“WHY”类型问答系统的研究
文章目录
- “WHY”类型问答系统的研究
- 0. 摘要
- 1. 介绍
- 2. 数字助手 VS 问答系统
- 3. 重要的定义
- 4. QA系统的通用框架
- 5. WHY型问答系统的技术模块
-
- 5.1 数据准备
- 5.2 问题分析和处理模块
-
- 5.2.1 问题分类
- 5.2.2 问题重构
- 5.3 文档检索
- 5.4 候选答案提取
-
- 5.4.1 词法-句法分析
- 5.4.2 因果关系
- 5.4.3 语义和上下文分析
- 5.5 答案重排序
-
- 5.5.1 词袋模型有关的特征
- 5.5.2 形态句法分析
- 5.5.3 语义词类
- 5.5.4 情感分析
- 5.5.5 内容相似特性
- 5.5.6 因果关系特征
- 5.5.7 Metzler-Kanungo特征
- 5.5.8 CNN & CTK 方法
- 5.5.9 文本蕴涵
- 5.5.10 词汇语义语言模型
- 6. 性能指标
-
- 6.1 Mean Reciprocal Rank(MRR)
- 6.2 Precision
- 6.3 Precision at n (P@n)
- 6.4 Mean Average Precision(MAP)
- 6.5 Recall
- 6.6 Recall @k
- 6.7 F-score
- 结论
- 6.
0. 摘要
谷歌、Yahoo、百度等搜索引擎会根据用户提问的需要,以一组相关网页的形式提供搜索结果。对于一个查询,问题回答系统通过提供一个最相关的答案,节省了用户进一步查找 的时间。据我们所知,关于 “WHY” 类型的问题的主要研究开始于2000年早期,我们对 “WHY” 类型问题的研究可以帮助探索发现事实和分析的新途径。本文对 “WHY” 式问答系统进行了综述,详细介绍了该系统的体系结构、过程,并提出了进一步的研究方向。
1. 介绍
- 问题类型:who, when, what, where, how, 和 why.
- 其中,who, when, what, where 是事实性问题
2. 数字助手 VS 问答系统
Google Assistant、Alexa、Siri和Cortana是当今市场上常见的数字助手。它们可以回答任何问题,执行给它的任何命令。它们被设计为提供播放歌曲/视频/电影、告知当前天气或预测天气预报、设置闹钟、拨打和接听电话,甚至搜索Web以回答一些琐碎问题的功能。它们不仅可以处理文本数据,还可以处理音频、图像和视频。问答系统是一个广泛的领域,其著名的应用之一就是数字助手。他们利用自然语言处理和机器学习来理解自然语言中的问题,并利用机器学习算法来解析它以识别有趣的有意义的模式。信息处理有两个阶段 (1) 训练(预处理)阶段;(2) 处理和决策阶段。
训练阶段侧重于从给定的系统查询中 识别命名实体和意图。举个例子,在命令 “Alexa, please have a tea” 中, “tea” 是一个实体 (名字,日期,地点,属性) ,“have” 是一个意图 (用户发出的动作)。
处理和决策阶段包括许多文本处理阶段,如词干分析和引理分析、TF-IDF、指代消解、词性(POS)标注、依赖解析、命名实体/意图识别等等。
它们还可以使用从知识图谱中提取的知识来解决特定领域的问题。利用语义相似度匹配将用户问题分解为一个向量空间。语义(Semantics) 找出问题中包含的词的意义和解释。语义分析中常用的一种方法是词义消歧,即根据上下文赋予词义。数字助理面临的挑战之一是上下文和个性化,即基于用户提问的设备、地点和提问的时间等回答问题。除了现有的挑战外,本文还试图深入了解问答系统的内在工作原理,即只有 “WHY” 型的问答系统才能准确地回答问题。
3. 重要的定义
自然语言处理
因果关系
机器学习
分类
聚类
神经网络
假设
武断的
数据挖掘
语料库 VS 数据集
标注
词法分析
语法分析
语义分析
语用分析
话语分析
命名实体标注
文本蕴涵:是指两个文本片段有指向关系
语义角色标注:是一种浅层的语义分析技术,标注句子中某些短语为给定谓词的论元 (语义角色) ,如施事、受事、时间和地点等
语义消歧
马尔科夫模型
统计模型
RNN
CNN
特征工程
意译
语义关系(同义词、反义词、上位词、下位词、同音异义词、一词多义、部分整体关系)
统计翻译
关系:兴奋性、抑制性、中性
支持向量机
朴素贝叶斯
预测
回归
4. QA系统的通用框架

五个主要模块:问题分析与处理、文档检索、答案提取、答案重排序、答案验证
- 问题分析处理模块:问题分析模块对输入问题进行处理,查找其焦点、类型和预期答案类型。它对问题进行词法、句法和语义分析并进行分类,其准确性有助于检索正确答案。
- 词法分析: 词法分析涉及到标记化(tokenizing)、词性标注、关键词提取、去停用词和命名实体标注等技术。其目的是将问题分解为称为 token 的有意义的最小术语,并识别每个术语的角色。
- 句法分析:句法分析旨在确定问题中术语的句法形式或排列顺序。这一阶段最常见的形式是依赖分析,即根据依赖语法中描述的规则找出问题中包含的两个词汇之间的关系。(通过表示短语和句子中使用的词语之间的依赖关系来构建短语和句子的结构)。依赖解析器根据手写的规则生成问题的解析树,从而实现该过程的自动化。
- 语义分析:语义分析阶段试图确定问题中词语的意义。它使用 “语义角色标”,给问题中的单词或短语加上语义角色,如主体、目标或结果。它利用三种资源开发的知识库:FrameNet为谓词分配语义角色;PropBank是一个由带注释的动词命题组成的语料库;VerbNet 为定义在 PropBank 的动词类型提供类别。因此,它试图得出用户的推理和需求,从而使系统能够对一个问题提取适当的答案。
- 问题分类:问题分析阶段根据句法和语义信息对问题进行分类,确定预期答案类型,即问题分类的结果直接影响QAS的性能。那么根据 [Mishra; et. al; 2016],QAS根据以下因素分类,如:
(1)应用领域:通用和受限领域
(2)问题类型:事实问题、列举问题、假设问题、因果问题和确认问题
(3)对问题的分析类型:形态、句法、语义、语用和语篇
(4)数据源的类型:结构化、半结构化、非结构化
(5)检索模型中使用的匹配函数的类型:集合理论模型、代数模型、概率模型、基于特征的模型和基于概念图的模型
(6)数据源的特征:规模大小、语言、不均匀性、题材和媒质
(7)QAS中的技术:数据挖掘、信息检索、自然语言理解、知识检索与发现
(8)答案形式:提取并生成答案
- 文档检索:在问题分类模块之后,问题分析模块旨在通过相关性反馈和查询优化等技术重新构建问题,以展现用户的适当需求。重构的问题被输入到搜索引擎,搜索引擎返回一个文档列表。这些文档根据它们与查询的相关性进行排序,相关性是由各种指标组成的,如关键词数量、命中率、用户历史记录等。文章检索模块使用不同的段落分割算法将排名靠前的文档分成小的段落,如段落和句子。这些文章是根据不同的特征检索的,如命名实体的数量,关键字,关键字的顺序,以及文章和答案类型确定的文章。
