Multi-step Cascaded Networks for Brain Tumor Segmentation[�ಽ�������������ָ�����]
- Abstract
- 1 Introduction
- 2. Methodology
-
- 2.1 Multi-step Cascaded Network
- 2.2 3D U-Net Architecture with Deep Supervisions
- 3. Experiments
-
- 3.1 Preprocessing
- 3.2 Implementation Details
-
- 3.3 Segmentation Results
- 4. Disussing and Conclusion
- д��ǰ��,�������������BraTS2019�ھ��ķ����ʵ����һ���ಽ���ɵ����硣
Abstract
- ���������ӣ���ʼ�Ƚ���������������Ҫ��
- �������Զ��ָ������������Ϻ����Ƶ��������������ż�����Ҫ�����á�
- Ȼ��˳���Ƴ����ǵĹ�����ɶ
- �ڱ����У����������һ�ֶಽ�������磬�����翼�����������ӽṹ�IJ�����˽ṹ�������ӽṹ�����˴Ӵֵ�ϸ�ķָ
- �ڷָ�����У���ǰһ���Ľ����Ϊ��һ����������Ϣ����ָ������ϸ�ķָ���̡��������綼�Զ˵��˵ķ�ʽ����ѵ����������������������ṹ��BraTS2019�ھ�����˼�뼫�����ƣ���������һ����ηָ������˼���벽�衿
- ���⣬Ϊ�˻����ݶ���ʧ����ͼ��ٹ���϶ȣ�������ÿһ�������˼������������Ϊһ����ȼල�����ֱ������˼���������ǿ���ԣ����������ָ�֤���Ƿdz���Ч�ġ����ƺ����ֹ����ģ�Ͷ�������ȼල���������
- �������focal loss��ʧ�������������ͱ������Բ�ƽ������⡣��������Կ���һ�¡�
- ���
- ���ǵ�ģ����Brats 2019����֤���ݼ��Ͻ����˲��ԣ����������������������ĺ���ǿ��������ƽ������ϵ���ij�������ֱ�Ϊ0.886��0.813��0.771���������https://github.com/JohnleeHIT/Brats2019���ҵ������Ǵ����������Ļ�����ʵ���ģ�͵����徫�Ȳ�û�кܸߡ�
1 Introduction
- �����������ָ����Ҫ���������壬�Լ���������һЩ�����������Ҫ���ǽ������������ָ���ٴ����塣
- �������������ص��Բ�����֮һ�����ж��Խ���������������͡��������س̶ȣ��������ɼ�Ϊ���ࣺ��Ϯ�Խ���������HGG����ƽ��Ԥ��������2�ꣻ�ºͽ���������LGG����ƽ��Ԥ���������ꡣ
- �������������൱�ߣ���˶Խ�������������Ͼ�����Ҫ���壬������������Ƹ��ʣ������Ƕ���LGG��Ŀǰ�����ƽ���������ܵķ��������������ƺͷ��ơ�
- �����κ�һ�����Ʋ��ԣ�����ǰ����Բ����������ȷ�ij���ͷָ�������ض����Ե���Ч�ԡ�
- ����Ϊɶ���õ�MRI����������������ʵ���DZ���������ݼ�
- ���������еij��������У�MRI����߷ֱ��ʡ��߶ԱȶȺ�Ŀǰδ֪�Ľ�����в��Ϊ��������������ѡ��
- ��Ŀǰ���ٴ������У��ֶ��ָ������MRIͼ����һ�ֳ��������������֤����dz���ʱ����������Ա���׳�������ˣ����һ���Զ��ָ�������о��DZ�ڼ�ֵ��
- ��ʼ����Ŀǰ���Զ��������ָ��ϵ�һЩ�о����
- �����о���Ա����˼��ֻ������ѧϰ�����ѧϰ����Ч���������������⡣
- ����Щ����ķ����У�Zikic����[1]ʹ��dz��CNN������Ի������ڷ�ʽ��MRI�����岶���2Dͼ�����з��ࡣ
- Zhao����[2]��3D�����ָ�����ת��Ϊ3άƽ���2D�ָ��ͨ���ü���ͬ��С��patches�ķ�ʽ�����߶ȡ�[����ƽ���2D,��������������ν��2.5D��]
