����Ŀ¼
- ǰ��
- Overview
- Model Architecture
-
- REPRESENTING CODE AS AST PATHS
- Encoder
- ABLATION STUDY
ǰ��
�����е����ԭ����ζ�������ֽ����ṹ��˼��ܺã����ñ���ԭ����֪ʶ�Ҿ���ȷʵ���а��������Ǿ��巽�����������Ż���
�㷨��ַ��https://code2vec.org/
���ĵ�ַ��https://arxiv.org/abs/1808.01400
���ߵ�ַ����ʱֻ�����ݼ���https://urialon.cswp.cs.technion.ac.il/publications/
Overview
����ּ��encode source codeʱ���ñ�����Ե���ṹ���ó������(AST)�����·���ļ��ϱ�ʾ����Ƭ�Σ�����ÿ��·������LSTMsѹ���ɹ̶�����vector�������ڽ���ʱʹ��ע��������ѡ����ص�·��������ÿ��token���Ӷ�ʵ�ֶ˵��˵Ĵ���Ƭ�ε���Ȼ���Եķ��룬���ҶԶ��ֱ�����Զ����á�

�����еķ������ֳ�����һЩר��Ϊijһ������Ƶķ�����
Model Architecture
����encoder-decoder�ܹ���NMTģ����Ϊ�˽�ģ�������ʣ�
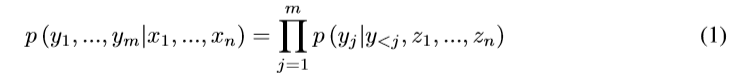
x��source sequence��z��a sequence of continuous representations��y��target sequence��
����ע������ģ�ͣ�decode�ε�ÿ��step t��������һ��context vector ct�����͵ķ�������һ��LSTM��ͨ��z��decoding state ht�������
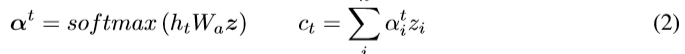
Ȼ��ct��ht����ƶ�target token yt��֮ǰ�Ĺ����ڼ���ct�������ht��ϵķ�ʽ������ͬ��
һ�����ķ����ǽ�ct��ht��ΪMLP�����룬Ȼ����softmax�ƶ���һ��token�ĸ��ʣ�
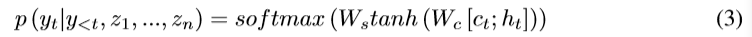

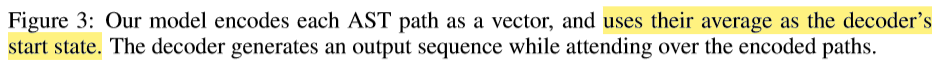
����ʹ��NMT����encoder-decoder�ܹ�����һ����־�Ե���������encoder������������Ϊ��ƽ��token����(a ?at sequence of tokens)��ȡ��������encoderΪAST�е�ÿ��·���ֱ�һ��vector��ʾ��decoder�㴦����Щencoded AST paths��
REPRESENTING CODE AS AST PATHS
AST��Ҷ�ڵ������ʶ���ͱ���������Ҷ�ڵ���������нṹ�����Ƽ�������ѭ������������������ʽ��

���Ľ��ɶ�Ҷ�ڵ�֮���·����������·�������нڵ��sequence��Ȼ������Щ����Ҷ�ڵ��·����ʾ����Ƭ�α�����������Ƭ�ε���token��sequence�����Ե����ַ������Ƶ��·����
����ͼ���еĺ�ɫ·��������DoStmt��ForStmt�IJ�ͬ�����Ե�Ҷ�ڵ�������IJ�ͬ��������һ�µģ��������������������ϵ������ԡ�Ҳ����ΪAST normalize����������ϵ�variance��ʹ��encoder�����û�м���������ʱ���ָ��á�
��Ϊ������·������ϵģ����Լ�ʹ·������ͬ��encoderҲ��generalize����������������·���������������������Բ���k����������ÿ��ѵ��iteration�������²���k���µ�������bias��������k����200������300�ƺ���������������100����СС�Ķ�
������η��Ų��ô�ֱ����ͼ��

�±��¼���ȣ���������·����
Encoder
�������ǵ�source sequence���Ǵ����һ��·����xi��һ��·����

������·����ÿ���ڵ���ѧ����embedding matrix Enodes��ʾ��ʹ��˫��LSTM encodeÿ��·��������sequence��������״̬��Ϊ���Եı�ʾ��
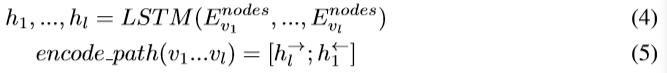
��ͷ���Ҵ���������������״̬����ĩ��h����֮��Ȼ��
Ҷ�ڵ��Ǵ����е�token�����Ľ�token�ָ�Ϊsubtoken������һ��tokenֵΪArrayList�������ΪArray��List���շ�ʽ�����������ı���ϰ���ṩ����ȷ�ķָ
������֮ǰ���ڵ��encode��ʹ��ѧ����embedding matrix Esubtokens��ʾÿ��subtoken��Ȼ����ʹ���֮ǰ��token��
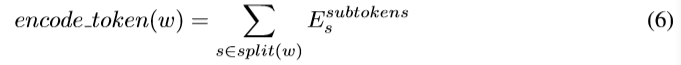
LSTM decoder��ÿ��step����Ҳ���ƶ�subtoken���������ɺ�����ʱ��
�ڱ�ʾ����·��ʱ�����ǽ�·���ı�ʾ��ÿ��Ҷ�ڵ�ı�ʾƴ����������Ӧ��һ��ȫ���Ӳ㣺
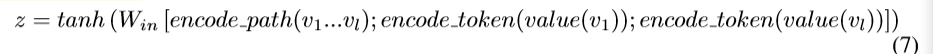
value�ʹ���(6)�е�w

decoder����ʼ״̬��z��ƽ��ֵ��

����·����˳��û�п��ǣ�ÿ��·�� xi ���Ƿֱ�encode�õ�zi��Ȼ���ϵ�representationͨ��mean pooling��ʼ��decoder��״̬������Դ��ͱ���ʾΪһ������·���ļ��ϡ�
ע����������seq2seq���ơ�
�Ż�Ŀ���ǽ�����
����ʵ�����ÿ��Կ����ġ�ʵ������Ȼ�ܺ��ˡ�
ABLATION STUDY