- 答案提取:答案抽取模块从检索到的段落中提取出与问题分析模块返回的答案类型相匹配的相关候选答案。在文章检索中上述描述的一些特征也会影响候选答案,像:
(1)包含与正确答案类型匹配的短语
(2)与问题和候选答案匹配的关键词个数
(3)候选答案的新奇性
(4)问题和候选答案中单词的顺序和排列
(5)候选答案中标点符号的位置 - **答案重排序:**答案重排序模块重新排列提取的候选答案。得分最高的最合适的答案将作为一个合适的答案输出,返还给用户。
5. WHY型问答系统的技术模块
本节讨论在QA系统中解决WHY型问题的不同模块中已存在以及提出的技术。
5.1 数据准备
可用的数据集包括:Yahoo! Answers、Answers.com、Quora、WikiAnswers、AskMe等等
其中,WHY型问题可从上述数据集中提取出来。
挑战与方向:
- 挑战:在社交QA网站上提出的问题在语法上是不正确的/没有正确的意义
解决:问题的自动预处理模块需要扫描他们的语法错误/拼写/术语的顺序 - 挑战:为WHY型 问题 收集/准备数据集很麻烦
解决:需要使用爬虫爬取网站和收集WHY类型的问题 - 挑战:WHY型问题不限于那些以“WHY”开头的问题
解决:需要一个工具来识别包含因果因素的问题,而不仅仅是那些以“为什么”开头的问题
5.2 问题分析和处理模块
问题分析模块的目的是提取重要的关键词,了解用户的需求,从而帮助确定解决问题的方法。这一过程包括词法分析、语法分析和语义分类。在问题分析阶段,存在着不同的技术,如标记(tokenization)、消歧、词性标注、实体标注、逻辑形式、依存句法分析(dependency parsing)、语义角色标注和指代消解(co-reference resolution)等。该阶段通过句法依赖分析器对问题进行解析,推导出问题的结构,并利用问题中所包含的语义信息形成语义模式。理解问题后,输入到问题分类模块,该模块根据关键词对问题进行分类,确定期望答案类型。
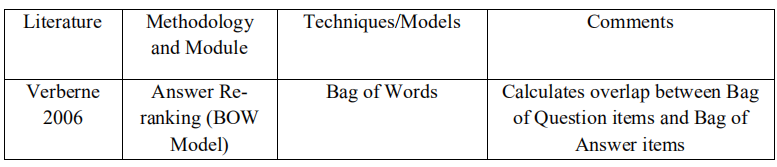
Suzan Verberne在2006年实现了用于关键词提取的语法分析。她应用命名实体识别技术识别命名实体,通过浅层解析提取名词短语。例如,“Who is the Prime Minister of India”这个问题可以转换为查询“Prime Minister India”,去掉了“Who, is, the, of”等停用词。但是这个过程有一定的缺点,由关键字组成的查询不是最适合检索文档的。在这种情况下,需要根据用户的需要添加相关术语来重新表述查询。这对回答 WHY 类型的问题有很大的影响,因为通过匹配关键字提取的文档可能并不总是满足用户的需要,因为回答 WHY 型问题需要对事实发生的原因进行推理,而不仅仅是检索问题中询问的事实信息。例如,一个WHY 型问题“Why do people cry?”,检索到的文档可能包含与 “crying” 现象描述及其过程有关的信息。用户想要找到解释哭泣行为背后原因的答案的具体需求,可以通过检查包含这些信息的文件来找到。
5.2.1 问题分类
问题分类是问题分析模块的第二阶段,它利用抽取的重要关键词对问题进行语法或语义上的分类,以探究问题的期望答案类型。许多研究基于不同的因素对事实型QA 提出了各种类型的分类方法,而在非事实QA 方面所做的工作有限。提出 WHY 型问题分类标准的部分研究是 [Holth 2013],他对 WHY 型问题进行了行为分析。作者提出了不同的类别,如:
- Immediate Antecedent(直接前因),旨在了解时间的直接前因
例如:“Why did the window pane break?” - Disposition or Summary Label,询问事件发生的原因
例如:“Why did the window pane break when hit by ball?” - Internal Mediating Mechanism,包括在神经学中提出的关于事件内部运作背后的原因 WHY 型问题
- External Historical Variables,询问事件在外部变量影响下的行为。
[Ferret 2002] 使用浅解析器解析问题并将手写规则应用到结果解析树以找出问题的语法类别; [Verberne 2006] 利用 Ferret 的方法从句法上把 WHY 型问题分类为:
action questions, process questions, intensive complementation, monotransitive have questions, existential there, 和 declarative layer questions;根据 Moldovan et. al.,所有 WHY 型问题都有 reason 作为答案类型。然而,Suzan Verberne 推测 有必要将答案类型(reason)分成不同的子类型,以选择合适的句子答案。因此,她基于Quirk [2010]给出的状语从句提出 reason的子类别:
cause, motivation, circumstance, purpose。
基于问题分类对提高问答系统性能的重要性,我们尝试扩展研究,提出一种仅对 why 型问题进行分类的方法。在分析了大约2000个“WHY”型问题的数据集之后,提出了一种分类方法。该方法是通过分析词性标签、连词和问题中使用的其他关键术语而提出的。提出了以下四个类别,即扩展了WHY 型问题的分类研究 [Manvi; 2017, 2018]:
- Informational Why-questions,要求在回答中解释事实的
- Historical Why-questions,为过去发生的事件提供正当的理由
- Contextual/Situational Why-questions,说明在特定时间发生的事件背后的原因
- Opinionated Why-questions,根据个人的知识和经验,对个人或实体进行解释
此外,根据第5.4.1节中讨论的问题中包含的词汇,我们已经确定了对应于给定问题的预期答案类型。我们还计划研究包含在不同答案类型中的模式,以帮助找到与“WHY ”问题相关的和高度排序的答案。
除了 why-question 分析的句法方法,Karyawati, 2015 [Karyawati;2015]采用带有语义实体的词袋模型来表示捕获用户需求的查询。研究人员采用词性标注和类型依赖分析相结合的方法,构造了描述术语之间关系的 why-question 模式。采用动词分类和领域本体 确定期望答案类型。该方法具有良好的性能指标,但其缺点是手工构造词汇句法模式太耗时,并且生成的模式数量有限,不能涵盖所有的实际问题模式。此外,本研究假设 why-question 必须是正确的英语语法,并针对特定的领域,即文本检索领域。由于上述方法有了显著的改进,可以进一步改进其他基线方法,可以通过使用机器学习技术自动生成词汇句法模式,通过构建语义索引扩展领域本体来改进。
