这是一篇中国电子科技大学的文本检测文章
引言
基于深度学习的场景文本检测方法在过去几年取得了显着成效。 然而,由于自然场景的高度多样性和复杂性,当应用于在现实世界环境中捕获的图像时,目前最先进的文本检测方法仍可能产生大量假阳性结果。 为了解决这个问题,作者受到Mask R-CNN的启发,文中提出了一种有效的场景文本检测模型,该模型基于特征金字塔网络(FPN)和实例分割。 作者提出了一个监督金字塔上下文网络(SPCNET)来精确定位文本区域,同时抑制假阳性。
受益于语义信息的指导和共享FPN,SPCNET在引入边际额外计算的同时获得了显着增强的性能。 标准数据集上的实验表明,我们的SPCNET明显优于最先进的方法。 具体而言,ICDAR2013上达到92.1%,ICDAR2015为87.2%,ICDAR2017 MLT为74.1%,总文本上达到82.9%。
内容
为了检测各种形式的文本,通常采用基于实例分割的方法。 目前实例分割方法,例如Mask R-CNN(He等人,2017a),通常被开发为多任务学习问题:(1)将前景对象提议与背景区分开,并为它们分配适当的类标签。 (2)对每个前景方案进行回归和分割。
然而,简单地将Mask-RCNN转移到文本检测场景容易引起一些问题,原因如下:(1)缺乏上下文信息线索。自然场景中的假阳性往往与周围场景密切相关。例如,餐具经常出现在桌子上,并且围栏通常分批出现。然而,Mask R-CNN在一个感兴趣的区域中区分对象,缺少全局语义信息指导。因此,在没有上下文信息线索帮助的情况下,它往往会导致一些具有相似纹理信息的对象的分类错误。 (2)分类评分不准确。在处理倾斜文本时,Mask R-CNN的分类分数很容易不准确。因为对于倾斜文本,Mask R-CNN基于水平提议粗略地给出分类分数,而背景占据很大比例。因此,当面对倾斜文本时,Mask R-CNN的分类得分往往较低。
本文在Mask R-CNN 的启发下,提出了一种基于语义信息的形状稳健的文本检测器,利用生成对象的形状分支的输出来定位文本区域。 因此可以灵活地检测任意形状的文本。
为了解决FP上缺乏上下文信息线索和分类评分不准确的问题,作者提出了一个文本上下模块和重新评分机制(基于mask R-CNN)不了解的可以戳https://blog.csdn.net/WZZ18191171661/article/details/79453780 :
对于上下文信息,用语义分割分支来辅助指导检测分支捕获上下文信息。通过对全局语义的特征的补偿,网络更好的区分了FPs。
在评分机制上,队分割图上的激活值和分类评分进行补偿,得到一个融合的分数,在处理倾斜的文本时,虽然分数相对较低,但对分割图的响应较强,这也使得准确的融合得分较高重评分机制可以进一步减少FP的数量。这是因为FP在分割图上的响应很弱,导致融合分数较低。因此,分数较低的分数在推理过程中更容易被过滤掉。重新评分机制的可视化结果如图1.

Label Generation
文本实例的基本事实在图3中举例说明。与常见的实例分割数据集不同,不提供像素级文本/非文本注释。 将多边形中的像素视为文本,将多边形外的像素视为非文本,然后得到文本区域的实例。 多边形的最小边界水平矩形将被视为边界框。以与实例生成相同的方式生成全局二进制映射。

Mask R-CNN architecture
文章提出的方法的总体结构如图2所示。网络由五部分组成:特征金字塔网络(FPN),区域提议网络(RPN),R-CNN分支,掩模预测分支和全局文本分割预测分支。 特征金字塔网络(FPN)是一种广泛应用于当前主流检测模型的特征融合结构.FPN采用自上而下的横向连接架构,从单一尺度输入构建网内特征金字塔。 区域提议网络(RPN)生成可能包含对象作为提议的边界框。 通过Roi-Align,所有提案的大小调整为R-CNN分支的7×7和掩模预测分支的14×14。 全局文本分段分支作用于FPN的每个阶段以生成文本的语义分割图。

Text Context Module
抑制假阳性对于一般物体检测和文本检测来说是一个具有挑战性的问题。 在自然场景中,一些常规对象,例如光盘,栅栏等,很容易被检测网络检测为文本。 掩码R-CNN使用感兴趣区域(ROI)来分类提议是文本还是背景。 然而,使用仅从一个感兴趣区域提取的特征来执行文本区域分类。 由于自然场景中的误报通常不会出现意外,例如板块更有可能出现在桌面上,引入上下文信息有助于网络提取更多的辨别功能并准确地对提案进行分类。 此文的文本上下文模块(TCM)由两个子模块组成:金字塔注意模块(PAM)和金字塔融合模块(PFM)。 要素图被输入TCM,TCM将文本分割作为输出。
Pyramid Attention Module
金字塔注意模块和SSTD相似,还在FPN从stage2到stage5之后添加了一个全局文本分段分支。 它为每个FPN层生成像素级文本/非文本区域的显着图。 注意模块和融合模块共享一个分支,命名为文本上下文模块,包括两个3×3卷积层和一个1×1卷积层。 输出显着性图包括两个通道,即文本/非文本图。 增强显着性图并使用它来激活要素图上的文本区域。具体来说,以stage2为例,给出512×512的输入样本,特征映射S2∈R128×128×256。显著图的生成如下:

其中Text Context模块生成带有2个通道的显着图。 然后在通道方面softmax之后,我们获得文本显着性图。 通过指数激活,增强图显着增强,即文本/非文本区域中的响应间隙变大。 显着性图将作用于特征图,如下所示:

显着性映射广播到与S2相同的256通道,“![]() ”表示两个映射S2和显着性映射的逐像素乘法*。
”表示两个映射S2和显着性映射的逐像素乘法*。
Pyramid Fusion Module
金字塔融合模块。 PFM将检测特征与深度监督语义特征相结合,使网络更具辨别力,区分文本和非文本。具体而言,语义分割从单个像素的角度检查文本,并通过组合周围像素的信息来确定文本区域, 检测通过ROI对文本区域进行分类。 两个分支之间存在天然的互补关系。在文本上下文模块的第一个3×3卷积层之后,得到全局文本分割的特征映射(GTF)。 这些特征捕获了诸如背景和文本的语义分割等补充信息。将其引入原始特征图使得Mask R-CNN在分类任务上表现更强。 具体细节如下:

其中Conv3×3是文本上下文模块中的第一个Conv层,GTF表示全局文本特征。 然后“+”表示元素加法运算。
Re-Score Mechanism
对于标准Mask R-CNN推理处理,预先确定的top-K(例如,1000)边界框按分类置信度排序,然后在标准NMS处理之后,最多到顶部M(例如,300)边界框具有最高 保留分类信心。 这些边界框被馈送到Mask R-CNN作为生成预测文本实例映射的提议。 此方法将一个水平边界框的分类置信度视为分数,然后人为设置阈值以过滤掉背景框。 但是,此方法将过滤掉一些具有低分数的真正积极因素,因为如果水平边界框包含标题文本实例,则它还伴随着大量背景信息。 同时,将保留一些信心相对较高的FP我们为每个文本实例重新分配分数。 可视化图如图4所示。文本实例的融合得分由两部分组成:分类得分(CS)和实例得分(IS)。 形式上,给定预测的2级得分![]() 和
和![]() 的第i个提议的融合得分是通过以下softmax函数计算的:
的第i个提议的融合得分是通过以下softmax函数计算的:
其中CS由Mask R-CNN分类分支直接获得,IS是全局文本分割图上文本实例的激活值。 具体来说,对于每个文本实例,它被投影到文本分割图上,包含![]() ,并计算文本实例区域中pi的均值:
,并计算文本实例区域中pi的均值:
其中Pi是文本分割图上第i个文本实例的像素值集。 融合得分将分类得分与实例得分相结合,这可以有效地降低FP置信度,因为FP实例往往比分割图上的文本具有更弱的响应。

Loss Function Design
与Mask R-CNN类似,网络包括多任务。在Mask R-CNN的loss函数设计之后,在此基础上添加了全局文本分段loss。loss表达式如下:![]()
其中Lrpn,Lcls,Lbox和Lmask是Mask R-CNN的标准损耗。 Lgts用于优化全局文本分段,定义如下:
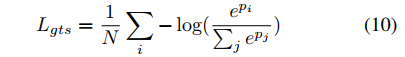 Lgts是Softmax损失,其中p是网络的输出预测。
Lgts是Softmax损失,其中p是网络的输出预测。
多任务学习是从同一输入中学习多个互补任务的有用表示的过程,并且已经发现它可以改善两个任务的性能。 该方法使网络能够通过端到端联合训练来学习文本检测和全局文本分割,从而允许来自两个任务的梯度影响共享特征图。
在ICDAR2017上的效果
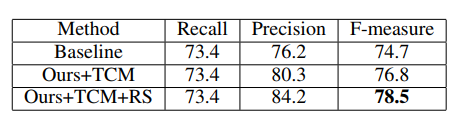
文本上下文模块在保持召回相同的同时实现了4.1%的精度提高,重新评分机制可以进一步提高基于TCM的3.9%的精确度

评估模型检测Total-Text数据集上的弯曲文本的能力,使用MLT预训练权重初始化模型并对Total-Text进行40个时期的微调。 所有测试设置与ICDAR2015和ICDAR2013相同。详细结果如表5所示,SegLink和EAST的结果是从TextSnake引用的。

作者在SynthText上预先建立了一个时期的网络,然后在MLT 9000上进行微调,并对40个时期的val图像进行微调。 单尺度为848(短边)达到70.0%的测量,超过3%的现有技术方法。 由于MLT上有许多小词,应用了scale∈[720,1920]的简单多尺度测试方法。 通过合并两个量表的结果,Fmeasure为74.1%,优于所有竞争方法至少1.7%。 结果如表2所示。