提示:自己理解总结,学习存档,仅供参考,如有问题,欢迎指出探讨。
代码: 文章代码
文章目录
- 一、背景
- 二、贡献
- 三、模型
-
- 特征提取器:
- Deep Prototypical Network:
- Incremental Few-shot Prototypical Network:
- Triplet Loss for IncreProtoNet:
- 四、实验
- 四、创新点
一、背景
-
传统监督和远监督RC模型都是一个封闭世界的假设(查询实例中表示的关系必须出现在预定义的关系集中),忽略了在开放环境中出现的新关系。
-
为了逐步识别新关系,目前设计了两种解决方案,即再训练和终身学习(当新关系的训练数据不足时,它们容易对新关系过度拟合,甚至可能导致对基础关系 (即之前预定义的关系)的灾难性遗忘)。
- 再训练:每次新关系出现时,我们都需要收集针对新关系的训练数据,然后在增强后的训练数据上从零开始训练,以避免灾难性的遗忘。
- 终身学习:模型(Wang et al.,2019;Han et al.,2020)提出缓解昂贵的再训练过程。然而,这两种解决方案都缺乏针对新关系的大规模训练数据。如果没有足够的新关系训练数据,上述两种解决方案在识别新关系时都存在过拟合的风险,甚至会导致基关系的灾难性遗忘。
-
原型网络在引入新关系时,仍然存在不兼容的特征嵌入问题。
-
提出了一种具有原型注意对齐和三元组丢失的两阶段原型网络,在不发生灾难性遗忘的情况下,在少量支持实例的情况下动态识别新关系。
-
RC模型不仅可以从大规模的训练数据中学习基本的关系,而且可以在很少的支持实例下动态识别新关系。对这一课题的研究可以称为增量少镜头关系分类。
-
在使用原型网络时,当新关系进入时,新关系的特征空间分布可能被扭曲,与基础关系的特征空间分布不相容。

-
如图1所示,基本关系在特征嵌入空间中得到了很好的区分。然而,随着新关系的出现,新关系的特征空间分布比基本关系的特征空间分布极为广泛,甚至与基本关系的空间分布重叠。同时对基本关系和新关系进行分类是不可行的。
-
为了解决这一不兼容的特征嵌入问题,在模型中设计了原型注意对齐和三重组丢失函数。其目的是迫使原型网络缩小新关系的特征空间分布,同时扩大不同关系在同一嵌入空间中的距离。
-
增量学习在图像领域有应用,但是与图像不同,文本更加多样化和嘈杂。很难直接推广到自然语言处理应用
二、贡献
- 探讨了增量式少样本关系分类问题,提出了一种两阶段原型网络模型,在不发生灾难性遗忘的情况下,在少量支持数据的情况下动态识别新关系。第一个专注于增量的少量关系分类的研究。
- 设计了一个注意对齐和三元组丢失的原型网络,解决了目前原型网络中存在的不兼容特征嵌入问题。
三、模型

第一阶段: 提出了一个深度原型网络,以监督学习的方式学习基本关系的特征嵌入空间。每个基本关系表示为其训练实例的中心(基本原型)。(旨在以深度监督的方式预先训练基础关系的基础模型)
目标: 学习一个好的特征提取器和一个好的基分类器。
第二阶段: 第二阶段提出了一种带有新原型生成器的增量式原型网络,并通过比较查询实例与每个原型(即基础原型和新原型)之间的距离进行分类(该网络在只需要少量支持实例的情况下动态识别新关系,同时不忘记基本关系)。
问题定义:

特征提取器:
token embedding: word embedding+pos embedding 最后每个实例被表示成一个矩阵
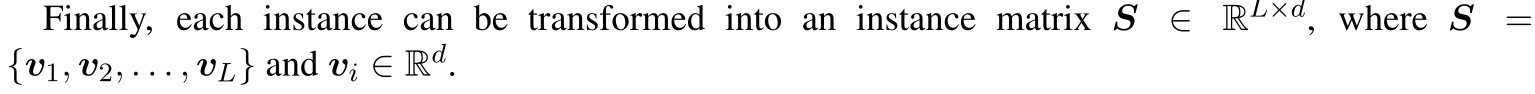
instance encoder:CNNs
Deep Prototypical Network:

- 欧式距离
- 深度原型网络的参数在第一阶段学习,在预训练后会被冻结
- 原型通过计算一个类所有实例的均值实现
Incremental Few-shot Prototypical Network:
- 为了在支持样本较少的情况下动态识别新关系,提出了增量式原型网络来学习新关系的特征并测量新关系的原型(新原型)。
- 然后,通过测量查询实例与所有关系原型(即基础原型和新原型)之间的距离进行分类。
- 第二阶段主要由两个部分组成,包括用MetaCNN编码器测量新原型的新原型生成器和合并原型网络,该网络通过原型注意对齐来合并基础特征和新特征。
Novel Prototype Generator:
- word embedding: 使用第一阶段冻结的参数的网络 encoder部分使用 MetaCNN
- Encoder:不使用第一阶段冻结参数的encoder网络,metaCNN网络结构与基本模型中使用的实例编码器层相同
Feature Averaging Prototype:
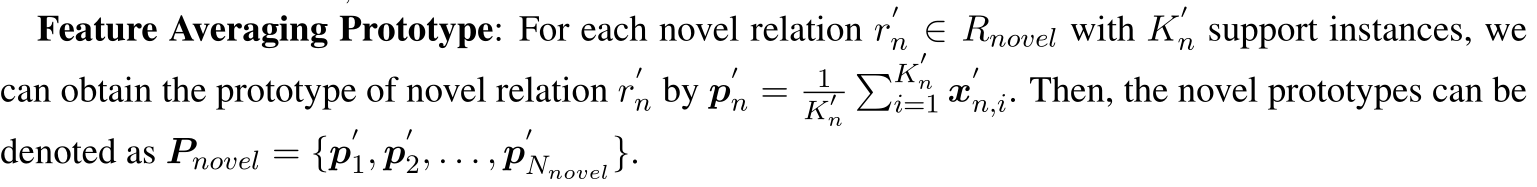
使用每个新类的支持集实例的平均作为原型
Merged Prototypical Network with Prototype Attention Alignment:

给一个查询实例,用两个encoder编码

vbase 和 vnovel 分别为基特征表示和新特征表示,计算方法如下:



Triplet Loss for IncreProtoNet:
- 原型网络的性能高度依赖于关系在嵌入空间中的空间分布。为了提高原型网络的鲁棒性,进一步解决不相容特征嵌入问题,在模型中采用了三元组损失函数。
- 具体来说,triple loss的目标是迫使原型网络缩小新关系的特征空间分布,同时扩大不同关系之间的距离。追随Fan等(2019),triple损失函数设计如下:
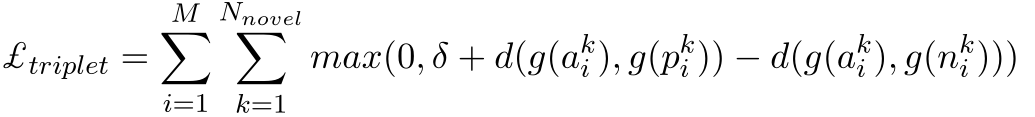
两个损失函数按比例相加
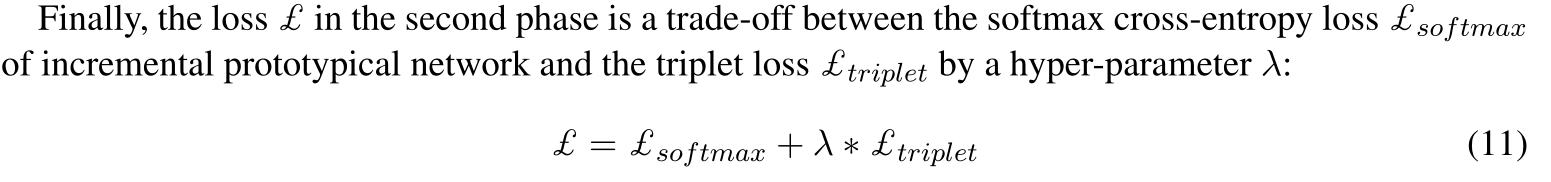
四、实验
实验设置: 预训练模型 Glove和BERT
nbase: 54个

以上结果是通过抽样2000个任务,每个任务有54个基本关系和5个新关系计算得出的。每个关系都是随机抽样的5个查询实例。
基线:少样本RC模型和为图形分类设计的增量模型
- ProtoNet(incremental):基线关系和新关系都是计算原型,测试实例通过计算距离分类
数据集设置:
一共80个关系,每个关系700个实例
-
训练集:54个关系,每个关系 550个实例
-
验证集:54个关系,每个关系50个实例
-
验证阶段新关系:10个关系,每个关系700个实例
-
测试集:54个关系,每个关系100个实例。16个新关系,每个关系700个实例
!训练,验证和测试之间没有重叠实例

消融实验:
- DeepProtoNet:编码器用相同的
- 第二行:没有原型注意对齐
- 第三行:没有triple loss函数

四、创新点
- 提出少样本RC增量学习
提示:简单梳理文章,用于自存,很多地方没有展开写,请见谅,欢迎批评指正讨论。