(垃圾文章,词不达意)
问题分类和解决方案的挑战
- 挑战:如果词汇模式是人工生成的,它不能涵盖一系列的问题,即有限的模式
解决:使用机器学习技术自动生成具有不同特征的模式 - 挑战:需要确定用户焦点和预期答案类型
解决:为了提高性能,需要将语义特征与领域知识结合使用 - 挑战:某些问题的分类不明确
解决:对需要的特征进行适当的加权,以解决模棱两可的问题,并为给定的 Why-question 指定一个类别
5.2.2 问题重构
在对问题进行分析后,需要根据问题分类所定义的类别来重新构建问题。这需要从查询中描述合适的用户需求,从而帮助为查询提取适当的文档。问题重构是问题处理模块的基础,该模块通过包含重要的术语来重构问题,以增强对用户需求的理解。根据 [Corpineto; 2012],利用语法关系、语义关系和使用知识(解释)等多种查询重构技术来选择重要的查询术语。原始的问题(Q)是用答案文档中包含的术语进行扩展的,以避免在问题和候选回答之间出现大量的词汇不匹配问题。各种各样的方法被使用,比如:
(1)使用WordNet中的语义关系扩展查询; (Miller; 1995) 术语是从描述问题短语与其答案文档之间的词汇关系的WordNet中计算出来的。
(2)查询是通过与用户交互来优化的,在交互中用户有机会选择合适的术语来满足他/她的需求. (M. Harvey; 2015)
(3)该系统向用户推荐相关查询,用户可以选择扩展的术语。这通常在Google Assistant中看到,其中谷歌搜索引擎帮助用户提供相关查询列表 (Harvey; 2015)
(4)要附加到查询中的术语是从查询扩展术语空间(QETS)中选择的,该查询扩展术语空间是通过查找它们的外链页面之间的接近度来选择的。 Ganesh et. al. in 2009探索了用于查询扩展的维基百科页面的内容和结构。术语的语义相关度是接近度和outlink 得分的家和;其中一个术语的接近度得分是由频率以及问题中一个关键词在维基百科中所有相关句子(S)的最小距离 加权得到的。 outlink得分利用维基百科的链接结构和类别信息。
因此,词与词之间的句法和语义关系对问题的重构具有重要意义。通过引用用户以前的问题日志和使用以前问题中使用的术语扩展查询,可以提高该模块的准确性。此模块的结果也会受到QA领域的影响。要附加的术语取决于可用且准确的领域知识。 有时,可以使用专家知识来重新构造查询,以便将问题定位为准确的答案。
问题重构挑战和解决方法
- 挑战:从问题中理解准确的用户需求
解决:从语义关系和用户日志中识别出的与用户需要相对应的词汇来改写或重新表述的问题 - 挑战:问题无法定位或标识域
解决:重新构造问题所需的领域和专家知识,以帮助引导问题进行适当的文章检索
5.3 文档检索
“文档检索” 标识出可能包含问题答案的文档。这个模块返回包含与查询相关的内容的相关文档。文档从以下几方面进行深入分析:
(1) pattern matching:匹配文档中所使用的短语
(2)syntactic parsing:利用解析树或依赖关系图来描述短语的正确句法位置
(3)synonym and semantic parsing:使用命名实体识别器将同义词和语义类型分配给短语
它根据用户的查询匹配文档,并通过使用PageRank算法计算出的相关性评分对匹配结果进行排序。检索引擎要么返回一个无序的相关文档列表,要么生成一个排序的文档列表,这些文档根据包含答案的可能性进行评分(Monz C. 2003)。
文章检索(Passage Retrieval)是文档检索(Document Retrieval)的一个分支,其目的是确定检索到的文档中相关段落/短文的位置。每个文档都要仔细检查一个有最大可能包含答案的特定段落。这些段落是通过识别查询和文章中重叠的单词来选择的。这项技术是由Suzan Verberne [Verberne; 2006]在她的研究中使用。她利用词袋模型将查询词与候选答案匹配,从而检索文档。检索和匹配来自查询和文档的n个字符。使用 tf?idftf-idftf?idf 评分对它们进行加权,其中 tftftf 是查询和相关段落中术语实例的数量,idfidfidf 是逆文档频率,用其中的术语实例对每个文档进行加权。模型应用于Why-QA,面对各种缺点,短问题只包含一个语义丰富内容的词,在检索到的文档集中,正确的答案文档可能会列在更低的位置,因为缺乏文档上下文理解,多词短语被看做独立的术语用于检索文档。
该模型无法提供最佳结果,因为Why-QA要求理解问题中的术语以提取适当的文档,而不是将术语与文档匹配。由于该模型不考虑术语的顺序,因此它忽略了上下文,进而忽略了查询和文档中单词的含义(语义),而理想的WhyQA当正确理解用户的问题时,才能检索正确的答案。因此,在某种程度上,该模型通过检索讨论问题中包含的术语的文档来工作,但这不能确保检索实际包含问题背后推理的适当文档。
因此,为了提高文章检索模块的性能,可以使用part of、subset、is-a等多种语义关系和推理规则(举例说明)。每个段落将根据不同特征的平均得分进行加权,并作为候选答案检索模块的输入。
文档检索的挑战与解决方案
- 挑战:在问题和答案文档中存在使用表述不同的词汇术语
解决:需要搜索带有实际问题和转述问题的相关文档 - 挑战:检索到的文档不准确,因为正确的文档包含相同的单词,但没有满足用户的需要
- 解决:从问题中理解用户的需求,以那个方向搜索文档,而不是从重叠的单词搜索文档
对问题分析和文档检索模块的现有研究进行综述


5.4 候选答案提取
这个模块从前一个模块中检索到的文档或段落中提取出相关的候选答案集。对于“WHY” 型的问题,可能会有多个答案。检索到的候选答案的恰当性直接影响到最终的准确答案。下面将简要讨论在Why-QA中帮助提取候选人答案的技术。
5.4.1 词法-句法分析
文章的词法和句法分析,有助于识别术语和提取文本的意义,这可以通过标记的词性部分,如名词,动词,和形容词。为了理解句子中涉及到的实体之间的关系,Suzan Verberne in 2007 [Verberne; 2007] 利用篇章结构从检索的文档中抽取答案。她运用修辞结构理论 (Rhetorical Structure Theory,RST)作为话语分析的模型,发现了两个文本之间的修辞关系(https://www.sfu.ca/rst/)。既然对“WHY” 型问题的回答提供了对问题中所问事件的推理,那么与因果关系相关的各种关系,如原因、目的、动机和环境,在文章中已经被确定。与这些关系类型相关的句子,如在问题中发现的,被提取作为候选答案。对336个QA对进行人工分析;其中195个 why-question(85.0%) ,可以找到正确的参考答案;约有141个问题(42.0%)无法在文档集中提取答案。这样的问题被分为:
