����3������w0,w1��w2������ѧϰ�Ĺ��̾���ѡ�����š��IJ������� �������mnist���ݣ��������28*28=784ά��������
����á�ԭʼ����������Ϊ�������������Ե�ģ�ͺܿ���ѧ��һЩ������������������1һ���Ƿֲ��ڴ��ϵ��¾��е�һЩλ�ã���ô������Щλ��һ�������бȽϴ�ĻҶ�ֵ����ô���������жϳ�1�����һ�����ص�2Ҳ�������֣���3�����֣���ô������ѧ�����������س��֣���ô���������2��3�Ŀ����Ծʹ�һЩ��
���������ġ����������ܲ��ǡ����ʡ��ģ���Ϊ��д�ֵ�ʱ�����ƽ��һ�㣬��ô��֮ǰ��ѧ�����IJ����Ϳ��������⡣���������ʡ���������ʲô�أ����ܻ�����֮ǰ�����ܽ�ġ���9�������и�ԲȦ�������ԲȦ�����²�����һ����ֱ�ıʻ������ǰ�ʶ��һ�����ֵ�����ת����ԲȦ����ֱ�ʻ������⡣��ͳ�Ļ���ѧϰ��Ҫ��������ȡ�����ơ���������ȫ�ǣ������ʻ������ġ�����������Щ������������ص���������ӡ����ʡ�������Ҫ����ȡ����Щ������Ҫ�ܶ�ġ�����֪ʶ������ͼ�����ļ���������ʹ�ô�ͳ�Ļ���ѧϰ������������⣬���Dz�����Ҫ�ܶ����ѧϰ��֪ʶ������Ҳ��Ҫ�ܶࡰ����֪ʶ��ͬʱӵ�����������֪ʶ�DZȽ��ѵġ�
�������ѧϰ�����֮���Ի��ȣ����к���Ҫ��һ��ԭ����Ƕ��ںܶ����⣬����ֻ��Ҫ������ԭʼ���źţ�����ͼƬ������ֵ��ͨ������㡱�����磬�õײ������ѧϰ�����ײ㡱�������������������״�����м�IJ�ѧϰ������һ��������������۾����Ӷ��䡣�����ϵIJ��ʶ�������һ��è����һ������������Щ���ǻ���ѧϰ�����ģ����Ի�������Ҫ�����֪ʶ��

�����ͼ��˵������һ�㣬�������Ƿ���Խ�ǵײ��������Խ��ͨ�á���������è���ӻ��ǹ��۾��������õ��Ķ���һЩ��������״��������ǿ�����Щ֪ʶ��������transfer���������Ҳ����transfer learning���������ǽ���CNN��ʱ���ἰ��
2.2.2 ������Ԫ�Ͷ��������(MLP)
����������������Ǻ�����Ĵ�����Щ��ϵ�ģ����Ҽ�ʹ�����ڣ��ܶ����õĶ�����CNN��Attention�����кܶ�����ѧ�о����ԵĽ���ġ����������ҾͲ�������Щ�����ˣ�����Ȥ�Ķ��߿�����һЩ�������˽⡣
һ����Ԫ����ͼ�Ľṹ��
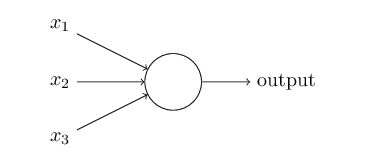
����������һ��������(x1,x2,x3)�������һ��������һ��ʵ����z=w0+ w1*x1 + w2*x2 + w3*x3��z������ļ�Ȩ�ۼӣ�Ȩֵ��w1,w2,w3��w0��bias����� output = f(z)������fһ�������������������еļ������Sigmoid��������Ȼ���ڸ�����Relu�����ĸĽ��汾��Sigmoid�����Ĺ�ʽ��ͼ�����£�
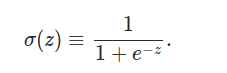
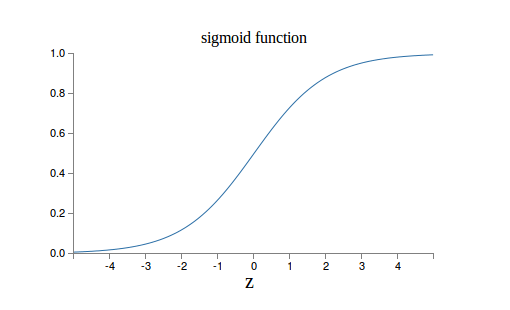
��z=0ʱ��sigmoid(z)=0.5 z���������ʱ��sigmoid(z)������1��z���ڸ����ֵ����0��Ϊʲôѡ�������ļ�����أ���Ϊ��ģ�����Ե���Ԫ�����Ե���ԪҲ�ǰ�������ź�����Ȩ�ۼӣ�Ȼ���ۼӺ��Ƿ�һ������ֵ���������������������һ����Ԫ�����źţ�����Ͳ����͡�������Ե���Ԫ������һ����Ծ������
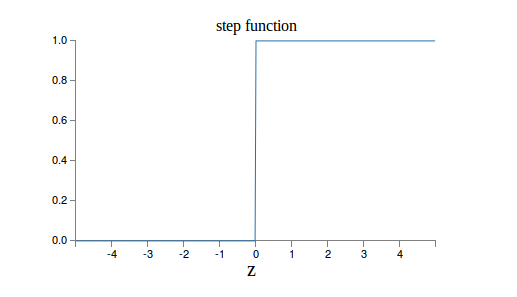
����ĸ�֪��(Perception)��ʵ�õľ���������������������һ��ȱ�����0֮������е�ĵ�������0����0��ĵ�������������Ժ������ݶȵķ����Ż�����Sigmoid�����Ǵ����ɵ����������ֹ��Ƶ���һ�£������Ҳ���Ϥ���������Ƶ�һ��Sigmoid�����ĵ��������Ǻ���Ҳ���õ���
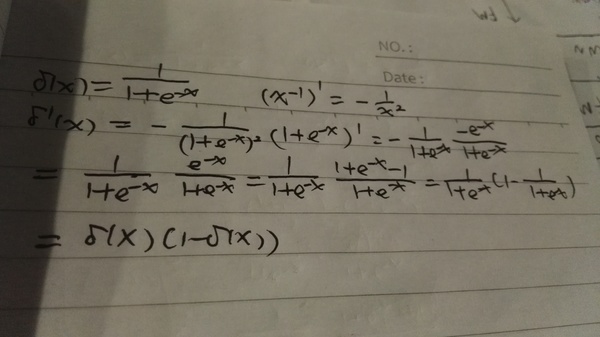
���ǰ�����ĵ�����Ԫ���ղ����֯�������Ƕ��������硣
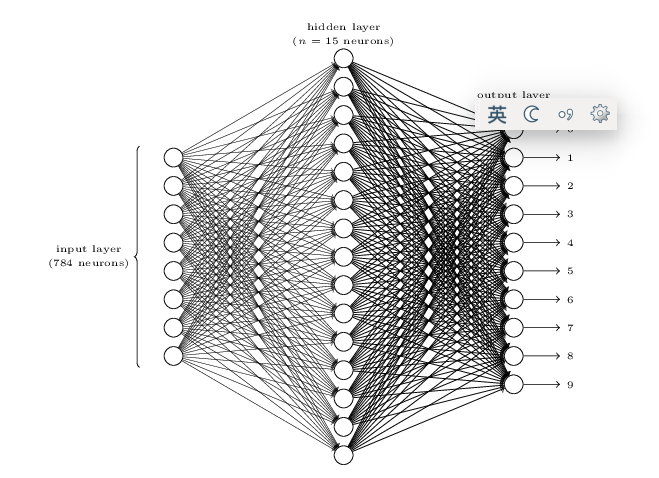
�������ǵ���д����ʶ���������784ά������������ĵ�һ�㣬Ȼ���м���15��hidden����Ϊ���Dz�֪������ֵ����Ԫ��Ȼ���������10����Ԫ���м������ÿ����Ԫ�����붼��784��ԭʼ����ͨ������Ĺ�ʽ��Ȩ�ۼ�Ȼ����sigmoid�����������ÿһ����ԪҲ���м�15����Ԫ���ۼ�Ȼ������ͼ����һ��3��������硣
����һ��28*28��ͼ�����ǵõ�һ��10ά���������ô��ô�����أ���ֱ�ӵ��뷨���ǰ���Ϊ�����Ǹ��������������ǣ�10,11,12,13,14,15,16,17,18,19)����ô������Ϊ�����9��
��Ȼ�������������������һ�ξ��������ۼ�֮����Sigmoid����������Ǽ�һ��softmax�ĺ�������10���������������1,��������һ�� ���ʡ�������������������Ȼѵ�����ݵ������������1,����ʵ�ʸ�һ���������룬����������ܿ��ܲ���1������Ϊ����Nielsen������һ�£����ǻ� ���������ַ�����
��ˣ���������������Щ�������ܹ���784*15 + 15(w0���߽�bias) + 15*10 + 10�������Ǻ�����ͨ������Ĺ�ʽһ��һ���ļ����10ά�������Ȼ��ѡ�������Ǹ���Ϊ����ʶ��Ľ����������ѵ������ô ѡ����ô�������Ȼ��ʹ�����Ƿ���Ĵ������١�
��������ôѵ���أ�����һ��ͼƬ�������������֡�1������ô����������������ǣ�0,1,0,0,0,0,0,0,0,0)���������ǿ��Լ�����Сƽ��������Ϊ��ʧ��������������ܻ���Щ���ʣ����ǹ�ע��ָ��Ӧ���Ƿ���ġ���ȷ�ʡ������ߴ����ʣ�����ô����Ϊʲô��ֱ�Ӱѷ���Ĵ�������Ϊ��ʧ�����أ�����������ѧϰ�����IJ���������С�������ʡ�
��Ҫ��ԭ����Ǵ����ʲ��Dz�����������������Ϊһ��ѵ���������������ȷ��ô����1���������0�������Ͳ���һ�������ĺ�������������������Է�������f(x)=w0+w1*x1+w2*x2�����f(x)>0���Ƿ�������1���������Ƿ�������2�������ǰ��w0+w1*x1+w2*x2<0�����Ǻ�С�ĵ���w0(����w1,w2)��w0+w1*x1+w2*x2��ȻС��0������ʵ�϶���������ӣ�ֻҪ��w0��С�����ǵ��ۼӶ���С��0�ġ�����f(x)��ֵ����仯����w0һֱ����ʹ�ۼӺ͵���0֮ǰ������仯��ֻ�д���0ʱͻȻ���1�ˣ�Ȼ��һֱ����1�����֮ǰ�Ĵ����ʶ���1��Ȼ���ͻȻ��0�����������Ǹ������ĺ�����
��Ϊ����ʹ�õ��Ż��㷨һ���ǣ�������ݶ��½����㷨����ÿ�ε�����ʱ������ͼ��һ��С�IJ�������ʹ����ʧ��С�����Dz������ĺ�����ȻҲ���ɵ���Ҳ��û��������㷨���Ż�������
�������ʹ������Сƽ�����(MSE)��ʧ������
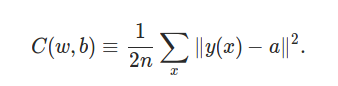
y(x)��������������������д��f(x)��һ�ϰ��һ�㡣a��Ŀ�����������統ǰ����������1����ô����������������ǣ�0,1,0,0,0,0,0,0,0,0)��
���������ʧ�����Dz���w��������������Ϊy(x)����������������ÿ����Ԫ����������������Լ�Ȩ�ۼӣ�Ȼ��ʹ��sigmoid����������ʹ������Ľ�Ծ�����Ͳ������ˣ����Ժ���ʹ����Sigmoid��������Ȼ��ÿһ�����Ԫ��������һ�����Ԫͨ�������ķ�ʽ����ģ�ֻ����ÿ����Ԫ�IJ���Ҳ����Ȩ���Dz�ͬ����ֵ���ѣ���������Щ���������ĸ��Ϻ���Ҳ�������ġ�
��������ʧ���������ǵ������Ż�Ŀ���ǡ����¡�һ�µġ�����C(w,b)����0ʱ������Ҫ��y(x)����a����ô���ǵķ���Ҳ��������ȷ����Ȼ���ܴ���һ�ּ��˵������������3��ѵ�����ݣ���һ���������������ȷ��2��ѵ�����ݣ����Ǵ�����1�����ĺܡ����ס���Ҳ����y(x)��a��༫���ڶ������������ȷ������1��ѵ�����ݣ����Ǵ�����������������̫���ô���������MSE����ȷ�ʲ���һ�¡�
2.2.3 ����ݶ��½�(Stochastic Gradient Descent)���Զ����ݶ�(Automatic Derivatives)
����˵�ˣ���������һ����������ģ�ͣ�ѵ���Ĺ��̾��Ǹ���ѵ�����ݺ�loss function��ѡ�����š��IJ�����ʹ��loss����С���������ѧ����������һ���Ż����⡣�⿴�����ƺ�����ʲôֵ��һ������⣬Ҳ���㻹�ǵ��� �����֪ʶ����ֵ��ĸ��ֳ�ֱ�Ҫ�����������Ҫ�����ǵ�����0��Ȼ��ֱ�ӰѲ����������������ʵ�����еĺ���Զ�Ƚ̿�����ѧ���ĸ��ӣ��ܶ�ģ�Ͷ����� �����ķ�ʽ������Ž⡣������ʵ�ķ�����������ֵ���⣬һ������ķ������ǵ����ķ������������ڵIJ��������Ǻ�С���ȵĵ���������ʹ��loss��Сһ ��㡣Ȼ��һ��һ���������ܹ��ﵽһ�����Ž⣨һ���Ǿֲ����Ž⣩������ôС�������أ�����ͷ��Ӭ�������������ȻЧ�ʼ��͡��������Ҫ����һ����ʹ���� ֵ��С�ķ���ǰ��������һ������ʹ����ֵ��С�ķ�����������������һ���������½��ٶ����ģ��Ǿ����ݶȡ���˸������ķ��������ڵ�ǰ���������ݶȣ� Ȼ�����ݶȵķ����½������ݶȵķ����߶�Զ�أ�һ����һ���Ƚ�С��ֵ�DZȽϰ�ȫ�ģ����ֵ���ǡ���������һ��տ�ʼ����ij�ʼ��������loss�Ƚϴ� ���Զ���һЩҲû��ϵ�����ǵ��˺��棬�Ͳ�����̫�죬��������״������ŵĵ㡣
��Ϊloss������ѵ�����ݵĺ�����������loss���ݶ���Ҫ�������е�ѵ�����ݣ����ںܶ�task��˵��ѵ�����ݿ����ϰ�����һ�δ���̫������һ ��ᡰ������IJ����ٲ������ݣ�����128�����ݣ��������ݶȡ���Ȼ128������ݶȺ�һ��������Dz�һ���ģ����ǴӸ�������������һ�µķ������������ ���ķ�������Ҳ��ʹloss��С����Ȼ���128�ǿ��Ե����ģ���һ�㱻����batch size����˵ľ���batch��1��һ������ô�ֱ����online learning���˻����ݶ��½���batch sizeԽ����һ���ݶȵ�ʱ���Խ�á���Ȼ����GPU��������SSE��ָ�һ�μ���128�����ܲ����ȼ���1�������١�������ݶȺ������ݶ�һ�� �ĸ��ʾ�Խ���ߵķ��������ȷ����batch sizeԽС������һ�ε�ʱ���Խ�̣������ܷ���ƫ�����ŵķ����Զ�����ڲ��ǡ�ԩ��·������ʵ�ʵ����Ҳ����˵�ĸ�ֵ�����ŵģ�һ��ľ���ȡֵ���Ǽ� ʮ��һ���ٵķ�Χ��������Ϊ����������ֽڶ��룬32,64,128������ֵҲ�������ӿ����������ٶȡ�����ʵ��Ҳ�ܶ���ѡ��10,50,100���� ��ֵ��
���˳���������ݶ��½������в��ٸĽ��ķ�������Momentum��Adagrad�ȵȣ�����Ȥ�Ŀ��Կ���http://cs231n.github.io/neural-networks-3/#update �����滹�и��������Ƚ��˲�ͬ�����������ٶȵıȽϡ�
ͨ������ķ��������ǰ�����������ô��loss�Բ���W���ݶȡ�
���ݶ�������4�ַ�����
-
�ֹ��������
���� f(x)=x^2�� df/dx=2*x��Ȼ������Ҫ��f(x)��x=1.5��ֵ������ȥ��2*1.5=3
-
��ֵ��
ʹ�ü��Ķ���:
-
�������ż���
�û������������㣬ʵ��1�ķ��������ǻ�������Ż��IJ��õĻ����ܻ���һЩ����Ҫ�����㡣
���� x^2 + 2*x*y + y^2��ֱ�Ӷ�x��������� 2*x + 2*y�����γ˷�һ�μӷ֣��������ǿ��Ժϲ�һ�±��2*��x+y)��һ�γ˷�һ�μӷ֡�
-
�Զ��ݶ�
�����һ�����ϸ��һ�£�����������ʱ������
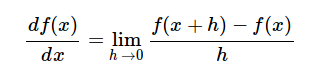
��Щ��������ȱ�㣺
-
�ֹ���⡰��ѧ��Ҫ��ߣ��п���ˮƽ�����ԣ���Ч��Ӧ���������ŵġ�
-
û�κκ���������û�н�������������¶���ʹ�ã�ȱ���Ǽ�����̫����ֻ�ǽ��ƽ⡾��Ϊ���Ķ��塿����ijЩ�ر��������ĵط��������ϴ�����ʵ��ʹ���Ǻ��٣�ֻ����������֤���������Ƿ���ȷ��
-
�������ż��㣬ǰ��˵�ģ������������ĺû���
ʵ�ʵĿ�ܣ���TensorFlow�����Զ��ݶȣ���Theano���Ƿ����ݶȡ�
2.2.4 ���ʵս
ͨ������Ľ��ܣ�������ʵ�Ϳ���ʵ��һ�������ǰ��(feed forward)�������ˣ���������ṹ�ܼ�ÿһ���������ǰһ�������������û�����룬������ԭʼ���ź����롣������һ���������Ԫ�������ӵ���һ���������Ԫ���������Ǹղŵ����ӣ�������784���м����15����ô����785*15�����ӡ��ټ���ÿ���м�ڵ���һ��bias������������������ʱ��Ҳ����ȫ���ӵ����磨full connected)��������CNN���ֲ���ȫ���ӵ���������������������ź��Ǵ�ǰ���ݣ�û�з���������Ҳ��ǰ�������磬����Ϊ�˺�RNN�����з���������
��Ȼ�����ǻ�û�н���ô�����ݶȣ�Ҳ������ʧ���������ÿһ��������ƫ����������һ�������ǻ���ϸ���۽��ܣ����������Ȱ�������һ���ںеĺ����ͺ��ˡ�
-
����
��������ѧϰһ��Nielsen�ṩ�Ĵ��롣����dz���ֻ࣬�в���100�д��롣
https://github.com/mnielsen/neural-networks-and-deep-learninggit clone https://github.com/mnielsen/neural-networks-and-deep-learning.git
-
����
����һ�� test_network1.py���������´��룺
import mnist_loader
import networktraining_data, validation_data, test_data = mnist_loader.load_data_wrapper()
net = network.Network([784, 30, 10])
net.SGD(training_data, 30, 10, 3.0, test_data=test_data)�����ֱ������ Python test_network1.py��������������������30�ε����������ڲ��������ϵ�ȷ�ʴ����95%���ң���Ȼ��Ϊ�����ʼ��������ͬ�����յĽ������������ͬ��
Epoch 0: 8250 / 10000
Epoch 1: 8371 / 10000
Epoch 2: 9300 / 10000
......