- Havaei����[3]�����һ�ּ����������磬����ͬʱ����ֲ���ȫ����Ϣ��[������Ҫ˼����������������]
- Cicek����[4]����ͳ��2D U-net�ָ�������չ��3Dʵ�֣�ʹ����ָ��Ϊ���ط�ʽ��
- Kamnitsas����[5]�����һ����ΪDeepMedic��˫·��3D�������磬�����϶�߶���������Ϣ����ʹ��3Dȫ����CRF��Ϊ����������ϸ���ָ�����
- Chen����[6]��DeepMedic�����˸Ľ������ȴ�ԭʼDeepMedic��ѡ��Ķ���вü�3D������Ȼ��ϲ���Щ����������������ѧϰ������Ϣ�����⣬��������������ȼල���Ը��õش����ݶȡ�[��߶ȴ�����������]
- Ma����[7]����������ʾѧϰ���ԣ�ͨ��ʹ���ض���ģ̬�����ɭ����Ϊ����ѧϰ�ˣ���Ч�شӶ�ģ̬ͼ����̽���ֲ�����������Ϣ��������֯�ָ
- �����о���Ա����˼��ֻ������ѧϰ�����ѧϰ����Ч���������������⡣
- ���ܱ���˼�����Դ
- ��Havaei��Cicek�����������������һ�ֶಽ�����������ָ��������ǽṹ����������3D U-net��Ϊ�����ķָ�ṹ����������Ӵֵ�ϸ�����Կ�����һ�ֿռ�ע����ơ����������˵�����ܱȽ�ǣǿ��
2. Methodology
- �ڶ����������ӽṹ������������Ļ�����(��ͼ1)������֤����һ���ֲ�����˽ṹ��
- ���������һ���ʺ����������ָ�����Ķಽ�������硣��������ķ�����Ҫ�����������棬�����������£�

2.1 Multi-step Cascaded Network
- ����ʲô�Ƕಽ�������磬�Լ��������õ�����
- ������Ķ༶����������ͼ2��ʾ���÷����ԴӴֵ�ϸ�ķ�ʽ�ָ������ǽṹ�IJ�νṹ��

- �ڵ�һ���У�Ϊ������[8]����ϸ�������ֶ�ע��Э�鱣��һ�£�ʹ����MRI�������ص�����ģʽ(FLAIR��T1CE)��Ȼ������ͨ���������������һ�ָ������Դ��Էָ���������(WT)���������������������ǽṹ��
- �ڵڶ����У�ͬ���أ�����ѡ��T1ceͨ����Ϊ����Դ���������Ľṹ���зָ���⣬��һ�����Բ���Ľ�����Ա������ڶ��������������Ϣ��ͨ������һ�����ɵ�������T1ce������ˣ��ڶ��ָ����罫����������Ӧ���������Ӷ������ָ�TC�ṹ��Ȼ���ɵڶ�����Ա��ڱεľ����д������Ӷ�����TC�ṹ(ǰ�������������˲�����ʵ���ǰ�������С����һ�εĽ���ڽ����������Եõ��ڶ��εĽ����
- �����һ����Ҳ���ϸ��һ����ͨ��ͬ���IJ��ԣ�����Ҳ���Դ��������еõ���ǿ������(ET)�ǽṹ���������������Ľ�������һ�𣬵õ����յ��������ָ�ͼ����ֻ�õ����ĸ�ģ̬�е�����ģ̬��
- ������Ķ༶����������ͼ2��ʾ���÷����ԴӴֵ�ϸ�ķ�ʽ�ָ������ǽṹ�IJ�νṹ��
2.2 3D U-Net Architecture with Deep Supervisions
- �����Լ���model��ӵ����ȼල��model����Ϊһ����ô������磬���������ȼල���ƺ���ѵ���ĺ�
- �����ǵĶಽ���������У����Dz�����3D U-Net��һ�ֱ�����Ϊ�����ķָ�ṹ����ͼ3��ʾ�����͵�3D U-Net����������·����ɣ�����;��������;��������ʵҲ������ν�ı���ͽ��롿

- ����·����Ҫ���ڶ��������ؽ��б��룬�������λ�����������չ·�������ڶ�����·���б������Ϣ���н���
- ������·��������Ծ���ӣ�ʹ�������ܹ�ͬʱ����ֲ���ȫ����Ϣ�����˵���е�ǣǿ��ֻ��˵��Ծ���ӿ��Դ����������Ϣ��ͬʱ�ֲ�һ�����²������ϲ�����ʧ���Ҹ���������⡿
- ���ǵĻ����ָ�������3D U-NetΪԭ�ͣ����ڴ˻����Ͻ�����һЩ�Ľ���3D U-Net��������Ļ����ָ��������Ҫ�������£�
- 1.�봫ͳ��3D U-net�ṹ��ȣ���������Ļ����ָ���������չ·�����������������������Ŀ����Ϊ�˸��õش����ݶȣ���������Խ���ķָ�������ݶ���ʧ�ĸ��ʡ���ˣ����ڻ����ķָ���̣�������Ҫ��С����������֧������ʧ������������ʧ�������������Ѳ���������֧������֧����ʧ����֮����Ϊ�������ʧ������
- 2.���ǽ�focal ��ʧ[9]��������ѵ�����̵���ʧ������Ŀ���Ǽ���ѵ���������������������Ų�ƽ�⡣������ʧ�ɱ�ʾ���£�
FL(pt)=?��t(1?pt)��log?(pt)pt={pif y=11?potherwise \begin{gathered} \mathrm{FL}\left(p_{\mathrm{t}}\right)=-\alpha_{\mathrm{t}}\left(1-p_{\mathrm{t}}\right)^{\gamma} \log \left(p_{\mathrm{t}}\right) \\ p_{\mathrm{t}}= \begin{cases}p & \text { if } y=1 \\ 1-p & \text { otherwise }\end{cases} \end{gathered} FL(pt?)=?��t?(1?pt?)��log(pt?)pt?={ p1?p? if y=1 otherwise ??
���� p��[0,1]p \in[0,1]p��[0,1] �Ǵ��б�ע����Ϊy=1\mathrm{y}=1y=1 ��ģ���Ƹ��� . ��?0\gamma \geqslant 0��?0 ��������focal�IJ���, ������˳���ص�����ʾ����Ȩ�ؽ��ͱ���. ��t\alpha_{t}��t? ָ����ƽ������������Ҫ�Ե�ƽ�����ӡ�
- �����ǵĶಽ���������У����Dz�����3D U-Net��һ�ֱ�����Ϊ�����ķָ�ṹ����ͼ3��ʾ�����͵�3D U-Net����������·����ɣ�����;��������;��������ʵҲ������ν�ı���ͽ��롿
3. Experiments
3.1 Preprocessing
- ����һЩBraTS���ݵ�Ԥ������������һ����
- ������BRATS 2019���ݼ�Ϊѵ�����ݣ�����259��HGG��76��LGG MRI�����ṩ����ģʽ(T1��T2��T1CE��FLAIR)���������ݼ��Ĺٷ��������������ݼ����Ѱ�����ͬ��ע��Э��������ֶ��ָ
- ���⣬������Щ���ݼ�������һЩԤ�������������磬����MRI�����������������ͬ�Ľ���ģ���ϣ��ڲ嵽��ͬ�ķֱ��ʣ���������ͷ�ǡ�
- Ȼ��������MRI�豸�IJ����ƺͻ��ߵ������ԣ�ͼ�������д���ǿ�Ȳ����ȣ�Ҳ��Ϊƫ���������Ҫ��ԭʼ���ݼ����ж����Ԥ����������ǿ�Ȳ����Ȼ�ƫ����ѵ�������кܴ�Ӱ�졣Ϊ������ƫ�ó�ЧӦ����������˶���У��������
- ���������ƫ�ó�У�������У�����Ч����N4ƫ�ó�У��[14]�����Ľ�N4ƫ��У������Ϊ�ָ�ǰ��һ����Ҫ��Ԥ�������衣������ǻ�ʹ�ù�һ���������������ݹ�һ��Ϊ��λ����Ϊ��ľ�ֵ��[�б�Ҫ�˽�һ�����ɶ��N4ƫ�ó�У������������һ���о������Ͼ��Ǽ�ȥ��ֵȻ����Ա���]
3.2 Implementation Details
- ��Ҫ��һ��model��ʵ�ֹ�����ʵ��ϸ��
- ���ǻ����Brats 2019ѵ�����ݼ��е��������ݣ�����HGG��LGG��Ȼ���û�����ݼ�ѵ�����ǵ�ģ�͡�
- ��ѵ�������У���������ͨ���õ��������Ե�������������������ȡ��������Ȼ�������ڴ�����ƣ����ǽ�ԭʼ���ݾ�����ü����Ӿ��������ݾ���ѡ���Ĵ�СΪ969696����ѵ�������У�������ÿ�ε����дӻ��ߵ�����������ȡһ��������
- ���ڲ��ԽΣ����ڵ��������壬���ǽ������ذ�˳�����У��Ա����Ԥ���ؽ����������壬����patches�Ĵ�С��ѵ�������е���ͬ��
- ����Ϊÿ���������ݵõ���ͬ�����IJ�������Ϊ���Ǵ��������ȡ�Ĵ��������Dz�ͬ�ġ�
- Ϊ�˼��ٹ���϶ȣ�����������һЩ������ǿ�ķ������������ת�Ƕȣ�ˮƽ�ʹ�ֱ��ת���Լ���һ���ĸ��ʶ���������Ӹ�˹ģ������ʵ֤����������ǿ�����������ָ������Ƿdz���Ҫ�ģ���Ϊ����������ѵ��������Խ��ٵ�����¹�����ϡ�
- ����ʹ��ADAM�Ż��������������Ȩ�ء������ѧϰ�ʱ�����Ϊ0.001������ʧ��������ƽ̹ʱ��ѧϰ���½���0.0005��������ѵ�������У������δ�С����Ϊ1��
- ���ǵ�ģ����NVIDIA RTX 2080��ͼ�δ������Ͻ�����50�����ڵ�ѵ������Լ��Ҫ13Сʱ��
3.3 Segmentation Results
- ������Ҫ�ǽ�������ָ��
- Ϊ�˶���������ķ�������������������ѵ��������֤���ϲ��������ǵ��㷨��ͨ������������ϴ�����������ƽ̨(CBICB��IPP)�����յõ��˷ֱ������������(WT)����������(TC)����ǿ����(ET)��Dice sore��Hausdorff���롢���жȺ�����ȵ��������������ָ��Ķ�������:Dice?(P,T)=�OP1��T1�O(�OP1�O+�OT1�O)/2Sensitivity (P,T)=�OP1��T1�O�OT1�OSpecificity?(P,T)=�OP0��T0�O�OT0�OHaus?(P,T)=max?{sup?p��?P1inf?t��?T1d(p,t),sup?t��?T1inf?p��?P1d(t,p)}\begin{aligned} &\operatorname{Dice}(P, T)=\frac{\left|P_{1} \wedge T_{1}\right|}{\left(\left|P_{1}\right|+\left|T_{1}\right|\right) / 2}\\ &\text { Sensitivity }(P, T)=\frac{\left|P_{1} \wedge T_{1}\right|}{\left|T_{1}\right|}\\ &\operatorname{Specificity}(P, T)=\frac{\left|P_{0} \wedge T_{0}\right|}{\left|T_{0}\right|}\\ &\operatorname{Haus}(P, T)=\max \left\{\sup _{p \in \partial P_{1}} \inf _{t \in \partial T_{1}} d(p, t), \sup _{t \in \partial T_{1}} \inf _{p \in \partial P_{1}} d(t, p)\right\} \end{aligned} ?Dice(P,T)=(�OP1?�O+�OT1?�O)/2�OP1?��T1?�O? Sensitivity (P,T)=�OT1?�O�OP1?��T1?�O?Specificity(P,T)=�OT0?�O�OP0?��T0?�O?Haus(P,T)=max{ p��?P1?sup?t��?T1?inf?d(p,t),t��?T1?sup?p��?P1?inf?d(t,p)}?
- ���� PPP�����㷨��Ԥ��ͼ, TTT ����ר���ֶ��ָ����ʵֵ��label). ��\wedge�� �������, �O?�O|\cdot|�O?�O �������������ص�����, P1,F0P_{1}, F_{0}P1?,F0?�ֱ����Ԥ��ͼ�����������Լ���������, T1,T0T_{1}, T_{0}T1?,T0? �ֱ������ʵ��ǩ�е���ֵ��ֵ��, d(p,t)d(p, t)d(p,t) ����������p��t֮��ľ��� p,t.?P1p, t . \partial P_{1}p,t.?P1? ��Ԥ�⼯ P1P_{1}P1? �ı��棬?T1\partial T_{1}?T1? ����ʵ��ǩ�� T1T_{1}T1?�ı���.