(1)需要足够的领域知识(world knowledge)才能找到正确答案的问题;比如,文本段 “Cyclosporine can cause renal failure, morbidity, nausea and other problems” ,如果我们知道充足的知识关于“renal failure(肾衰竭)、morbidity(发病率)、nausea(恶心)”,那么就可以推断出上述文本段是 “Why is cyclosporine dangerous?” 的答案。
(2)在16.4%的问题中,候选问题包含问题主题0和答案,但两者之间没有RST关系。
(3)在5.1%的问题中,虽然支持问题主题,但无法从文本中找到答案的位置。
(4)对于3.6%的问题,RST(修辞结构理论)关系的核心部分与问题主题匹配,而对应的附属部分(satellite part)没有描述正确答案。需要自动化RST注释,但它不如手工注释完整和精确。因此,在可行的情况下,可以使用部分自动话语标注来提供回答why-questions 所需的信息。这种方法在答案文本中没有明确的关系或因果模式(如海啸可能由地震引起,我迟到了因为我被卡住了等),但隐含的因果关系(如寒颤,疟蚊等)中失效。
在我们的研究中,我们也使用了修辞结构理论(RST)关系[Manvi;2018] 提供不同类型的答案类型来回答Why-Questions,如
(1) comparative answer:描述事实的比较
(2)motivated answer:包含行为背后的动机
(3)conditional answer:包含不同时间背景下的原因
(4)justified answer:为被理论证明的创意提供理由
(5)unconditional answer:描述某些事件的原因,而不考虑任何情况
(6)interpreted answer:包含与逻辑、数学和统计领域相关的事实的逻辑推理
RST提供了一组关系名称,它提供了两个文本范围(称为核心和附属 nucleus and satellite)之间的关系。 Why-QA 侧重于提供推理,因此文本的核心部分声称事件,而文本的附属部分提供证据。有两种关系,一种存在于核心与附属之间,另一种存在于多核心之间。我们尝试将这些关系名称映射到预期的答案类型,假设问题的正确候选答案包含文本块之间的关系,下表将讨论这些关系:

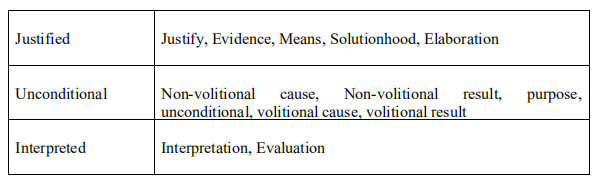
答案类型是通过查找问题中的词汇特征来确定的。因此,最符合特征的句子作为一个问题的候选答案表现得更好。
5.4.2 因果关系
因果关系与 Why-QA 密切相关,因为它描述了他们的答案的解释。研究人员采用了各种技术来识别问题和文章之间的因果关系,以提取候选答案。
研究以在文本中找出手写的因果模式开始,并检索出包含这些模式的候选答案。本文讨论了一些工作,利用不同的方法和不同的QA对来匹配不同的因果模式来提取候选答案。
Girju in 2002 and 2003 [Roxana Girju; 2002, 2003] 提出了一种自动发现具有因果关系的词汇句法模式的学习方法,并提出了因果问题的分类方法。作者考虑形如 的句内模式,其通过选择因果语义关系而发现的,例如 CAUSE-TO 和选择包含这关系的名词短语。他们还将问题类阐明为:
(1)明确的因果关系问题,包括详尽的关键词如,effect,cause,consequence 等等
(2)模糊或半明确的问题,包含反映因果关系的详尽和模糊的关键字,概括时确定其语义类型,如 create, trigger, produce 等
(3)隐式问题不使用显式关键词,而是采用隐含推理,并结合深层语义分析、常识和背景知识。
然而,系统不完善是由于
(1)因果关系的模糊性 (e.g. trigger, lead to, elicit, originate etc.)
(2)有限的命名实体识别 (e.g. the names of person, places, animals are not exhaustive) in WordNet
(3)研究只考虑了在句子中遇到的因果模式 (e.g. Tsunamis are generated because ocean’s water mass is displaced) ,而不考虑句子中的句型 (e.g. Earthquake causes seismic waves. This causes tsunami)
这就需要在回答 Why-type 的问题时自动检测因果关系。
Hovy in 2006 [Hovy; 2006] 提出了阐明两个要素之间语义关系的基本要素(Basic Element ,BE)方法; Fukumoto in 2007 [J Fukumoto; 2007] 采用了该方法为非事实类型的问题 (why-type, definition-type and how-type) 提供不同的答案抽取模式。作者分析了 Verb + because, Noun + because 等形式的抽取方式 和 非抽取方式 ( Pronoun + Postposition + because, Verb + because + Postposition )。与抽取模式相匹配的候选答案被标记为相关的,与非抽取模式相似的被删除。与人工提供的评分相比,该方法获得了50%的准确性。由于问题和答案抽取模式较多,该方法得到的结果有限。BE 评分法在句法结构不同但意思相同的候选答案中失效。因此,通过使用不同但是意思不变的单词重述候选答案,可以提升性能。
Pechsiri and Kawtrakul in 2007 [Pechsiri; 2007] 通过提取大量EDUs(基本话语单位,Elementary Discourse Units )中的因果关系知识,在文档中识别因果事件、诱因、和其他有效单位。EDUs是由对应于文本的RST树的叶节点表示的最小话语单位。EDUs是包含多种原因及其结果的短句或子句。该方法被应用于农业和健康领域的文本中,通过使用支持向量机和朴素贝叶斯分类器学习动词对规则,利用因果间和因果内的EDUs。该方法在农业或健康领域的准确率达到96%,但在识别连续EDUs之间的有效边界方面存在局限性。他也可以用在其他领域,通过从WordNet中提取不同的话语标记和NP对 来表示因果关系,可以获得较高的精度。该方法的精度达到96%,但连续EDUs之间的有效的边界识别是个挑战。此外,尽管考虑了动词和NP对,speech的其他部分也可以使用。
Mori et. al. in 2008 [T. Mori; 2008] 提出了一种回答非事实性日语问题的新颖方法。他们从社交问答网站上提出的一系列问题提取出问答对。通过保留一组功能性和内容性单词(如疑问词,动词,修饰语,原因,方法等),但用词性(parts-of-speech)替换其他单词,可以确定每个问题的重点。通过在两个度量上对句子评分来确定合适的候选答案,其中度量1 是:找到问题和候选答案之间的内容相似性,而度量2是:从先前提取的具有相同写作风格的问题的答案中映射出词汇句法模式和线索表达;该方法用在不同的Why, how 和definition类型的日语问题 和 与主题内容信息相结合的线索中,从而提高了准确性,进一步可以通过合并高级语言模型和打分函数来进一步提高准确性。