Epoch 28: 9552 / 10000
Epoch 29: 9555 / 100003. �����Ķ�
Python����������Ķ�����ʹ֮ǰû���ù�����ѧϰ����Ҳ�Ϳ������֣����Ҵֻ���ѧϰ��صĴ��벻���õ�̫���ӵ��������ԣ���������һЩ��ѧ�����Դ��������㡣��Python��numpy��������õ����ģ������Ķ������ʱ���һ���õ��ĺ�����һЩ���ܣ�����������Ķ�֮ǰ���黨ʮ�����Ķ�һ��http://cs231n.github.io/python-numpy-tutorial/��
3.1 mnist_loader.load_data_wrapper����
�������������ȡmnist���ݣ������Ƿ���data/mnist.pkl.gz���������Ǹ�gzip��ѹ���ļ�����Pickle�������л������̵ĸ�ʽ������ϤҲû�й�ϵ����������֪����������ķ���ֵ�����ˡ�
������������������ֱ����training_data��validation_data��test_data��
training_data��һ��50,000��list��Ȼ�����е�ÿһ��Ԫ����һ��tuple��tuple�ĵ�һ��Ԫ����һ��784ά��numpyһά���顣�ڶ���Ԫ����10ά�����飬Ҳ����one-hot�ı�ʾ�������������ȷ�Ĵ�������0����ô���10ά�������(1, 0, 0, ��)��
��validation_data��һ��10,000��list��ÿ��Ԫ��Ҳ��һ��tuple��tuple�ĵ�һ��Ԫ��Ҳ��784ά��numpyһά���顣�ڶ���Ԫ����һ��0-9�����֣�������ȷ�����Ǹ����֡�
test_data�ĸ�ʽ��validation_dataһ����
Ϊʲôtraining_dataҪ�������ĸ�ʽ�أ���Ϊ�����ĸ�ʽ����loss������һЩ��
3.2 Network��Ĺ��캯��
�����ڵ���net = network.Network([784, 30, 10])ʱ�͵���init������Ϊ�˼���ƪ�����������ע���Ҷ�ȥ���ˣ���Ҫ�ĵط��һ�����Լ�������˵���������пջ���ֵ���Ķ��������ע�͡�
class Network(object):def __init__(self, sizes):self.num_layers = len(sizes)self.sizes = sizesself.biases = [np.random.randn(y, 1) for y in sizes[1:]]self.weights = [np.random.randn(y, x)for x, y in zip(sizes[:-1], sizes[1:])]��������IJ��������DZ���������self.num_layers=3��Ҳ����3������硣ÿһ�����Ԫ�ĸ������浽self.sizes����������ǹ���biases���鲢�����ʼ������Ϊ�������û�в����ģ�������for y in sizes[1:]������ʹ����numpy��random.randn������̬�ֲ��������������Ϊ�����ij�ʼֵ��ע������������2ά���������������һ�£����������30��hidden unit����ôbias�ĸ���Ҳ��30���Ǿ�����һ��30ά��1ά��������ˣ�ΪʲôҪ��30*1�Ķ�ά�����أ���ʵ��1άҲ���ԣ�����Ϊ�˺�weightsһ�£�������뷽�㣬���ö�ά�����ˡ�����weightsҲ��һ���ij�ʼ������������ע��randn(y,x)������randn(x,y)������������������[784,30,10]��weights�ֱ���30*784��10*30�ġ���Ȼ��ʵweights����ת��һ��Ҳ���ԣ����Ǽ������˷���ʱ��Ҳ��Ҫ��һ��ת�á���ͬ���������в�ͬ�ļǷ�������������ʵ�ִ����ʱ��ֻ��Ҫ��ʱע�����Ĵ�С��������˷�����˷���Լ�������ˣ�����AB����ˣ���������������ǣµ��������ڣ��ĺ������С�
����Nielsen�ļǷ��������ÿһ�о���һ����Ԫ��784����������ôweights(30*784) * input(784*1)�͵õ�30��hidden unit�ļ�Ȩ�ۼӡ�
3.3 feedforward����
��������a��784������������������������10����
def feedforward(self, a):"""Return the output of the network if ``a`` is input."""for b, w in zip(self.biases, self.weights):a = sigmoid(np.dot(w, a)+b)return a����dz��������õ���np.dot��Ҳ���Ǿ��������ij˷�������������һ��Sigmoid���������������������numpy��ndarray�����Ҳ��ͬ����С�����飬��������ÿ��Ԫ�ض�������sigmoid�ļ��㡣��numpy���������universal function���ܶ�������һ�㶼��elementwise��function���Ҿ��ú���������ָ�ֱ�ӡ�
#### Miscellaneous functionsdef sigmoid(z):"""The sigmoid function."""return 1.0/(1.0+np.exp(-z))def sigmoid_prime(z):"""Derivative of the sigmoid function."""return sigmoid(z)*(1-sigmoid(z))�������Sigmoid����������Ҳ��sigmoid_prime��Ҳ����Sigmoid�ĵ���������һ�𡾲��ǵõĻ���ǰ��Sigmoid�ĵ������Ƶ�����
3.4 SGD����
���������ѵ������ڣ���������֮ǰ��ѵ�����룺
net.SGD(training_data, 30, 10, 3.0, test_data=test_data)def SGD(self, training_data, epochs, mini_batch_size, eta,test_data=None):
if test_data: n_test = len(test_data)n = len(training_data)for j in xrange(epochs):random.shuffle(training_data)mini_batches = [training_data[k:k+mini_batch_size]for k in xrange(0, n, mini_batch_size)]for mini_batch in mini_batches:self.update_mini_batch(mini_batch, eta)if test_data:print "Epoch {0}: {1} / {2}".format(j, self.evaluate(test_data), n_test)else:print "Epoch {0} complete".format(j)��һ����������training_data��
�ڶ�����������epochs��Ҳ�����ܹ���ѵ�����ݵ������ٴΣ�����������30�ε�����
������������batch��С������������10�����һ��������eta��Ҳ���Dz�����������3.0����������ṹ�������ܹ����ٸ�hidden layer��ÿ��hidder layer���ٸ�hidden unit��������һ���dz���Ҫ�IJ������Dz�����ǰ������Ҳ���۹��ˣ�����̫С�������ٶȹ���������̫���ܲ�������ʵ�ʵ������û��һ�����ܵ�������Ǹ������ݣ���ͣ�ij��Ժ��ʵIJ����������������̫�������ʵ�����֮���С������Ҫѵ����һ�������磬�����кܶ�tricky�ļ��ɣ�����������ô��ʼ�����������ôѡ��SGD���õ��Ż��㷨�ȵȡ�
���ĸ�����test_data�ǿ�ѡ�ģ�����У����ǵ������Ǵ��˽����ģ�����ÿ��epoch֮����һ�¡�
����Ĵ��½�������ע�͵���ʽǶ�ڴ������ˣ�
for j in xrange(epochs): ## һ������ epochs=30 �ֵ���random.shuffle(training_data) ## ѵ�����������ɢmini_batches = [training_data[k:k+mini_batch_size]for k in xrange(0, n, mini_batch_size)] ## ��50,000��ѵ�����ݷֳ�5,000��batch��ÿ��batch����10��ѵ�����ݡ�for mini_batch in mini_batches: ## ����ÿ��batchself.update_mini_batch(mini_batch, eta) ## ʹ���ݶ��½����²���if test_data: ## ����ṩ�˲�������print "Epoch {0}: {1} / {2}".format(j, self.evaluate(test_data), n_test) ## �����ڲ��������ϵ�ȷ��else:print "Epoch {0} complete".format(j)������evaluate������
def evaluate(self, test_data):test_results = [(np.argmax(self.feedforward(x)), y)for (x, y) in test_data]return sum(int(x == y) for (x, y) in test_results)����test_data���ÿһ��(x,y)��y��0-9֮�����ȷ�𰸡���self.feedforward(x)���ص���10ά�����飬����ѡ��÷���ߵ��Ǹ�ֵ��Ϊģ�͵�Ԥ����np.argmax���Ƿ������ֵ���±ꡣ����x=[0.3, 0.6, 0.1, 0, ��.]����ôargmax(x) = 1��
���test_results����б���ÿһ��Ԫ����һ��tuple��tuple�ĵ�һ����ģ��Ԥ������֣����ڶ�������ȷ�𰸡�
�������һ�з��ص���ģ��Ԥ����ȷ�ĸ�����
3.5 update_mini_batch����
def update_mini_batch(self, mini_batch, eta):
nabla_b = [np.zeros(b.shape) for b in self.biases]nabla_w = [np.zeros(w.shape) for w in self.weights]for x, y in mini_batch:delta_nabla_b, delta_nabla_w = self.backprop(x, y)nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]self.weights = [w-(eta/len(mini_batch))*nwfor w, nw in zip(self.weights, nabla_w)]self.biases = [b-(eta/len(mini_batch))*nbfor b, nb in zip(self.biases, nabla_b)]�������������mini_batch��size=10��tuple(x,y)����eta��3.0����
def update_mini_batch(self, mini_batch, eta):
nabla_b = [np.zeros(b.shape) for b in self.biases]## ����һ��__init__��biases��һ���б��������������ֱ���30*1��10*1## �����ȹ���һ����self.biasesһ����С���б�����������ۼӵ��ݶȣ�ƫ������ nabla_w = [np.zeros(w.shape) for w in self.weights]## ͬ�ϣ� weights������������С�ֱ���30*784��10*30 for x, y in mini_batch:delta_nabla_b, delta_nabla_w = self.backprop(x, y)## ����һ��ѵ������(x,y)����loss��������в�����ƫ����## ���delta_nabla_b��self.biases�� nabla_b��һ����С(shape)## ͬ��delta_nabla_w��self.weights,nabla_wһ����Сnabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]## ��bias���ݶ��ۼӵ�nabla_b��nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]## ��weight���ݶ��ۼӵ�nable_w��self.weights = [w-(eta/len(mini_batch))*nwfor w, nw in zip(self.weights, nabla_w)]## ʹ�����batch���ݶȺ�eta�����������²���weightsself.biases = [b-(eta/len(mini_batch))*nbfor b, nb in zip(self.biases, nabla_b)]## ����biases## ������²����dz���batch�Ĵ�С��10�����е���ʵ��ʱ��������ʵû��ʲô������Ϊ������eta��������ͬ�������������ôeta�൱����0.3(��eta����ͳ���batch�Ĵ�С�ˣ���3.6 backprop����
�������������loss��������в�����ƫ�����������Ȳ���ϸ���⣬���´�����ѧϰ�ݶȵ���ⷽ�������ٻ������ۣ�����������˽�һ�����������������������������һ���ںо��У���ʵ���Ĵ���Ҳ���٣����������֪���ݶȵĹ�ʽ��Ҳ�������ס�
def backprop(self, x, y):
nabla_b = [np.zeros(b.shape) for b in self.biases]nabla_w = [np.zeros(w.shape) for w in self.weights]# feedforwardactivation = xactivations = [x] # list to store all the activations, layer by layerzs = [] # list to store all the z vectors, layer by layerfor b, w in zip(self.biases, self.weights):z = np.dot(w, activation)+bzs.append(z)activation = sigmoid(z)activations.append(activation)# backward passdelta = self.cost_derivative(activations[-1], y) * \sigmoid_prime(zs[-1])nabla_b[-1] = deltanabla_w[-1] = np.dot(delta, activations[-2].transpose())
for l in xrange(2, self.num_layers):z = zs[-l]sp = sigmoid_prime(z)delta = np.dot(self.weights[-l+1].transpose(), delta) * spnabla_b[-l] = deltanabla_w[-l] = np.dot(delta, activations[-l-1].transpose())return (nabla_b, nabla_w)�����������һ��ѵ������(x,y)�ֱ���784*1��10*1��������Ǻ�self.biases,self.weightsһ����С���б���Ȼ���б��е�ÿһ������Ĵ�СҲ��һ�������嵽��������ӣ����nabla_b������������С�ֱ���30*1��10*1��nabla_wҲ������������С�ֱ���30*784��10*30��
Part III ��Image Caption Generation�������ѧϰ (3)
2.2.5 �����㷨���Ƶ�
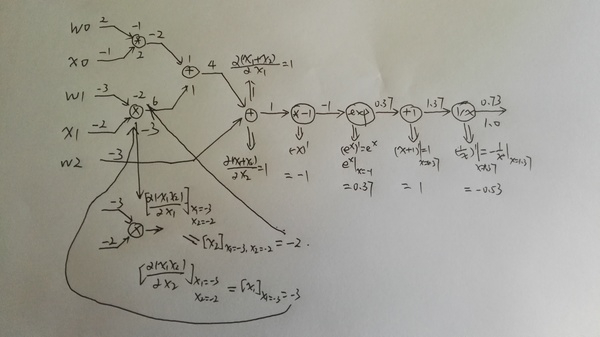
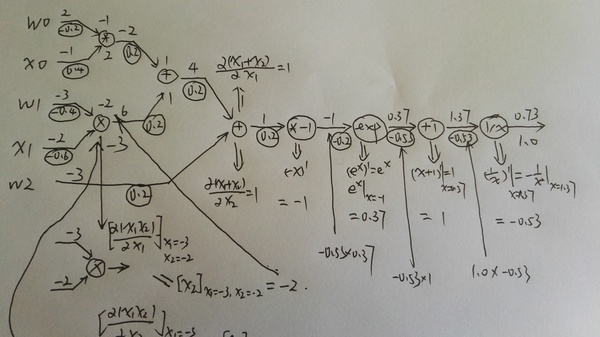
ǰ�������úܼļ�ʮ��python��������������һ����������硣���ǻ�������Ҫ�IJ��֣��Ǿ��Ǽ���loss function�Բ�����ƫ������Ҳ���Ƿ����㷨��������������ϸ����ɹ�ʽ���Ƶ����Լ��������ὲ��ô�ô�����ʵ�֡���һ������ѧ��ʽ��һЩ�����ܺܶ����ϣ������ȥ�������һ��ǽ�������ϸ���Ķ�����ʵ�������õ�����ѧ���svm,bayes network�Ȼ���ѧϰ�㷨���Ѿ��dz����ˡ�������Ķ���ʱ�������һ֧�ʺͼ��Ű�ֽ��ÿһ����ʽ�����Ƶ�һ�¡���������������������ʵͦ�ġ�
(1) feedforward�εľ��������ʾ�ͼ���
֮ǰ�������۵���һ����Ԫ�ļ��㣬���ڴ������õ���ȴ�Ǿ��������˷�������ϸ�ĵĶ��ᷢ�������ڹ����������weights��ʱ�������������ֱ��Ǻ�һ��Ľڵ�����ǰһ��Ľڵ��������ƺ��е㲻��Ȼ��Ϊʲô���������أ�����������һ���־ͻ������ˡ�
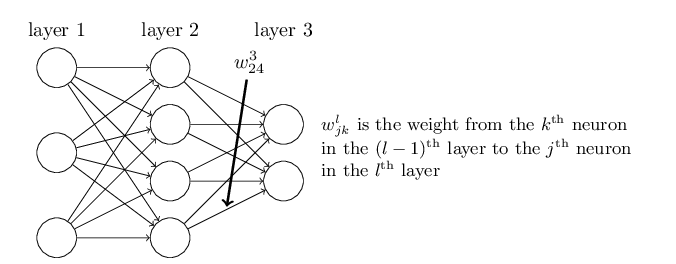
����������Ϥһ�µ�L����ΪСд��L��1̫���������ô�д��L����IJ���w_jk������ʾ��L-1��ĵ�k����Ԫ����L��ĵ�j����Ԫ��Ȩ�ء������3���w_24���ο������ͼ������ʾ���ǵ�2��ĵ�4����Ԫ����3��ĵڶ�����Ԫ��
��bias�ͼ������Ľ��aҲ�������ƵļǺţ�����ͼ��ʾ��
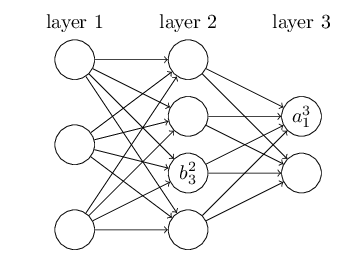
b_32��ʾ��2��ĵ�3����Ԫ��bias����a_13��3��ĵ�1����Ԫ�ļ��
ʹ������ļǺţ����ǾͿ��Լ����L��ĵ�j����Ԫ�����a_jl��
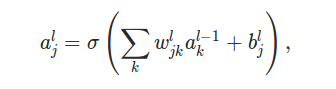
��L��ĵ�j����Ԫ��������L-1���a_1,a_2,...����Ӧ��Ȩֵ��w_j1,w_j2,...��bias��b_jL������a_jL��������Ĺ�ʽ��k�ķ�Χ�Ǵ�1����L-1�����Ԫ�ĸ�����
Ϊ���þ��������˷���һ�μ����L���������Ԫ�������������Ҫ�����L��IJ�������w_l�����Ĵ�С��m*n������m�ǵ�L�����Ԫ��������n���ǵ�L-1��ĸ��������ĵ�i�е�j�о����������涨���w_jk���������ǻ�Ҫ��������b_l�����Ĵ�С��m��Ҳ���ǵ�L����Ԫ�ĸ����������ĵ�j��Ԫ�ؾ����������涨���b_j��
������Ƕ���element-wise�ĺ���������f(x) = x^2�����������һ����������ô����Ǻ�����һ����С������������ÿ��Ԫ���Ƕ�����������ÿһ��Ԫ��Ӧ����������Ľ����
��������Ķ��壬���ǾͿ���һ�μ������L��������һ������Ϊm��������
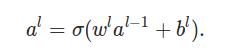
�����Ƕ����������ʽ����ϸ֤����˵������
������Ҫ֤����������aL�ĵ�j��Ԫ�ؾ���ǰ���a_jL

���⣬Ϊ�˷���������⣬���ǰѼ�Ȩ�ۼӺ�Ҳ��һ������z_l����ʾ��
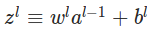
���У����ĵ�j��Ԫ�ؾ��ǵ�L��ĵ�j����Ԫ�ļ�Ȩ�ۼӺͣ�
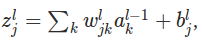
����a_l�Ϳ��ԼĶ�z_l��ÿ��Ԫ�ؼ��㼤���
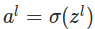
���������ٻع�һ��feedforward�Ĵ���ͷdz�ֱ���ˣ�
def feedforward(self, a):
"""Return the output of the network if a is input."""
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a)+b)
return a��������feedforward�IJ���a������������x����һ�����x���ڶ�����ǵ�һ�����㣬ÿһ��ļ�����Ƿdz��IJ�������w_l������һ��ļ���a_l-1�ڼ���b_l��Ȼ���ü�������㡣
��ʼ����ʱ��w�Ĵ�С�� (��һ�����Ԫ����) * (ǰһ�����Ԫ���������ٻع�һ�³�ʼ�������Ĵ��룺
# sizes = [784, 30, 10]
def __init__(self, sizes):
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
self.weights = [np.random.randn(y, x)for x, y in zip(sizes[:-1], sizes[1:])]x, y in zip(sizes[:-1], sizes[1:]) x�ǵ�һ�㵽������ڶ��㣬y�ǵڶ��㵽���һ�㣬���������sizes=[784, 30, 10]
x��[784, 30], y��[30, 10]��ע������ľ�����(y,x)������self.weights����������С�ֱ���30*784��10*30
(2) ������ʧ����C����������
1. ��ʧ������ÿ��ѵ�����ݵ���ʧ��ƽ��
Ҳ����C����������ʽ��
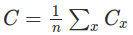
����֮ǰ����ʹ�õ�MSE��ʧ��������������ġ�����ʹ��batch���ݶ��½���ʱ����Ҫ��C�Բ���w��ƫ��������Ϊ��ʧ������ÿ��ѵ�����ݵ���ʧ��ƽ������������ֻ��Ҫ��ÿ�����ݵ�ƫ������Ȼ�������ƽ�����С�������輸�����е���ʧ������������ġ�����û������ʧ�������������������
- ��ʧ���������һ������ĺ���
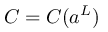
�������������������ʧ�������������ģ�����֮ǰʱ���MSE���Ǽ������һ������aL����ȷ��y(one-hot)�ľ�������Ȼ������ġ�
(3) Hadamard product
������ֿ������ܸ��ӣ���ʵ�ܼ�������������elementwise�ij˷�����һ�����Ӿ�����ˣ�

(4) �����㷨(back propagation)��4����ʽ
�ع�һ�£�����֮ǰ˵�ˣ��ݶ��½���ʵ����ĵ������������ʧ������ÿһ��������ƫ�����������Ǿ�ֱ��һ��һ������ˣ�Ϊʲô��Ҫ���һ�������㷨�أ���ʵ����㷨�ڲ�ͬ������ͬ�����ظ������֡����ܶ�Σ��й��ܶͬ�����֣���ʵ�Ӧ�þ���������reverse-mode differentiation�����߽����Զ���automatic differentiation�����Զ���AD���Ƿdz�ͨ�õ�һ����ƫ�����ķ������������������ѧ�ʹ�������������ʹ�ã������㷨������Ϊ��AD���������е�Ӧ�á��������緢������㷨���ˣ���˭��������е����飩��������֪��AD����ֱ�����������磬����������㷨�ǻ��ڴ���ķ������õ��ģ���������Ϊ������ģ������㷨���������ǻὲ��AD������һ��ǿ����㷨���κ�һ�����������ܰ����ֽ��������ͼ�ļ���ͼ������һ�㶼�ֽܷ��һЩ��������������ı����ĸ��Ϻ�������˿϶����Ա�ʾ������һ��������ͼ����Ȼ��ÿ���ڵ㶼��ʾһ��������ֻҪ�����������������ض�����ݶȡ�Ҳ������������������Ա�����ƫ������������Ҫ�������ƫ��������Ȼ�ܶ��������Щ����������ֱ����������⣬Ȼ���������ض�����У��������������ǿ���������������������ֵ�ݶȽ�������ģ��������Զ��ļ�����ʧ������ÿһ��������ƫ������Ҳ���������ģ�������ֻҪ���������������������ͼһ�ξ��У��dz���Ч�ͼ��������ǻ���ϸ�Ľ���AD����������dz�ͨ�ã�TensorFlow�ĺ��ľ���AD��ʹ��AD�Ŀ�ܾͱȽ������롰���족һ���µ�����ṹ�����ֲ��롾��ʵ�������Dz���Ƶ����ݶȵĹ�ʽ����ô��ֻ��Ҫ���ҵ�������������һ��������ͼ��ʾ���С���Ȼ�ڵ����Ҫ�ܹ�����ݶ�����һ�����ǵĺ��������������㣬�����ȵ�TensorFlow����װ���ˡ�������������һ��op������ֻ��Ҫ���ľһ�����������ͼ���������TensorFlow���Զ����ܸ���AD�������ʧ���������в������ݶ����ˡ���Ȼ�����Ҫ�õ�һ��TensorFlowû�е�op���������Ҫ�������Ĺ淶ʵ�����op��һ��op����ĵĽӿھ���������һ��������x����f(x)����һ��������f��ij��x0����ݶȡ�
����������ǻ�������������ķ�չ��ʷ���Ӵ���ķ����Ƕ���������Ƶ�����㷨��
���ȣ����ǻ��ÿһ����Ԫ�����L��ĵ�j����������һ��������_jL
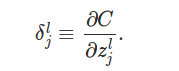
Ҳ������ʧ������zҲ���������ۼӺ͵�ƫ������Ϊʲô��������һ�������أ����Ǽ����ڵ�L��ĵ�j����Ԫ����һ�����飨Daemon��
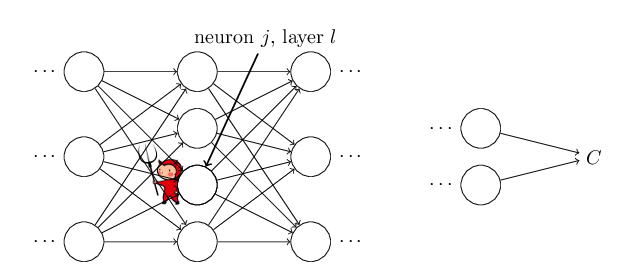
�������Ԫ�õ�������һ�ε������ۼӼ����z_jL��ʱ�����������ĸ�һ���С�ĸ�����z_jL��ԭ����Ӧ�����������(z_jL)�����ڱ������(z_jL +��z_jL)�����С�ı仯��㴫�������յ�����ʧ����CҲ�������µı仯��
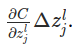
�����ʵ���ǵ�����ֱ�����壺С�Ħ�x����С�Ħ�y����y/��xԼ���ڵ�����
������������Ǹ��þ��飬����������Ǽ�����ʧ�� ��
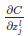
����0��ʱ��������z_jLС��0����֮����С��0��ʱ��������z_jL����0������
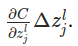
������0
������ǵ�loss�ͻ��С���������ֵԽ�����ǵ���ʧ���ٵ�Խ�ࡣ
��Ȼ���˵Ϊʲô��������z_jL�dz����������ǵ���ʧ���Ǽ��ٺܶࣿ��ϧ��������Ǹ���ѧ�ң���˵�����x̫����ô��y=df/dx *��x�Ͳ�ȷ�ˡ�
�������ǿ���������Ϊ�������ǵ�L��ĵ�j����Ԫ�����𡱵ġ������������ֵ�������ġ����Ρ�Ҳ�����͵ö�����һЩ��������֮�����������0��˵����û��ʲô�����Ρ���Ҳ�Ͳ���Ҫ����ʲô�ı䡣
���ͨ����������������Ƕ������_jL����
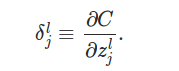
����������������ܷ����㷨��4����ʽ��
��ʽ1. ��L�㣨���һ�㣩 �Ĵ���
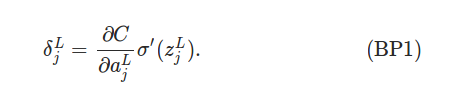
�����ʽ�ĵ�һ�������ʧC��a_jL�ĵ�������Խ��˵��C��a_jL��Ӱ��Ҳ��Խ��������˴���a_jL�ġ����Ρ�Ҳ��Խ����Ҳ��Խ�ڶ�����a_jL��z_jL��Ӱ�졣���߳���������z_jL��������ʧ��Ӱ�죬Ҳ�������ġ����Ρ��Ĵ�С��
�����ʽ�ܺü��㣬���ȵڶ�����ǰ�z_jL��ֵ�������feedforward�ڵ����������洢�����ˣ�������'(x)���������sigmoid����������ǰ��Ҳ�Ƶ������ĵ������ҡ�(x)=��(x)*(1-��(x))����һ�Ȼ��������ʧ�����Ķ��壬һ��Ҳ�ܺ��������ǵ�MSE��ʧ��
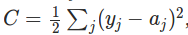
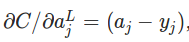
������Ƶ�����ֽ��д��һ�£���Ȼ�ܼ�����Ҳ���������֣������Ƕ������ʽ��չ����ϣ���������Ϥ�����Ժ���Ƶ��ҿ��ܾͲ�չ�����ʽ�ˣ�����Ҫ֪�����ʽ����Щ���Ǻ�������Ա����صġ�
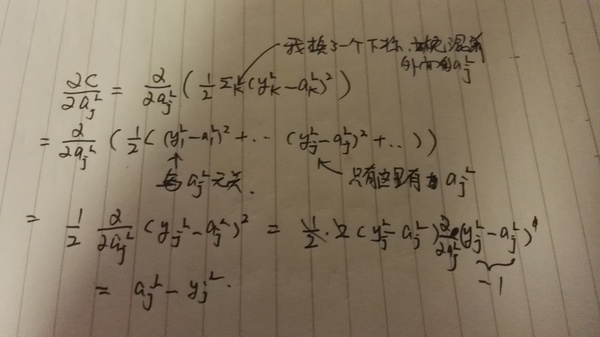
��ʽBP1��elementwise�ģ�������Ҫ����j������ÿһ����_jL������Ҳ������д����������ʽ���Է����������Դ����⣬���ǿ���һ�μ����������߾������úܶ༼������Ӳ���������Ż�������GPU��SSE�ȣ��ٶȡ�
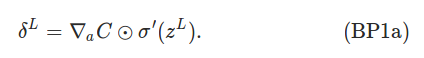
�ұ���'(z_L)���������⣬��ߵļǺſ�����Щ�ѽ⣬��ʵ���ǰ�?aC����һ������ͺ��ˣ�����һ����������һ��Ԫ����?C/?a_1L���ڶ�������?C/?a_2L����
������Ϻ���C��MSE�Ļ�������Ĺ�ʽ�Ϳ��Լɣ�
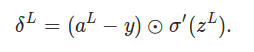
��ʽ2. ��l�㣨�����һ�㣩 �Ĵ���
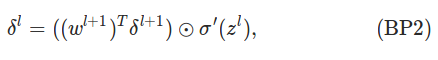
�������ǻ�֤�������ʽ������������������Ϥһ�¹�ʽ����������롰�����������ʽ�Ļ����ƺ��������ȵ�һ��BP1Ҫ���Ӻܶ� �������ȼ��һ�¾����������ά�ȣ�����l+1����m��Ԫ�أ�l��n������w_l+1�Ĵ�С��m*n��ת��֮����n*m,��_l+1�Ĵ�С��n*1�����Ծ�����˺���m*1�������_l��һ���ģ�û�����⡣
������������ϸ�۲�һ��BP2�����ʽ�����ȵڶ�����'(z_l)��ǰ��ĺ���һ��������a_l����z_l�ı仯�ʡ�
����һ���һ�㣬����֪����l��ĵ�j����Ԫ��Ӱ���l+1���������Ԫ���Ӷ�ҲӰ�����յ���ʧC�������ʽֱ�Ӹ���һ��������������ʽ����������������������ڲݸ�ֽ��չ���ˣ�
���յ�L��ĵ�j����Ԫ����ʧ�������¹�ʽ��
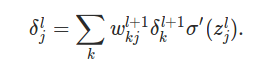
����Ӧ�þͱȽ�����ˣ���l��ĵ�j����Ԫ����ʧ�����ǰ�l+1�����ʧ����������������ȻҪ����Ȩ�أ�Ȩ��Խ�����Ρ�Ҳ��Խ��
���Ҫ�������������ʽҲû����ô�����ˣ��Ȳ�����'(z_l)����һ��Ӧ���Ǿ���w_l+1������_l+1�����ھ�����m*n����
������_l+1��m*1��Ϊ�����þ���˷���������ô��ֻ�ܰ�wת��һ�£����n*m��Ȼ��ͺ�����ס�����ʽ�ˡ�
ע�⣬BP2�ļ����ǴӺ���ǰ�ģ����ȸ���BP1�����һ�����_L�����Ѿ�������ˣ���˿�����ǰ����L-1�����_L-1��
������_L-1���ܼ�����_L-2�����������������һ�����㣨Ҳ���ǵ�2�㣩��_1����
��ʽ3. ��ʧ������ƫ��b���ݶ�
��ǰ����˴���������_l����Ҫ�������ǵ�����Ŀ��������ʧ�����Բ���w��b��ƫ����������������м����z��ƫ������
��������ʽ���Ƕ�b��ƫ������

����д����������ʽ��

?C/?b���Ǧģ�
��ʽ4. ��ʧ������w���ݶ�

���߲ο���ͼд�ɺüǵ���ʽ��
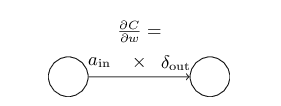
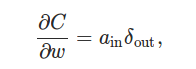
Ҳ����˵����һ����w_jkL��?C/?w_ij��������������ĵ�Ĵ���ij��Խ����ļ���dz��üǡ�
���ǰ����ĸ���ʽ���ܽ�һ�£�

(5) ���ĸ���ʽ��֤��
������BP1����ο���ͼ��

Ȼ����BP2��
�����õ���chain rule����ʵҲ�dz���ֱ�ۣ����Ǹ��Ϻ��������ϡ���ķ���������ͼ������������y����
��x�ĺ���������Ҫ��?y/?x�����y��u,v�ĺ�����Ȼ��u,v����x�ĺ�������ô���ǰѱ���x,y,u,v������ͼ�ϵĵ㣬y��u��v�ĺ�������ô���ǻ��ϴ�u��v��y�ıߣ�ͬ�������ǻ��ϴ�x��u��v�ıߣ�Ȼ���y��x��ÿ��·�������Ǿ����ı߶���һ��ƫ���������ǰ����ۼ��������С�����ʵ���Ǻ������ǻὲ��AD�������?y/?x=?y/?u * ?u/?x +?y/?v * ?v/?x��

ʣ�µ�BP3��BP4Ҳ�dz����ƣ��ҾͲ�֤���ˡ�
�����㷨
1. a_1 = ��������x
2. Feedforward ���ݹ�ʽ
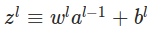
��
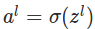
����z_l��a_l���洢����������ʱҪ�õģ�
3. �������һ��Ĵ���
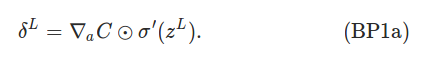
- ��ǰ�������в�Ĵ���
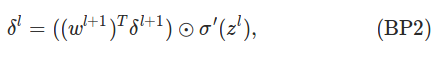
- ������ʧ�����в�����ƫ����


2.2.6 ����ʵ�ַ����㷨
�����Ѿ��ѹ�ʽ�Ƶ������ˣ�����ô�ô���ʵ���أ������ȰѴ��븴��һ�£�Ȼ��˵�����ֶ�����Ϊ�����ע���ˣ�
����ϸ�Ķ���
class Network(object):def update_mini_batch(self, mini_batch, eta):# mini_batch��batch��С��eta��learning ratenabla_b = [np.zeros(b.shape) for b in self.biases]# �����self.biasesһ����С������������ǰ������� sizes=[784,30,10]����# nabla_b��������������С�ֱ���30��10nabla_w = [np.zeros(w.shape) for w in self.weights]# �����self.weightsһ����С�ľ�����ǰ������� sizes=[784,30,10]����# nabla_w����������С�ֱ���30*784��10*30for x, y in mini_batch: #����ÿ��ѵ������x��ydelta_nabla_b, delta_nabla_w = self.backprop(x, y)# ��backprop����������ʧ������ÿһ��������ƫ������# backprop�����������ϸ����nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]# �ѷ��صĶ�bƫ�����ۼӵ�nabla_b��nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]# �ѷ��صĶ�w��ƫ�����ۼӵ�nabla_w��self.weights = [w-(eta/len(mini_batch))*nwfor w, nw in zip(self.weights, nabla_w)]# ������һ��batch����²���wself.biases = [b-(eta/len(mini_batch))*nbfor b, nb in zip(self.biases, nabla_b)]# ����b
...def backprop(self, x, y):# ������x��y��������ʧ����C��ÿ������w��b��ƫ����# ���صĸ�ʽ������Ԫ�飬��һ����b��ƫ�������ڶ�����w�ġ�nabla_b = [np.zeros(b.shape) for b in self.biases]# �����self.biasesһ����С������������ǰ������� sizes=[784,30,10]����# nabla_b��������������С�ֱ���30��10nabla_w = [np.zeros(w.shape) for w in self.weights]# �����self.weightsһ����С�ľ�����ǰ������� sizes=[784,30,10]����# nabla_w����������С�ֱ���30*784��10*30# feedforwardactivation = xactivations = [x] # ��һ��list�������в�ļ������backward�����õ�zs = [] # ͬ������һ��list�������в�ļ�Ȩ�ۼӺ�z������Ҳ���õ���#������δ�����feedwardҲ�У���������������predict�õIJ���Ҫ����zs��activationsfor b, w in zip(self.biases, self.weights):z = np.dot(w, activation)+bzs.append(z)activation = sigmoid(z)activations.append(activation)# backward pass#1. ���ȼ������һ��Ĵ���delta�����ݹ�ʽBP1��������ʧ������a_L���ݶȳ��Ԧ�'(z_L)# sigmoid_prime���Ǧ�'(z_L)����?C/?a_L���Ǻ���cost_derivative������MSE����ʧ������# ���������һ��ļ���activations[-1] - ydelta = self.cost_derivative(activations[-1], y) * \sigmoid_prime(zs[-1])# 2. ���ݹ�ʽBP3,��ʧ��b��ƫ��������deltanabla_b[-1] = delta# 3. ���ݹ�ʽBP4,��ʧ��w��ƫ����ʱdelta_out * activation_in# ע�⣬���ǵĹ�ʽBP4��elementwise�ģ�������Ҫд�ɾ�����������ʽ# ����ôд�أ�����ֻ��Ҫ���ľ���Ĵ�С�����ˡ�# �������һ����m(10)����Ԫ��ǰһ����n(30)����# ��delta��10*1, �����ڶ���ļ���activations[-2]��30*1# ������������һ��IJ���nabla_w[-1]��10*30����ôΪ���ܹ���ȷ�ľ���˷���# ֻҪһ�ֿ��ܾ��� delta ���� activations[-2]��ת�ã���ʵҲ��������delta��activations[-2]�����nabla_w[-1] = np.dot(delta, activations[-2].transpose())# �������ӵ����ڶ���һֱ��ǰ����delta��ͬʱҲ�Ѷ�w��b��ƫ�����������# �����õ�һ���Ƚ�С��trick����python���±���֧�ָ����ģ�-1��ʾ���һ��Ԫ�أ�-2�ǵ����ڶ���# l��ʾ������l�㣬2�ͱ�ʾ������2�㣬num_layers - 1�ͱ�ʾ˳����2�㣨Ҳ���ǵ�1�����㣩# �������ǵ����ӣ�sizes=[784, 30, 10]����ôl���Ǵ�2��3��������3����l��ֻ����2��ҳ���ǵ�1����Ҳ��Ψһ��һ# �������� for l in xrange(2, self.num_layers):# ������l���zz = zs[-l]# �����'(z_l)sp = sigmoid_prime(z)# ����BP2������delta_l,ע��weights[-l+1]��ʾ������l�����һ��delta = np.dot(self.weights[-l+1].transpose(), delta) * sp# ͬ�ϣ�����BP3nabla_b[-l] = delta# BP4������˷��ο�ǰ���˵��nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())return (nabla_b, nabla_w)2.2.7 Ϊʲô�����㷨��һ����Ч���㷨��
��������룬���Ƿ���һ��backprop����������Ҫfeedforwardһ�Σ������ж��ٱߣ����ж��ٴγ˷����ж��ٸ�����ж��ٴμӷֺͼ�������㣨�����һ������㣩���������Ҳ��һ���������ǴӺ���ǰ��Ҳ����˵����ʱ�临�Ӷ�ΪO(n)���㷨��
������Dz��÷����㷨�������������ݶȵĶ��������ֵ�ݶȡ�����ÿһ������wj��
���Ƕ��ù�ʽ limit (f(w1, w2, ��, wj+�� wj, ��) - f(w1, w2, ��, wj, ��)/��wj
f(w1, w2, wj, ��)ֻ��Ҫfeedforwardһ�Σ����Ƕ���ÿ������wj������Ҫfeedforwardһ��������f(w1, w2, ��, wj+�� wj, ��)������ʱ�临�Ӷ���O(n)����ô�����еIJ����ļ�����ҪO(n^2)��ʱ�临�Ӷȡ�
������������1�������������ôÿ����Ҫ10^12��������������㣬�������㷨ֻ��Ҫ10^6�������������ȷ����㷨Ҫ��1����
Part IV �Զ��ݶ���� �����㷨������һ���ӽ�
ǰ�����ǽ����˷����㷨����ϸ�Ƶ����̣���ҿ��ܻ������Щ���ӡ���ʵ����ʵ������ʽ�����Ӧ�á��������ǽ����������������⣬�����Ǵ�Computational Graphs�ĽǶȣ�Ҳ��������֮ǰ˵�����Զ���(Automatic Differentiation or Reverse-mode Differentiation)������ͨ��CS231n��Assignment2��ѧϰʹ�����ַ�����ͨ�����ַ�����ʵ��һ�����������硣
Calculus on Computational Graphs: Backpropagation
�������ǽ���һƪ�������£� https://colah.github.io/posts/2015-08-Backprop/ �����Ƿ���������������ֵط������Լ������⣬������߽����ƪ����һ���Ķ���
���
�����㷨��������ĺ����㷨����������㷨�ڲ�ͬ������Ρ����֡���������в�ͬ�����ơ�
����ͼ(Computational Graphs)
����һ���ĺ��� e=(a+b)?(b+1)e=(a+b)?(b+1) �������������������(����)���ӷ��ͳ˷���Ϊ��ָ�����㣬�������������м������c��d��
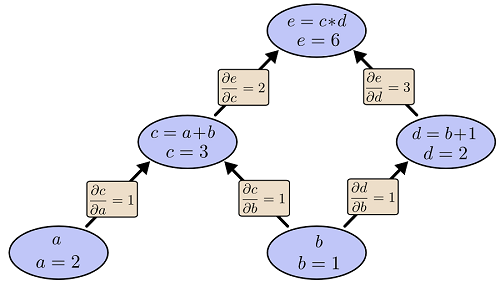
- c=a+b
- d=b+1
- e=c?d
�������ǰ�������һ������ͼ��ÿһ��������ͼ��һ���ڵ㣬������ı���a��bҲ��һ���ڵ㡣ÿ���ڵ�������������ֱ����һ���ߡ�����d�����������b����ôd��bֱ�Ӿ���һ���ߡ�
�κ�һ����ʾ����ĺ��������������У��������Ƕ����������϶�����ͨ�������������壩�����Էֽ�Ϊһ��������ͼ������������Ҷ�ӽڵ�������������������Ա��������м�ڵ�������������м�������������������ǵĺ�����������������ӣ�����ͼ������ʾ��
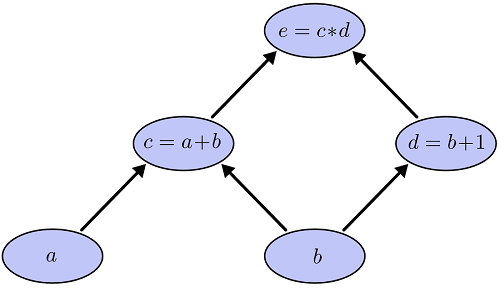
����ÿһ���Ա�����ֵ�����ǿ��Լ������յĺ���ֵ����Ӧ�����������feedforward���㡣�����á��㷨����ô�����أ�������Ϊ����ͼ��һ��������ͼ��������ǿ���������������Ҷ�ӽڵ�a��b�����ǵ�ֵ�Ѿ�������Ȼ��ɾ��a��b�����ıߣ�Ȼ��c��dû���κ�δ֪���������Լ��㣬������e�������������ͼ��
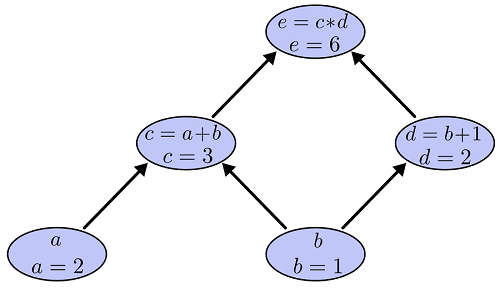
����ͼ�ĵ�������
�������ǿ��Լ���ÿ�����ϵĵ�����Ҳ���DZߵ��յ�����ĵ��������ҵ�����������ȡǰ�����ֵʱ�ĵ��������������ͼ��ʾ��
��Щ�ߵĵ����������������ֵ�����磺
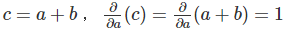
���ǻ��кܶ�ߵĵ���������������ֵ�ģ����磺
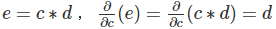
��Ϊ�ڡ�ǰ����Ĺ����У�ÿ���ڵ��ֵ����������ˣ����Աߵļ���ܼ�Ҳ����Ҫ����ʲô��˳��
��������һ��Ƚϸ���Ȥ�������պ�����ij���Ա����ĵ���������
������ʽ����ֻҪ�ҵ��������ڵ������·����Ȼ���·���ı߳������͵õ������ߵ�ֵ��Ȼ������б������Ϳ����ˡ�
�������������b��e������·����b->c->e��b->d->e������
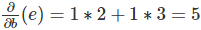
����á���ʽ��������д����
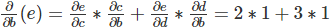
·�����������ѡ�
ʹ������ķ��������ǿ��Լ����κ�һ���㣨����ı�����������һ���㣨����ı������ĵ�������������һ�������Ǽ�������������Ҷ�ӵĵ�������Ȼ���ǿ���ʹ��������㷨һ��һ�����㣬�����������кܶ��ظ��ļ��㡣
����a->e��·���� a->c->e��b->e��һ������b->c->e������c->e���ظ��ġ�������Ӳ�̫�ã����ǿ�������c->e��һ���ܳ���·������ÿ�ζ��ظ�����c->e������ӡ�·���Ƕ���ġ����ǿ��ԴӺ���ǰ���㣬Ҳ����ÿ���ڵ㶼�Ǵ����������(���������e)�Ե�ǰ�ڵ�ĵ�������ʵҲ������������ǰ�ڵ������·���ĺͣ���
����������
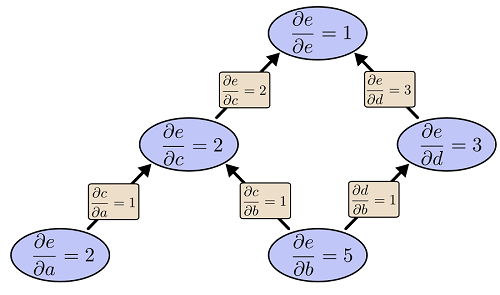
�������������������£�
���Ȼ��Ƕ����ͼ���������������Ƿ�������
������
���ûʲô��˵�ġ�
Ȼ�����
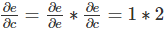
Ȼ�����
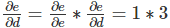
Ȼ�����
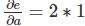
����
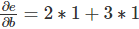
ǰ��������
���������Ҫ����ÿһ��������ijһ�������ĵ������Ϳ���ʹ��ǰ�����ķ������������ǵ������綼���෴��������ij��һ��������һ������ʧ�����������б����ĵ�������������Ͳ���ϸ�����ˡ�
Part V �Զ��ݶ���⡪��cs231n��notes
Optimization
��һ�����������ԣ�CS231n Convolutional Neural Networks for Visual Recognition
���
���ǵ�Ŀ�꣺x��һ��������f(x)��һ������������������һ��������������Ϊ�Ƕ�����ĺ���������������������Ա������������һ��ʵ��ֵ��������Ҫ�������f��ÿһ���Ա����ĵ�����Ȼ��������ų�һ��������Ҳ�����ݶȡ�
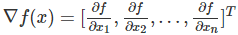
ΪʲôҪ������أ�ǰ������Ҳ���ˣ����ǵ����������ʧ�������տ��Կ�����Ȩ��weights��bias�ĺ��������ǵ�Ŀ����ǵ�����Щ������ʹ����ʧ������С��
�ı���ʽ���ݶȵĽ���
�������ǿ�һ���ܼĺ��� f(x,y)=xy����f��x��y��ƫ�����ܼ�

�������������Ķ��壺
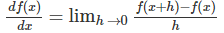
������ij����ĵ������Ǻ���������������б�ʣ�Ҳ����f(x)��x�ı仯�ʡ�
������������ӣ���x=4,y=?3ʱ f(x,y)=?12��f��x��ƫ����
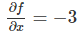
Ҳ����˵��������ǹ̶�y=4��Ȼ���xһ����С�ı仯h����ôf(x,y)�ı仯��Լ��-3*h��
��˳˷����ݶȾ���
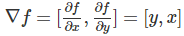
ͬ�����ӷ����ݶȸ���
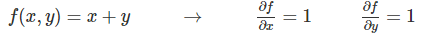
���һ��������max������
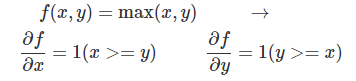
���������ReLU(x)=max(x,0)�ĵ�������ʵҲ����� x>=y����ô max(x,y)=x��������1������ max(x,y)=0����ô��x����0��
���ӱ���ʽ����ʽ����
��������һ��������һ��ĺ��� f(x,y,z)=(x+y)z����������һ���м����q��f=qz��q=x+y�����ǿ���ʹ����ʽ������f��x��y�ĵ�����
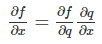
��y����Ҳ�����Ƶġ�
��������python��������f��x��y�ĵ�����ijһ�����ֵ��
# �����Ա�����ֵ
x = -2; y = 5; z = -4# ��ǰ����f
q = x + y # q becomes 3
f = q * z # f becomes -12# �ӡ�����ǰ��������
# ������ f = q * z
dfdz = q # ��Ϊdf/dz = q, ����f��z���ݶ��� 3
dfdq = z # ��Ϊdf/dq = z, ����f��q���ݶ��� -4
# Ȼ�� q = x + y
dfdx = 1.0 * dfdq # ��Ϊdq/dx = 1������ʹ����ʽ�������dfdx=-4
dfdy = 1.0 * dfdq # ��Ϊdq/dy = 1������ʹ����ʽ�������dfdy=-4
����Ҳ�����ü���ͼ����ʾ�ͼ��㣺
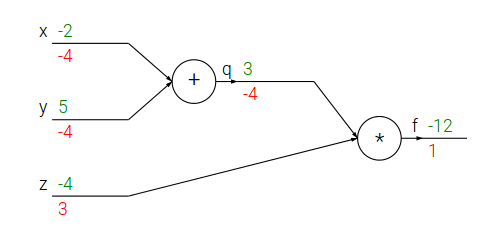
��ɫ��ֵ��feed forward�Ľ��������ɫ��ֵ��backprop�Ľ����
�����Ҿ���cs231n�γ̵����ͼû������blog��������ԭ������Ȼ����ʾ���������յ��ݶȣ�����û�б�ʾ��local gradient����������ử�������ļ�����̡�
�����㷨��ֱ������
��������Ѽ���ͼ��ÿһ���㿴��һ�����š�������һ��ģ�飩������˵һ������������һ�����루��������Ҳ��һ�������������������һ������˵���������㣬�����Ǹ������룬������������һ������ס�����һ�ּ�������������ÿһ�������ƫ����������˵��������������ġ��ֲ����ݶȣ�local gradient)��һ�����Ӽ���ͼ�������磩�ļ������Ⱦ���ǰ����㣬Ȼ������㣬������㹫ʽ���ܿ������ܸ��ӣ���������ڼ���ͼ����ʵ���Ǽ���local gradient���ԴӺ��洫������gradient��Ȼ���������
Sigmoidģ�������
���������ǿ�һ�������ӵ����ӣ�
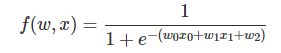
���������һ���Ƚϸ��ӵĸ��Ϻ��������ǹ������Ļ�������������4��������
�������ü���ͼ�������������̣�
���ͼ��4��gate���ӷ����˷���ָ���͵������ӷ��м�һ������������������ӣ��˷�Ҳ��һ����
��ͼ��ɫ��ֵ��ǰ�����Ľ��������ɫ��ֵ�Ƿ������Ľ����local graident��û�б�ʾ���������Կ�����������Щ��Ծ����������ֽ����ϸ�ķֽ������еIJ��裬����߸�����ͼ�Լ����ּ���һ�顣
��ͼ����ǰ�����Ĺ��̣��Ƚϼ�
�ڶ���ͼ�Ǽ���local gradient��������������ij˷��ͼӷ���local gradientҲ������ֵ��local gradient��ֵ���Ƿŵ�ͼ�Ľڵ����ˡ�
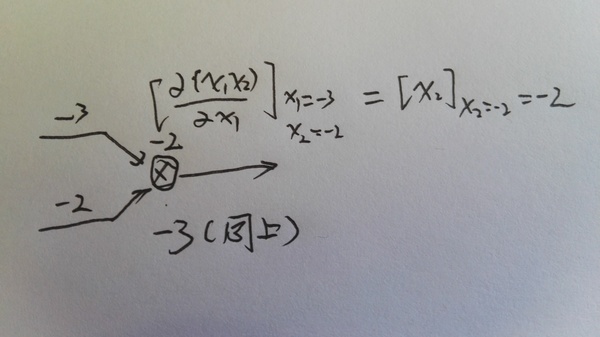
������ͼ�Ǿ������һ���˷���local gradient�Ĺ��̣���Ϊ��ͼ���ܿ����壬���Ե����Ŵ�����һ����
�������������ݶȣ��ǰ�local gradient����������һ����gradient�������������һ���ڵ�ֻ��һ�����������ж���Ļ����ݶ��Ǽ������ģ����Բο�1.4��
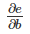
�������ǿ�����
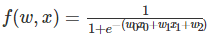
�ֽ��������ļӷ����˷���������ָ����������������Ҳ���Բ��ֽ���ôϸ��֮ǰ����Ҳѧϰ����sigmoid��������ô���ǿ��������ֽ⣺
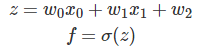
��(x)��(x) �ĵ�������֮ǰ�Ѿ��Ƶ���һ���ˣ���������һ�£�
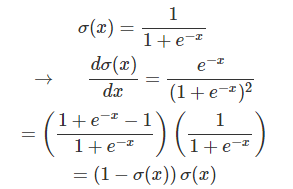
������ǿ��Ѻ���һ������gate��ѹ������һ��gate��
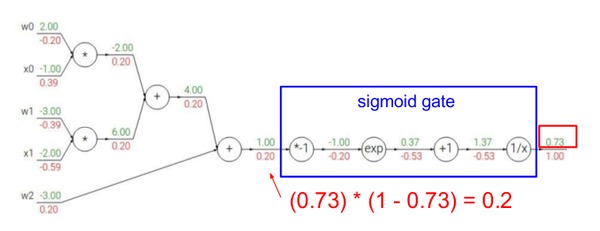
�������Ƚ�һ�£�֮ǰǰ����� ��(x)��(x) ��Ҫһ�γ˷���һ��exp��һ�μӷ������������������Ҫ�ֱ������4��gate�ĵ�����
��ѹ����ǰ�������һ���ģ����Ƿ��������ԡ����á�ǰ�����Ľ��
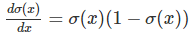
