序列生成架构
1.decoder模型:
1.1 模型架构图:
1.2 数据流:
数据形式:使用历史token序列预测当前时刻 t 下一个时刻 t+1 时刻。
训练数据形式:假设有一段token序列X,那么input_sequence = X[:-1],lable_sequence = X[1:],原则就是使用当前时刻的历史hidden state info和当前token作为模型(模型可是RNN或transformer)的输入,预测下一时刻的输出token,如图中一个子模块。输入每个token位置feature应该都保持一致,不管是形状、特征变量都应该一致。
预测数据形式:初始token序列输入网络获取第一次预测token和hidden state info,之后第一次预测token和hidden state info作为子网络的输入,预测下一个token,依次循环直到预测结束。
2.encoder-decoder模型
2.1 模型架构图
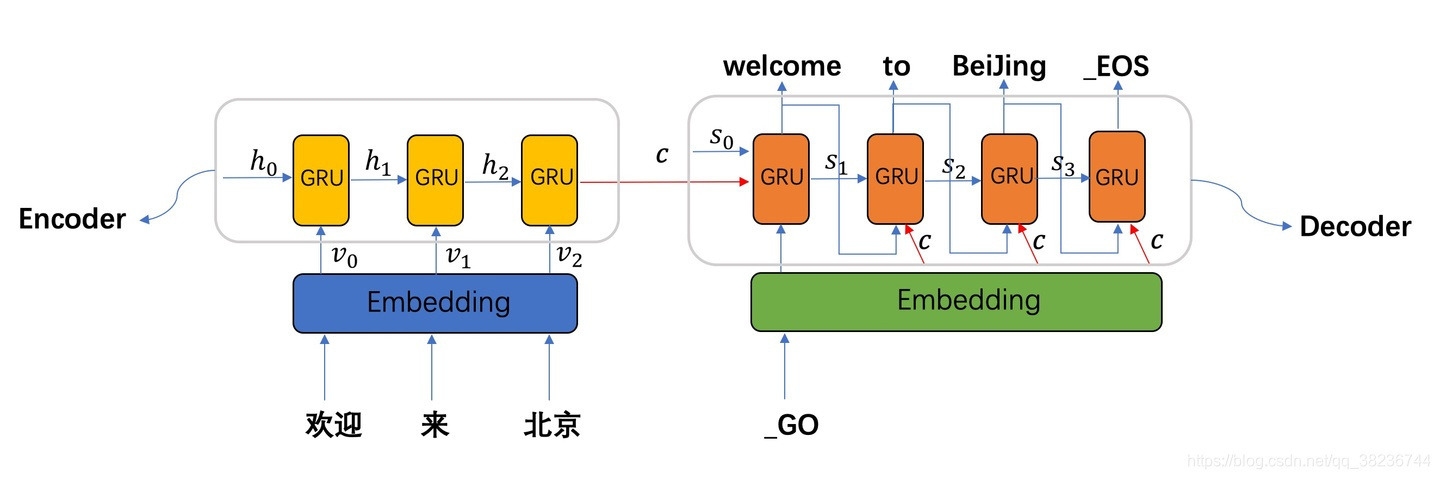
2.2 数据流
编码端:单个token输入数据保持一致,即每个位置输入数据shape、特征数量都保持一致。
解码端:单个token输入数据也保持一致,与单一decoder框架一样。但是编码端与解码端输入不必保持一致,编码端输入与解码端的输入是相互独立的。这里有个优势就是编码时候可以引入多维特征向量,而解码时候只做单一向量的预测,这个在decoder框架下是不能实现的。因为decoder输入与输出实际是要保持一致的,还有就是在做预测时候很难获取其他依赖的特征,因为未来谁知道其他特征的值呢?
预测数据形式:编码端就是已知的一段历史数据,单个时间不输入数据可以为多特征,不必与解码端输入特征数一致。解码端第一个输入一般包含一个隐向量与起始向量,隐向量为编码端最后的输出,初始向量一般就是固定的某个特征,之后操作就与上面的decoder架构一样,构建训练数据的方式也一样。
优点:编码端可以收集更多特征信息喂给模型,可以让模型学习到多特征信息,这个是单纯decoder(自回归)生成模型无法做到的。decoder端输入可以是多特征也可以是单特征,主要取决于你的任务,如果你要做多个特征值的预测,那么你输入就是多特征,如果仅做单特征的预测,那么输入就是单特征,必须要保持输入和输出一直,因为上一个时刻输出是下一时刻输入。