上述方法侧重于从文本中识别因果模式,从而帮助提取出合适的候选答案。此外,下面讨论的研究通过使用不同的技术来识别句子中的因果部分,从而解决了 Why-QA 中的因果关系。
Reyes S. and Elizondo in 2012 [S Vazquez-Reyes; 2012]提出了一种回答因果问题的方法论,其首要目标是理解问题。利用了由词袋、句法和词汇语义组成的特征。由于回答 “WHY” 问题需要观点、解释或理由,所以需要因果关系来识别意见和回答因果问题。答案抽取基于四种度量,它们是简单匹配(通过对出现在答案中的停用词和非停用词的加权和来得到总权重)、最长连续子序列( 度量问题和可能的答案中出现的连续单词)、Sorensen 相似系数( 使用Sorensen 指数计算问题和答案文本之间的相似度,该指数是两个集合共有的元素数量与每个集合中元素数量之和的比率的两倍 ),和词汇语义相关度WordNet-based ( 使用WordNet作为资源找到带文本词的疑问词,文本词的同义词和文本词反义词的同义词之间的相似性 )。它们根据候选答案排序进行加权。
该研究有效地赋予了知识以提取特征,并对为什么问题进行分类。
对于答案明确和不明确的文本,该方法的查全率recall为36.02%,MRR为0.219。在含有隐含答案的文本中,查全率recall为61.46%,MRR为0.373。
为了改进现有的工作,作者声称要超越词汇句法的方法,并尝试表达知识和推理的技术,目的是解决知识、证明和理性的信念背后的 WHY 问题的答案。
Jong-Hoon Oh et. al. in 2012 [Oh; 2012] 用词语或从句之间的 句子内和句子内的因果关系来回答 WHY 问题,其中句子的结果部分描述了被提问的问题,原因部分为前句提供了一个问题的答案。句子间的因果关系表示为: [Earthquakecausesseismicwaveswhichsetupthewaterinmotionwithalargeforce]cause[Earthquake causes seismic waves which set up the water in motion with a large force]_{cause}[Earthquakecausesseismicwaveswhichsetupthewaterinmotionwithalargeforce]cause?,这导致 $ [a tsunami.]{effect}。句子内的因果关系表示为:。句子内的因果关系表示为:。句子内的因果关系表示为: [Tsunamis]{effect}$ 是由于 [thesuddendisplacementofhugevolumesofwater.]cause[the sudden displacement of huge volumes of water.]_{cause}[thesuddendisplacementofhugevolumesofwater.]cause? 导致的。在这两句话中,结果部分描述了问题“ Why are Tsunami generated? ”,而原因部分则构成了一个问题的候选答案。原因和效果部分是由句子中两部分之间的因果关系来确定的。该方法应用于日日语 WHY 类问题,因果关系仅限于使用 because、this cause、are cause by 和 as a result 等线索短语。上下文特征在检索合适的候选答案时也起着重要的作用,并通过正则表达式在候选答案中识别出相应的线索短语;对于每个线索短语,作者分别提取了三个句子,一个包含短语,另外两个是候选答案中的前句和后句。还使用以下几个因素来衡量因果关系作为答案的合适性:术语匹配(其中结果部分必须包含至少一个匹配的内容词,例如问题中的名词,动词,形容词),因果树匹配(其中结果部分必须包含至少一个partial tree,覆盖问题中一个以上的内容词) 和激励极性匹配(通过识别文本中名词/实体的作用是否是激活或抑制)。因此利用因果关系法和激励法寻找合适的候选答案,证明了系统对合适的候选答案可以达到83.2%的精度。
Jong-Hoon Oh in 2016 [Oh; 2016] 扩展了他之前的工作,检索了由七个句子组成的段落,其中至少有一个线索短语,用于识别因果关系。因此,该方法从20亿个网络文本中提取了大约42亿个段落。为了检索合适的候选答案,生成了两种类型的布尔型查询,例如n1ANDn2AND...njn_1 AND n_2 AND...n_jn1?ANDn2?AND...nj? 和 n1ANDn2AND...njAND(va1OR....vak)n_1 AND n_2 AND...n_j AND (va_1 OR ....va_k)n1?ANDn2?AND...nj?AND(va1?OR....vak?) 。此外,我们还观察到,一个准确的候选答案必须包含“WHY”问题中的所有名词,这有助于从每个查询的组合结果中检索出最上面的段落。检索的候选答案 送入答案重排序模块。
Jong Hoon Oh et. al. in 2017 [Oh; 2017] 通过处理隐含的因果关系扩展了他们的工作。由于隐含因果关系的文本可能会在其他隐含线索的文本中表达,因此通过自动识别显性因果关系并在回答段落中对隐性因果关系进行补充来改进why-QAS。……………………
Karyawati et. al. in 2018 [2018] 采用语义相似度度量和选择性因果检测相结合的方法提取候选答案。…………………………
5.4.3 语义和上下文分析
Yang et. al. in 2016 [Liu Yang; 2016] 使用语义和上下文特征来检索非事实Web问题的候选答案,以解决问题和答案词之间的词汇鸿沟问题。可观察到三个语义特征:
(1)显示语义分析 [T Gottron; 2011] 使用Wikipedia使用ESA表示文本,通过查找问题和回答句子的ESA向量之间的余弦相似度来计算语义相关性
(2)Word Embeddings 其中使用词袋和skip-gram模型用向量来表示问题和答案中的单词,其中两个向量之间的相似度是 两个向量之间的平均成对余弦相似度
(3)Entity Linking feature 使用实体链接系统(Tagme)在语义上表示查询和答案句子,Tagme 通过将文本链接到适当的知识库,从而获得相关概念,计算 维基百科链接查询 qqq 和 句子 sss 的Jaccard相似度为
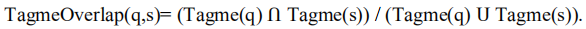
除了三个语义特征外,上下文特征还被用来捕捉候选答案的上下文,其中上下文是由与给定句子相关的前句和后句定义的。
作者对语义和上下文特征的效果进行了实验和评价,发现语义特征和上下文特征在提高系统性能方面起着重要作用。