��ֻ��Ҫһ�μ�����һ�γ˷�����Ȼ�����������ǰ��Ľ�������������Ҫ���¼��� ��(x)��(x) ����ôѹ����ʵû��ʲô�ô�����ѹ����ԭ�����ڦҺ���������������ʽ����������Ĺؼ���������ѵ����ѵ�����ܾ�ȡ������Щϸ�ڡ�����������Լ���ʵ�ַ����㷨�����Ǿ���Ҫ�������������ԡ��������ʹ�ù��ߣ���ô�������ڹ��ߵ��Ż�ˮƽ�ˡ�
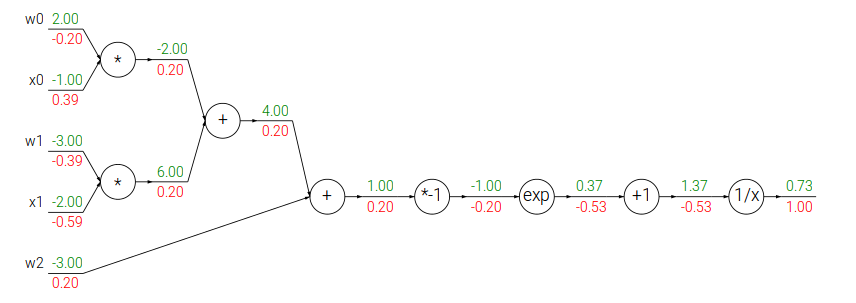
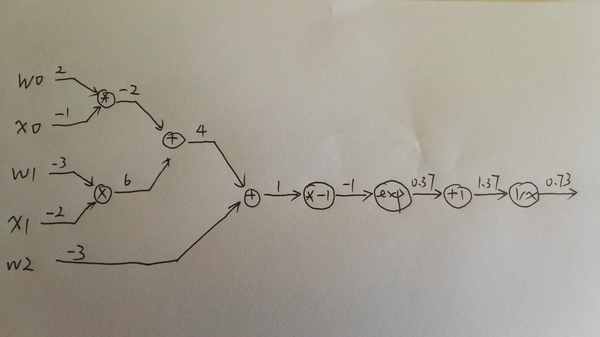
���������ô�����ʵ��һ�£�
w = [2,-3,-3] # assume some random weights and data
x = [-1, -2]# forward pass
dot = w[0]*x[0] + w[1]*x[1] + w[2]
f = 1.0 / (1 + math.exp(-dot)) # sigmoid function# backward pass through the neuron (backpropagation)
ddot = (1 - f) * f # gradient on dot variable, using the sigmoid gradient derivation
dx = [w[0] * ddot, w[1] * ddot] # backprop into x
dw = [x[0] * ddot, x[1] * ddot, 1.0 * ddot] # backprop into w
# we're done! we have the gradients on the inputs to the circuit
�������������һ��С���ɣ�������ν��staged backpropagation��˵���˾��Ǹ��м�ļ���ڵ���һ�����֡�����dot��Ϊ���ô����Ϥ���ּ��ɣ�������һ�����ӡ�
Staged computation��ϰ
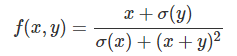
�����ô������������������x��y���ݶ���ijһ���ֵ
ǰ�����
x = 3 # example values
y = -4# forward pass
sigy = 1.0 / (1 + math.exp(-y)) # �����ϵ�sigmoid #(1)
num = x + sigy # ���� #(2)
sigx = 1.0 / (1 + math.exp(-x)) # ��ĸ�ϵ�sigmoid #(3)
xpy = x + y #(4)
xpysqr = xpy**2 #(5)
den = sigx + xpysqr # ��ĸ #(6)
invden = 1.0 / den #(7)
f = num * invden # done! #(8)�������
# backprop f = num * invden
dnum = invden # gradient on numerator #(8)
dinvden = num #(8)
# backprop invden = 1.0 / den
dden = (-1.0 / (den**2)) * dinvden #(7)
# backprop den = sigx + xpysqr
dsigx = (1) * dden #(6)
dxpysqr = (1) * dden #(6)
# backprop xpysqr = xpy**2
dxpy = (2 * xpy) * dxpysqr #(5)
# backprop xpy = x + y
dx = (1) * dxpy #(4)
dy = (1) * dxpy #(4)
# backprop sigx = 1.0 / (1 + math.exp(-x))
dx += ((1 - sigx) * sigx) * dsigx # Notice += !! See notes below #(3)
# backprop num = x + sigy
dx += (1) * dnum #(2)
dsigy = (1) * dnum #(2)
# backprop sigy = 1.0 / (1 + math.exp(-y))
dy += ((1 - sigy) * sigy) * dsigy #(1)
# done! phew��Ҫע������㣺1. ǰ��Ľ����Ҫ���������������ʱ��Ҫ�õġ�2. ���ij�������ж����ȥ�ıߣ���һ���ǵ��ڣ��ڶ��ξ���+=����Ϊ����Ҫ�Ѳ�ͬ��ȥ����ݶȼ�������
�������������з���������㣺
(8) f = num * invden
local gradient
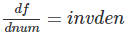
�����洫�������ݶ���1������ dnum=1?invden��ע��������������� df/dnum������Ϊdnum��ʡ����df����ΪĬ����������f�����б�����ƫ������
ͬ���� dinvden=num
(7) invden = 1.0 / den
local gradient�� (?1.0/(den??2)) ��Ȼ�������������dinvden
(6) den = sigx + xpysqr
�����������������sigx��xpysqr��������Ҫ��������local�ݶȣ�Ȼ�����dden
�ӷ���local�ݶ���1�����Ծ���(1)*dden
(5) xpysqr = xpy**2
local gradient��2*xpy���ٳ���dxpysqr
(4) xpy = x + y
����һ���ӷ���local gradient��1������dx��dy����dxpy��1
(3) sigx = 1.0 / (1 + math.exp(-x))
����sigmoid������local gradient�� (1-sigx)*sigx���ٳ���dsigx��
������Ҫע���������dx�ĵڶ��γ��֣�������+=����ʾ���Բ�ͬ·������������x���ݶ�ֵ
(2) num = x + sigy
���Ǹ��ܼļӷ���local gradient��1����Ҫע�����dx��+=������ͬ�ϡ�
(1) sigy = 1.0 / (1 + math.exp(-y))
�����sigmoid(y)��ǰ��(3)һ���ġ�
����ϸ�Ķ����淴������ÿһ�����룬ȷ���Լ�������֮���������Ķ���
�ݶȵľ�������
ǰ�涼�Ƕ�һ�������ļ��㣬��ʵ��ʵ��ʱ�þ�������һ�μ���һ��������ݶȻ���Ӹ�Ч����Ϊ������������������������������Կ���������Ծ����������ʽ�������������ǽ��ܾ���˷���ô���ݶȡ�
�������ǵö���ʲô�о���Ծ�����ݶȣ�
�Ҳ����˺ܶ����ϣ�Ҳû�ҵ������о���Ծ�����ݶȵĶ��壬�����λ����֪����������ң�лл��Ψһ�ȽϽӽ�����Andrew Ng�Ŀγ�cs294�ı���֪ʶ���ܵ�slides linalg��4.1�ڶ�����gradient of Matrix�����ھ���Ծ�����ݶ��һ���һ���²��ԵĽ��ͣ����ܻ������⡣
���Ƚ���graident of matrix
���� f:Rm��n��R��һ��������������һ��m��n��ʵ��ֵ���������һ��ʵ������ôf��A���ݶ������¶���ģ�

����������ܸ��ӣ���ʵ�ܼ����ǰ�f����һ��mn���Ա����ĺ�����������ǿ�����f����mn���Ա�����ƫ������Ȼ����������г�m*n�ľ�������ˡ�ΪʲôҪ���һ�ٰѱ����ijɾ�������ǵ�ƫ����Ҳ�ųɾ�����������֮ǰ���������weights�������Ǻ���Ȼ�Ķ��壬ͬʱ������Ҫ����loss��weights�����ÿһ��������ƫ������д����������ʽ���������ȽϷ��㡣
��ôʲô�Ǿ���Ծ�����ݶ��أ������ȿ�ʵ���������һ���������������ȫ���ӵ������磬������һ������������� D=WxD=Wx ���������������x���ɾ�������������Ҫ����loss��ijһ�� WijWij ��ƫ��������������֮ǰ�ļ���ͼ�� WijWij �ж��������ߣ���ô���ж��ٸ�Ҫ�ۼӵ��ݶȳ���local�ݶȡ�
����W��m��n�ľ���x��n��p�ľ�����D��m��p�ľ���
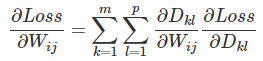
���ݾ���˷��Ķ���
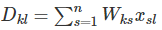
���ǿ��Լ��㣺
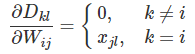
����ϸ����������һ������� k��i������s��ʲô��Wks��Wij����ͬһ�����������Ե�������0�����k=i����sWisxsl=xjl��Ҳ����͵��±�sȡj��ʱ����WijWij��
���

���������loss��һ��Wij��ƫ�������������д�ɾ�����ʽ���ǣ�
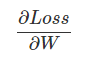
ǰ�������Ƶ����˶�Wij��ƫ�����ļ��㹫ʽ���������ǰ���д�ɾ���˷�����ʽ����֤��֤��������
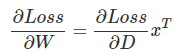
Ϊʲô����д����������ʽ�أ�

������Ƶ��ƺ��ܸ��ӣ���������ֻҪ�ܼ�ס���У��Ƿ�Ҳ�ܼ����Ѿ�����������1 1�ľ���Ҳ���DZ�����һ��ʵ������D=w x��������������װɣ���w����local gradient x��Ȼ����Եõ�dW=dD x��ͬ��dx=dD W��
���ǵȵȣ��ղ��Ǹ���ʽ�ﻹ�о����ת�ã������ô�ǣ�������һ��С���ɣ����Ǿ���˷�������������������������ǵĴ�С����ƥ�䣬����D=Wx��W��m n��x��n p��Ҳ���ǵڶ���������������ڵ�һ����������
���������Ѿ�֪��dW��dD�����ԡ�x�ˣ�dW�Ĵ�С��Wһ����m n����dD��Dһ����m p����x��n p����ôΪ�˵õ�һ��m n�ľ���Ψһ�İ취���� dD?xT
ͬ��dx��n p��dD��m p��W��m*n��Ψһ�ij˷����� WT?dD
��������python��������ʾ��numpy��dot���Ǿ���˷���������numpy.dot(A,B)��Ҳ����ֱ�ӵ���ndarray��dot��������A.dot(B)��
# forward pass
W = np.random.randn(5, 10)
X = np.random.randn(10, 3)
D = W.dot(X)# now suppose we had the gradient on D from above in the circuit
dD = np.random.randn(*D.shape) # same shape as D
dW = dD.dot(X.T) #.T gives the transpose of the matrix
dX = W.T.dot(dD)���ˣ���ϵ�����µĵ�5���ָ�һ���䡣�ڽ������������У����߽�Ϊ�����ϸ�������ڳ��������ѧϰ���/���ߵ�ʹ�÷�����ʹ���Զ�����ʵ�ֶ������������ݣ������ڴ���