- ���ܽ��
- ��1�г���ѵ��������֤���ϵ�ƽ�����������������ֵ��ǣ�������Щ������Ѷȵ�������WT,TC,ET��diceϴ�����������ǰ��ս������еġ����ڹ���ϵĴ��ڣ�ѵ��������֤��֮�����С�IJ�ࡣ
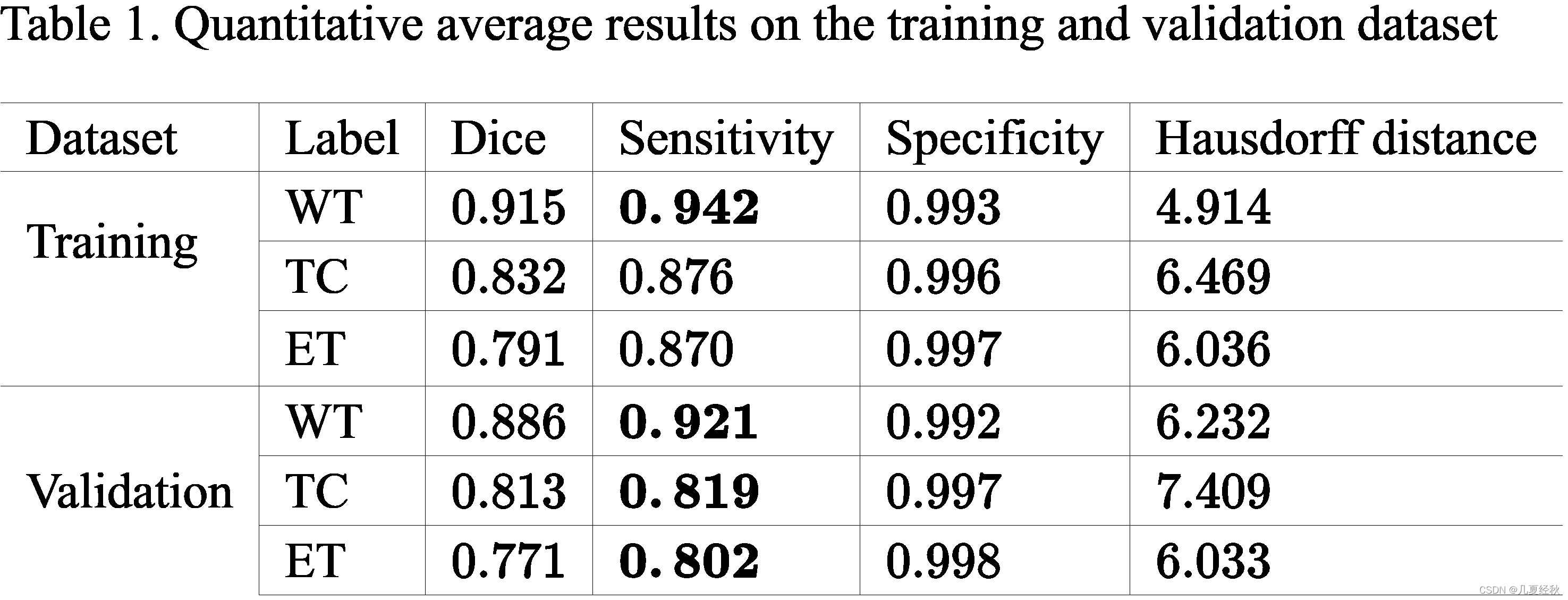
- ��1�г���ѵ��������֤���ϵ�ƽ�����������������ֵ��ǣ�������Щ������Ѷȵ�������WT,TC,ET��diceϴ�����������ǰ��ս������еġ����ڹ���ϵĴ��ڣ�ѵ��������֤��֮�����С�IJ�ࡣ
- �����㷨������
- Ϊ�˸��õķ�������㷨���������ܣ����ǽ����е���֤����ѵ����������� ����ͼ4��ʾ����Ȼ���÷������Ժܺõطָ��������ݼ��еļ����������������������Ⱥ�㡣
- ���⣬ͨ���Ƚ���֤���ݼ���ѵ�����ݼ��ĺ�ͼ������ע���֤���ݼ�������ϵ�������жȡ�����Ⱥ�Hausdorff���������ָ��ķ������ѵ�����ݼ��ķ������ζ�����ǵķ�����һ���̶�����Ȼ���ڹ�������⡣
- ����ĸ���ͼ�����ǿ��Կ���������ѵ������֤���ݼ�����������������ϵ���ķ��С���������ĺ���ǿ�������ǽṹ���������жȺ�Hausdorff�����������ͬ�ģ������������Զ������෴�ģ���������ǵ�Ԥ�ڡ�
- Ȼ�����������Ǿ��ȵ��ǣ��������������ݼ����ڴ����ָ���ϣ���������(TC)�ķ��������ǿ��������(ET)�ķ������ܵĽ�����������ʱ���ܵ�LGG����������Ӱ��������Ԥ������������Ϊ�������ģ���ʹ�÷�������ӡ�
- ����Ŀ��ӻ�
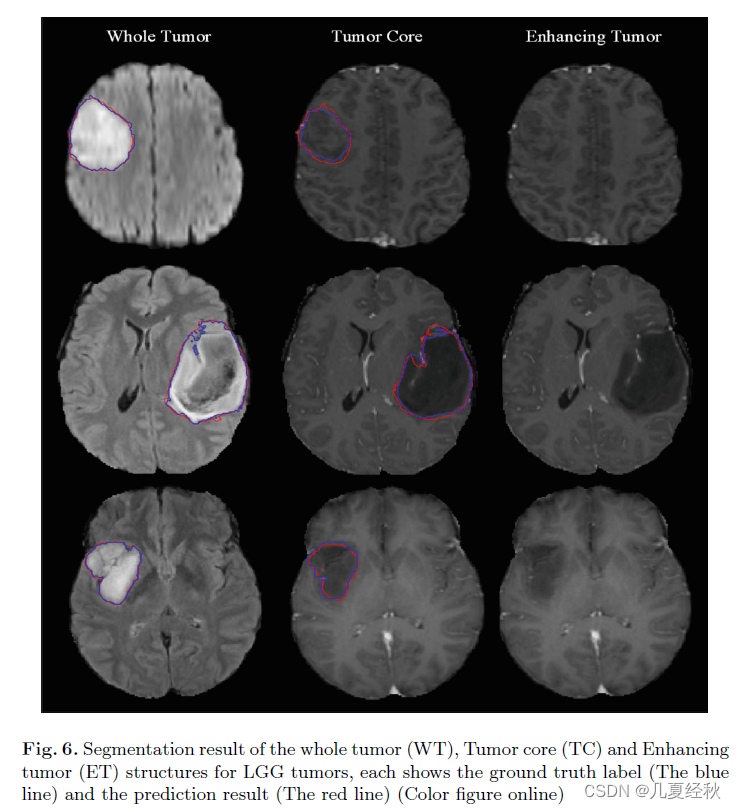
- ��HGG��LGG�����ķָ���Ҳ�����˶��Է������ֱ��ͼ5��ͼ6��
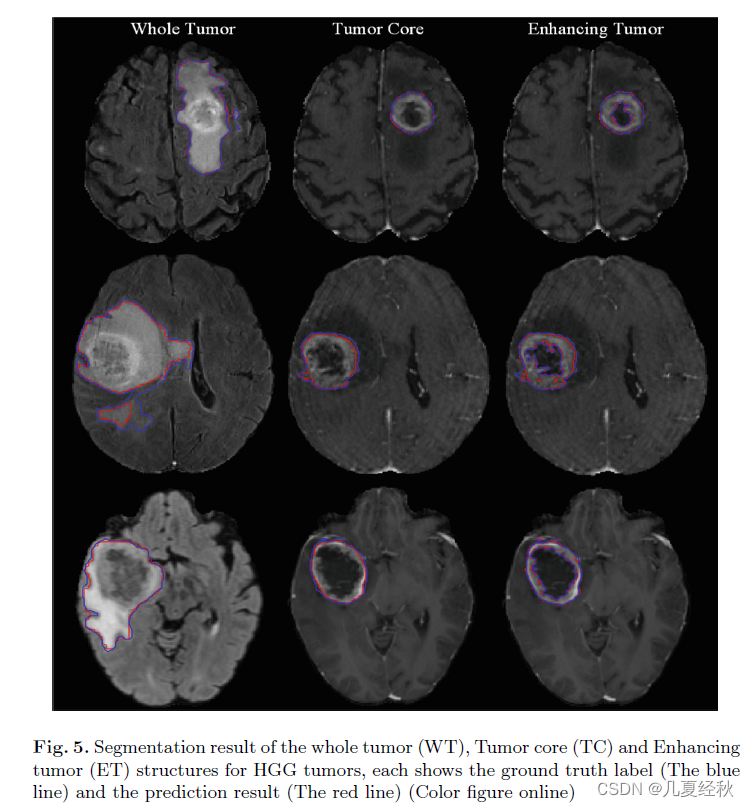
- ������FLAIRģʽͼ����ʾ��������������ʵ�����Ԥ�������ֱ�����ɫ�ͺ�ɫ������ʾ����WT��
- �м�һ���ǰ����������Ļ��������Ԥ������T1ce��̬ͼ������ʾ��ʽ��������ͬ��(TC)
- ��Ȼ���ұߵ���һ�ż�����ʣ�µ��ӽṹ�ϣ���ǿ����������(ET)
- ������ӻ����ܽ�
- ����һЩСϸ���⣬���������������ش��ٴ�����������ܺõطָ��˳�����
- ������֣�����ǰ��������������ѶȵIJ²���Դӿ��ӻ�������ٴεõ���֤��
- �����˵���ӵ�һ�����������������ø������ѣ���Ϊ�����������Χ����֮��ĶԱȶȽ��ͣ�ͬʱ�ָ���ӽṹ������ø��Ӵֲڡ�
- ��HGG��LGG�����ķָ���Ҳ�����˶��Է������ֱ��ͼ5��ͼ6��
4. Disussing and Conclusion
-
����һ�¿��ӻ��ķ���
- ͨ�����ӻ�������֤��������Ƿ�����Ȥ���ǣ�������������Ĵ��������ָ������Щ��������������Ϊ������������IJ�����
- ����ܵĽ��Ϳ����Ǿ���ģʽ��ͬ����ͬ MRI ����֮��IJ��졣��ˣ������ѵ������֮ǰ��ȡ��һЩ���Լ�����Щ�仯��Ԥ����������������ܻ����ӣ�����ֱ��ͼ���⡣
-
����һ��ѵ�������ϵ��ܽ�
- ���⣬���ǻ���������ѵ����������Ƕ˵���ѵ���Ŀγ�ѧϰ���ԣ������������ȶ˵���ѵ����Ч���á�
- ��ܿ�������Ϊ��������е����в��������Ը��£�������Ը��õ����ѵ�����ݡ�
- ������dz��ԶԼ������������������м�Ȩ�����˾��ȵ��ǣ����Ƿ������ս������ѵ���������������������Ȩ�ض�û��̫����졣
-
����ȫ�Ľ����ܽ�
- ��֮�����������һ���dz���Ч�Ķಽ�������ָ����е������ӽṹ��
- ��������Ϊÿ������ѡ���ض���ģ̬����ʹ�Զ��ָ�����벸�鶯��Э�鱣��һ�£���ʹ������ģ̬�ķ�����ȣ�������������ǵĽ����
- ֮������ʹ�� N4 ƫ�ó�У����һ���������������Ԥ������
- �����ڴ����ƣ����Ǵ�ԭʼ����������ü�����鲢����Щ��������������ǿ�����Ƿ���������ǿ���ڼ��ٹ�����Ϸdz���Ҫ����������ѵ������ϡȱʱ��
- ���ѵ�������ڶಽ�����н���ѵ�������ѱ�֤���ȵ����������Ч����Ϊ���Դֵ�ϸ�ķ�ʽѵ�����粢�����ֵĶ���������Ϊ�������������Ʒ������⡣������ BraTS 2019 ��֤���ݼ���������������ķ���������������ǵķ��������������ӽṹ�϶��������á�
-
�����ܽ�
- ���ĵĶಽ������ʵ����һ�ֻ�������ķָ���ԣ���ʵĿ����Ҫ�ǽ�����ָ�תΪ���2��ָ����⣬������һ���̶�����������ľ��ȣ��������ֶಽ�����ķ�ʽ������ϴ���Դ������Լ�����ѵ������������������ȼල˼����и���ѵ��������ѵ���ɱ�ƫ�ߣ����Գ��Բ���һ�϶�ĵ�һ������иĽ���
- ͬʱ�������ݲ�û�в���ȫ����ģ̬���ݣ���Ŀǰ�۲쵽����T1���ݲ����ܴ������Ͽ��������������ָ��к�Ӱ�죬�������Գ���������T1���ݿ���Ч���Ƿ����á