检索非事实回答候选项的性能可以通过更增强的特性来扩展,如语法和可读性。要检索“WHY”类型问题的正确答案,需要确定问题和候选答案集的准确含义。此外,有些问题需要根据所问的上下文来回答。因此,从候选答案中寻找正确答案,既需要语义要求,也需要上下文要求。
表8:对候选答案抽取模块的现有研究进行综述





候选答案抽取的挑战和解决办法:
- 挑战:在问题和相应的正确答案中的不同的词汇术语使用
解决:需要搜索有实际问题和转述问题的相关文档 - 挑战:检索到的文档不准确,因为正确的文档包含相同的单词,但没有满足用户的需要
解决:从问题中理解用户的需求,以那个方向搜索文档,而不是从重叠的单词搜索文档 - 挑战:准确的一个答案很难检索,因为 WHY 型的问题可能有多个答案
解决:需要一个总结的答案,必须解决包含在多个检索答案候选人的所有原因。提出了一种新型的积分器和总结回答工具 - 挑战:不同的用户可能会给出不同的答案
解决:用户日志需要考虑进去用户的不同兴趣
5.5 答案重排序
答案重排序模块获取从答案提取模块获得的答案候选者的集合,并对它们重新排名,以向用户返回一个准确的最高排名的答案。 使用分类器对答案进行排名,分类器根据定义的特征集为每个答案候选者分配分数进行训练。 最终分数是通过根据每个候选答案中发现的特征得出的分数求和而得出的,因此模块的性能取决于为得分选择的特征。
5.5.1 词袋模型有关的特征
Suzan Verberne in 2006 [Verberne; 2006] 采用词袋模型对候选答案进行重新排序,计算问题袋与答案袋之间的重叠单词。问题袋包含问题中的名词短语、主要动词和宾语对应的术语,而答案袋包含答案中的单词、动词。重叠函数为:
S(Q,A)=(QA+AQ)/(Q+A)S(Q,A)= (QA + AQ) / (Q+A)S(Q,A)=(QA+AQ)/(Q+A)
- QAQAQA 表示在答案袋中出现频率超过一的问题术语的数量
- AQAQAQ 表示在问题袋中出现频率超过一的问题术语的数量
- Q+AQ+AQ+A 表示问题和答案中的术语的总数
特征是:
-
**i. 术语频率-逆文档频率打分 **
Tf-idf评估单词相对于文档集合的重要性。术语频率(TF)表示文档中某个术语的基数,计算方法为某个术语在文档中出现的次数与文档中包含的术语总数的比率;逆文档频率 (IDF) 表示包含某一特定术语的文档数量。这个评分函数用于确定文档与用户查询的相关性。术语频率对每个术语赋予同等的重要性,例如术语 “the” 比更有意义的术语出现的频率更高,这就导致迫切需要降低文档的得分。逆向文档频率的重要性在于减少频繁出现的词汇的权重,加强较少出现的词汇的权重,并将其作为文档总数对包含词汇的文档总数的自然对数来计算。 Murata et. al. in 2007 [Masaki; 2007] 曾使用此评分函数对问题的候选答案进行排序。 -
ii. 问题的句法结构
从句法上看,问题中有一些部分如短语头、短语修饰语、主语、主要动词、名词性谓语、主句的直接宾语、所有的名词短语等对候选答案排序具有重要意义。问题的这些部分的重叠是用答案术语包来衡量的。重叠部分最多的候选答案的排名较高。 -
iii. 问题的语义结构
为了获得候选答案的准确性,使用语义特征来确定重点和问题的需要。 对于大多数问题,句法主语是主要重点,但是在语义上较差的主语中,言语谓语是重点,对于词源问题,被动句的主语补语是主要重点。因此,语义特征如
(1)在问题焦点和文档标题之间匹配的单词
(2)问题焦点词与所有回答词之间的关系
(3)问题焦点词与所有非焦点词的关系
上述语义特征被用来排序候选答案。 -
iv. 答案的上下文
除了文档的标题,答案上下文的其他方面对答案排名也很重要。例如,问题术语和维基百科文档标题的重叠,问题术语和答案文档标题的重叠,文档中答案段落的相对位置,部分标题中包含的一组提示词与答案段落中包含的一组词之间的重叠。 -
v. 同义词
问题和回答术语之间可能存在词汇不匹配,这可以通过合并大量的WordNet同义词来解决。这些特征是通过考虑问题中包含的术语的同义词来设计的,该问题包含答案术语包中至少有一个同义词的问题术语的数量,以及问题术语包中至少有一个同义词的回答术语的数量。 -
vi. WordNet 相关性
WordNet是一个词汇数据库,它将名词、动词、形容词、副词组合成具有不同概念的同义词 [Miller; 1995] 。这些同义词集通过各种词汇和语义关系相互连接。WordNet关联工具用于计算问答词之间的关联度量。语义相关性是通过在候选答案中找到WordNet同义词集中问题术语及其同义词的百分比来计算的。处理语义和上下文特性的其他WordNet特性也对Why-QAS产生了很大影响。 -
vii. 线索短语
最后一组在回答WHY问题时很重要的特征是提示短语的使用。它们是用来描述两个文本片段之间关系的连接词。提示短语,如because,since,as a result,连接的原因和他们的影响有助于回答为什么的问题。
词袋模型是通过对所有候选答案进行排序来获得最准确答案的基本要求,但它也存在着忽视语法结构、不考虑单词排序等局限性。作者提出了BOW模型对候选答案重新排序的特征,假设问题和回答段落的某些部分比其他部分对排名的影响更大。但是,每个特征效应之间的差异的数量值是主要问题,这需要解决最佳重新排序的候选答案。
5.5.2 形态句法分析
另一种对候选答案重排序的方法侧重于从形态和句法上进行分析。这种方法从答案句子中识别出语素的n-gram、词短语和句法依赖 [U Mosel; 2012]。语素是单词最小的语法单位。它可以是一个有单独意义的根词,也可以是附加到其他语素的后缀。例如,单词 “cats” 分为两个词素,即 cat(词根)和s(后缀)。单词短语由一个或多个单词组成,例如,名词短语如 “barking dog”,动词短语如 “walking to the door”等。
句法依赖 是一种二元操作,通过语义上解释句子,将两个相关词的外延联系起来。例如,句子“Mary ran”是由 “subj”作为句法依赖性,其中“ran”是首词,“Mary”是从属词。更多可能的句法依赖是“subj”(主语)、“dobj”(直接宾语)、“iobj_prepname”(动词和名词之间的介词关系)、“prep-name”(两个名词之间的介词关系)、“attr”(名词和形容词之间的属性关系)。
以下研究采用了这种方法:
Jong-Hoon Oh. et. al. in 2013 [Oh; 2013] 利用形态进化分析对候选答案重新排序。词素分析和句法依赖分析器应用到问题和候选答案中来提取语素的n-gram、单词短语和句法依赖。这有助于形成四个特性:
(1)对问题和候选答案中包含的所有句子进行n-gram的计数
(2)候选答案的n-gram 被发现包含一个问题的术语
(3)包含一个线索项的n-gram 从问题和候选答案中分别提取
(4)候选答案中存在问题项的百分比,计算为候选答案中问题项的总数与问题项总数的比率
与BOW模型不同的是,形态对等分析考虑了语法结构和词的顺序,但由于没有包含语义特征,不能给出较高的性能。在Why-QA中,当问题的意思被很好地理解时,正确的答案可以被检索出来,并且进一步帮助检索到由同一作者在他们的进一步研究中纳入的正确答案段落的意思。
5.5.3 语义词类
除了形态和句法分析的特点,Jong-Hoon Oh in 2013 [Oh; 2013] 采用语义词类进行回答排序。语义词类是指由名词聚类算法构造的语义相似的上下文中要使用的词的集合,其中名词聚类算法由 Kazama and Torisawa in 2008 [J Kazama; 2008] 提出。分类器是根据一个特征来训练的,这个特征表示在问问题和候选答案中出现的语义类之间的关联。为分类器提供了一个积极的训练样本,帮助分类器学习和识别问题的正确答案。将候选问题和候选答案的n个克词转换成各自的词类,找出候选问题的n个克词与其所使用的语义词类之间的对应关系,找出它们之间的合适关系,从而帮助提取出合适的问题答案。除了名词短语外,动词、副词、代词、形容词的各种组合也可以形成语义类,这将进一步有助于提高系统的可行性和有效性。
5.5.4 情感分析
Jong-Hoon Oh et. al. in 2012 [Oh; 2012] 在why-QAS中引入了情绪分析对答案重新排序,在这种情况下,不同答案中包含的单词和短语的情绪差异被识别出来。答案排序器是根据具有明显极性的情感词的特征进行训练的。使用意见提取工具利用 词汇极性词典 对情感短语进行极性识别。
5.5.5 内容相似特性
Higashinaka and Isozaki in 2008 [Higashinaka; 2008] 探索了各种特征,以训练基于内容相似 的“WHY”类型QAS的答案重新排序器。以下有三个例子:
(1)问题和候选答案有相同的词
(2)问题和候选答案虽然词语不尽相同,但内容都很有重点
(3)语义相似的内容与不同的句子。
如果候选问题和候选答案由匹配项组成,它们有足够的可能共享相同的内容,通过余弦相似度或n-gram重叠来计算。但是,如果候选问题和候选答案不包含匹配的术语,但是通过测量包含候选答案的问题和文档之间的相似性,可以发现它们具有相似的内容。但是,如果问题和候选答案在语义上相似但包含不同的短语,则通过利用单词的同义词和语义相关性特征来衡量相似度[MAH Taieb;在WordNet的同义词典中提到。因此,上述方法通过比较问题和答案段落的内容和重点来解决相似性问题。
5.5.6 因果关系特征
Higashinaka and Isozaki in 2008 [Higashinaka; 2008] 除了因果表达和内容相似特征外,还提出了因果关系特征,对候选答案进行重新排序。
5.5.7 Metzler-Kanungo特征
Metzler and Kanungo in 2008 [D Metzler; 2008] 提供了六个特征训练答案重排序模块。
5.5.8 CNN & CTK 方法
Kateryna Tymoshenko et. al. in 2016 [K. Tymoshenko; 2016] 结合了 Convolution Tree Kernels (CTKs) [M Collins; 2002] 和 Convolutional Neural Networks (CNNs),用于答案重排序。他们研究了用于学习分类和排序功能的CTKs。他们提出了一种独特的深度学习方法来创建问答段落对。基于CNNs实现了两种句子模型,计算给定的问题(xqx_qxq?)和文档(xdx_dxd?)两个向量之间的语义相似度得分如下:

为了获取相关信息,在嵌入词中插入重叠词,并将增强词通过层传递,以混淆问答段落之间的对应关系。
作者在非事实的QA中实现了CTK和CNN,特别是在WikiQA和TREC13上,这两个方法的表现优于其他所有方法。比cnn ctk更有效,例如,TREC13、ctk达到MRR 85.53和75.18的地图,cnn达到MRR 77.93和图71.09为ctk的语法解析使用两个分类器的分类和命名实体识别问题而cnn条款适用于无监督数据集。
5.5.9 文本蕴涵
Harabagiu and Hickl in 2006 [S Harabagiu; 2006] 将文本蕴涵 (TE) [DZ Korman; 2018] 作为一种语义关系,以提高一般领域QAS的准确性。当问题及其答案既不包含相似的单词也不包含它们的同义词,然后通过查找文本段之间的文本蕴涵推断出适当的答案。
…………………………
5.5.10 词汇语义语言模型
……………………
表10 关于回答再排序模块的现有研究综述



问题重排序的挑战和解决方法
- 挑战:选择合适的特性来找到最合适的答案
解决:分析了不同特征对QAS精度的影响。根据场景考虑那些起重要作用的特性,提高系统的精度 - 挑战:为特征分配权重
解决:根据特征对回答的影响对特征进行排序,并相应地分配权重,这可以通过训练神经网络来实现 - 挑战:不同词汇的用法问题和最佳答案候选人。有时,最佳回答候选人在一个问题中不会使用类似的词,因此排名低于其他回答候选人
解决:需要考虑语义特征,并赋予它们比其他特征更多的权重,以返回排名最高的答案
6. 性能指标
问题回答系统(QASs)是通过确定答案的正确性来评估的。如果一个答案属于适当的文档并对所询问的问题作出反应,那么这个答案就被称为正确的。有一些常用的指标用来衡量系统的性能[O Kolomiyets; 2011],其中包括MRR、Precision、Recall、F-measure是研究人员常用来与之前的研究进行比较的方法。
6.1 Mean Reciprocal Rank(MRR)
以下解释来源于网络
MRR得核心思想很简单:返回的结果集的优劣,跟第一个正确答案的位置有关,第一个正确答案越靠前,结果越好。具体来说:对于一个query,若第一个正确答案排在第 nnn 位,则MRR得分就是 1/n1/n1/n 。

对单个问题求倒数(RR),它是通过找到问题的第一个适当答案的倒数来衡量的。如果没有找到正确答案,分数为0。如果相关答案在第1位,RR计算为1,如果相关答案在第2位,RR计算为1/2,以此类推。
即:
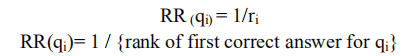
MRR是均值倒数,计算系统对N个问题集的答案取倒数的均值的能力,其计算方法为:
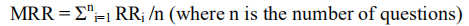
因此,它描述了相关结果在多早得到排序。如果它的值接近1,则被认为是完美的;如果接近0,则更糟。因此,MRR越多,系统的精度就越高。
6.2 Precision
精度是信息检索的传统指标之一,它决定着检索到的相关文献的数量。它定义为检索到的与用户问题相关的回答文档的比例。

Good precision is just an indication of good accuracy.
系统中可能存在随机和系统误差的可能性。在随机误差的情况下,good precision means good accuracy 但是系统误差的存在使我们不能得出 “good precision denotes good accuracy.” 的结论。
6.3 Precision at n (P@n)
来源于网络
需要一些指标来度量前几个结果的准确率,P@n 就是搜索结果前N个的准确率
P@N=与检索相关/NP@N=与检索相关/NP@N=与检索相关/N
假设有两个主题,主题1有4个相关网页,主题2有5个相关网页。某系统对于主题1检索出4个相关网页,其rank分别为1, 2, 4, 7;对于主题2检索出3个相关网页,其rank分别为1,3,5。
对于主题1,P@1=1/1,P@2=2/2,P@3=2/3,P@4=3/4,P@5=3/5,P@6=3/4,P@7=4/7,P@8=4/8……
Precision@nPrecision@nPrecision@n 找出相关的 top-n 答案文档。这些top-n是对应于问题的前n个排序的答案。n对应于显示给用户的文档数量,Precision@1Precision@1Precision@1表示只有第一个文档显示给用户,Precision@5Precision@5Precision@5 即提取五个给用户。
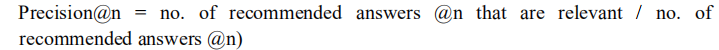
这本身并不能对系统的测量准确率起主要作用,而是用于其他度量,即Mean Average Precision。
6.4 Mean Average Precision(MAP)
来源于网络
Average Precision,就是对一个Query,计算其命中时的平均Precision,而mean则是在所有Query上去平均
例如:假设有两个主题,主题1有4个相关网页,主题2有5个相关网页。某系统对于主题1检索出4个相关网页,其rank分别为1, 2, 4, 7;对于主题2检索出3个相关网页,其rank分别为1,3,5。对于主题1,平均精度均值为(1/1+2/2+3/4+4/7)/4=0.83。对于主题2,平均精度均值为(1/1+2/3+3/5+0+0)/5=0.45。则mAP= (0.83+0.45)/2=0.64。
它计算每个问题的平均精度得分的平均值,从而帮助确定一个问题的前n个候选答案 的总体质量。
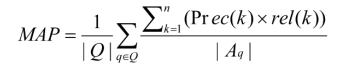
- QQQ,问题集
- AqA_qAq?,一个问题的一组正确答案,q∈Qq \in Qq∈Q
- Prec(k)Prec(k)Prec(k),在前 n 个候选答案中的 precision at cut-off k
- rel(k)rel(k)rel(k),指示符,如果排名 kkk 的项是 AqA_qAq? 中的正确答案,则为1;
(结合前面的例子理解)
因此,它是一个比精度更有效的指标,因为系统是在一个整体上衡量性能的,它查找QAS中每个问题的精度分数,而不是查找单个问题的精度分数。
6.5 Recall
召回率也被称为灵敏度,用以评估与问题相关的答案文档中被检索到的比例。它表示为检索到的相关文档的概率,用检索到的相关文档的数量除以相关文档的总数来计算。
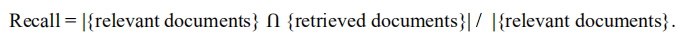
因此,它度量找到查询的所有相关结果的能力。我们试图增加它的值,以提高准确性。
6.6 Recall @k
它与recall类似,但计算的是对应一个问题的前 k 答案文档中相关文档的比例。
6.7 F-score
可见精度(precision)和召回(recall)可以增加提高准确性(accuracy)。因此分配精度和召回的权重是一个问题,即保持平衡的精度和召回,F-score 或 F-measure 计算得是:精度(precision)和召回(recall) 的调和平均数:
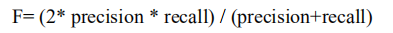
以下来源于网络
往往需要对模型的精确率和召回率做出取舍:
比如在一般的搜索任务时,在保证召回率的同时,尽量提高精确率;
在癌症检测、金融诈骗任务时,在保证精确率的同时,尽量提高召回率。
很多时候,我们需要综合权衡这2个指标,这就引出了一个新的指标F-Score,这是综合考虑Precision和Recall的调和值:
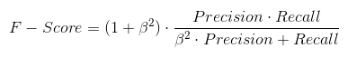
当 β=1\beta =1β=1 时,成为 F1-Score,这时召回率和精确率都很重要,权重相同。当有些情况下我们认为精确率更为重要,那就调整 βββ 的值小于 111 ,如果我们认为召回率更加重要,那就调整 β的值大于111,比如 F2-Score。
结论
通过文献调查,我们列出了现有关于WHY式问答系统的研究成果。一个模块的准确率的提高可以导致整个系统整体性能的提高。该调研描述了在各个模块上所进行的工作和所使用的技术、这些技术的准确性以及未来为提高这些模块的准确性而进行的改进。
一般QAS所共有的论点,即理解自然语言问题并准确地处理它们以获得相关的正确答案,也是Why-QAS所关注的一个重要问题,同样重要的还有选择相关文档来研究答案。
一个重要的研究领域/挑战是理解问题的焦点和意义(语义)。问题所使用的词与对应的答案之间存在着词汇差距,需要更好地理解问题的语义和问题的处理过程,以确定正确的有意义答案。
另一个挑战是在重排序候选答案。根据训练分类器的特征集给候选答案集分配分数。答案的确定有形态句法特征、词袋特征、因果关系特征、情感极性特征、词类特征等。
在QAS的每个模块中,讨论了不同的挑战和解决方案,这将有助于研究界在这些问题上的工作,并试图提高系统的性能。