摘要
对话系统具有在对话期间表达特定情感的能力是值得期待的,这对系统的可用性和用户满意度的提高具有直接的、量化的影响。在仔细调查了现实生活中的对话数据后,我们发现用语言表达情感至少有两种方式。一种是通过使用强烈的情感词来显性地描述情感状态,另一种是通过以不同的方式含组合中性词来隐性地增加情感体验的强度。我们提出了一个情感对话系统(EmoDS),它可以为输入生成连贯且有有意义的回复,同时在一个统一的框架内显式或隐式地表达期望的情感。实验结果表明,EmoDS在BLEU、多样性和情感表达质量三个方面的表现均优于基线。
1 介绍
人类有独特的能力来感知复杂、细微的情感,也有独特的能力用语言互相交流经历。虽然最近的研究(Partala和Surakka,2004;Prendinger和Ishizuka,2005)提供了许多证据表明,能够表达情感的系统显著提高了用户满意度,但使对话系统在回复中更具情感化仍然是一个巨大的挑战。
在早期代表性的工作(Polzin和Waibel,2000;Skowron,2010)中,人工准备的规则被应用于从对话语料库中有意地选择所需要的“情感”回复。这些规则是由有专业知识的人在仔细调查语料库后编写的,这使得表达复杂、多样的情感变得困难,也很难很好地扩展到大型数据集。
最近,使用循环神经网络(RNNs)的序列到序列(Seq2seq)学习框架由于其具有跨越任意时间滞后的能力已成功地用于构建会话代理(也称为聊天机器人)。这样的框架也试图解决聊天机器人中的情感表达问题,周等人(2018年)将其称为情感聊天机(ECM)。然而,作者报告说,ECM倾向于表达训练样本比其他情感多得多的情感类别(比如“喜悦”或“中性”),尽管它被明确要求表达另一种情绪(例如“愤怒”)。它面临着探索属于某一情感范畴的压倒性样本的问题。
语言在情感中扮演着重要的角色,因为它提供在给定的语境中用来表达感觉意义的概念性知识。如表1所示,我们发现至少有两种方法可以将情感转化为语言。一种是描述情感状态(如“愤怒”、“厌恶”、“满足”、“喜悦”、“悲伤”等),通过显式使用与该类别相关的强烈情感词汇。二是增加情感体验的强度,不是通过使用情感词汇中的词语,而是通过以不同的方式隐式地组合中性词语。

在这项研究中,我们提出了一种情感对话系统(EmoDS),它能够以显性或隐性的方式将特定的情感融入具有连贯结构的词语中。seq2seq框架已经扩展了基于词典的注意力机制,该机制鼓励用情感词典中的同义词替换回复中的单词。回复生成过程由序列级情感分类器指导,不仅增加了情感表达的强度,而且有助于识别不包含任何情感词的情感句子。我们还提出了一种半监督的方法来创建情感词典,该词典相对“准确”地表示了人类准备体验和感知的情感状态。自动评估和人工评估的实验结果表明,对于给定的输入和情感类别,我们的EmoDS可以显式(如果可能)或隐式(如果必要)地表达期望情感,同时成功地生成连贯且有意义的回复。
2 相关工作
先前的研究已经报道,对话系统能够在其回复中做出适当的情感表达,可以直接提高用户的满意度(Prendinger和Ishizuka,2005),并在决策和解决问题方面带来改进(Partala和Surakka,2004)。已经投入了一些努力,通过模仿情感表达,使对话系统变得更“人性化”。在早期的代表工作中(Polzin和Waibel,2000;Skowron,2010),人工准备的规则被用来从对话语料库中选择与特定情感相关的回复。这些规则需要由训练有素的专家编写,这使得它很难扩展到处理复杂、细微的情感,特别是对于大型语料库。
循环神经网络(RNNs)及其在序列到序列框架中的应用已经被证明在机器翻译、文本摘要、图像标题生成等结构化预测中是相当成功的。该框架还被应用于构建聊天机器人,旨在模拟人类作为交互代理的行为方式。在通过seq2seq框架开发聊天机器人的早期尝试中,已经做了很多努力来避免在它们的回复中生成无意义的句子(例如“告诉我更多”和“继续”)。
最近,人们很少注意产生具有特定性质的回复,如情绪、时态或情感。Hu等人(2017)提出了一个基于变分自动编码器(VAEs)的文本生成模型,以生成表示给定情感或时态的句子。Ghosh等人(2017)提出了一个基于RNN的语言模型,根据情感类别生成情感句子。这项研究只关注文本生成,而不是对话。周和王(2018)首先收集了大量推特对话语料库,包括表情符号(电子消息中使用的表意文字和笑脸),然后通过尝试几种条件VAE变体,使用表情符号在生成的文本中表达情感。
周等人(2018)提出了一种基于seq2seq框架的情感聊天机(ECM),这与本研究更密切相关。他们以嵌入的形式将情感因素从文本中解脱出来。当ECM被要求在回复中表达特定情感时,机器计算相应的情感嵌入,直到这种嵌入的每个元素变回零。外部情感词典也被用来帮助回复的生成。ECM倾向于表达具有最多训练样本的情感类别,尽管它被特别要求表达另一个情感类别。这种偏差可能是由于随着训练的进行,情绪嵌入之间的差异逐渐模糊的潜在趋势造成的。我们使用情感分类器来指导回复生成过程,从而确保在生成的回复中恰当地表达特定的情感。据我们所知,这项研究是首批建造能够以显性(如果可能)或隐性(必要时)方式表达特定情感的交互式机器。
3 方法
在这一部分中,我们描述了EmoDS,它可以以显性或隐形方式产生具有连贯结构的情感回复。seq2seq框架利用基于词典的注意机制进行了扩展,以插入所需的情感词。序列级情感分类器同时帮助识别没有任何情感词的情感语句。还提出了一种多样化的解码算法,以促进回复生成中的多样性。此外,我们还提出了一种半监督的方法来生成能够正确表示情感状态的心理感知的情感词典。
3.1 问题定义
问题表述如下:给定输入X={x1,x2,.,xm}和情感类别e,目标是生成回复Y={y1,y2,.,yn},该回复不仅内容有意义,而且符合期望的情感,其中Xi∈V和YJ∈V是输入和回复中的词。M和N分别表示输入和回复的长度。![]() 是一个由普通词汇Vg和情感词汇Ve组成的词汇表。要求
是一个由普通词汇Vg和情感词汇Ve组成的词汇表。要求![]() 词典Ve还可以被分成几个子集
词典Ve还可以被分成几个子集![]() ,每个子集存储与情感类别z相关联的单词。我们在表2中列出了一个带有不同情感回复的示例。
,每个子集存储与情感类别z相关联的单词。我们在表2中列出了一个带有不同情感回复的示例。

3.2 基于词汇注意力机制的对话系统
EmoDS基于首次为神经机器翻译引入的seq2seq框架。一种基于词典的注意力机制(Bahdanau等人,2014年)也被应用于在正确的时间步骤将情感词无缝地“插入”到生成的文本中。EmoDS的体系结构如图1所示。

具体地说,我们使用双向长短期记忆网络(LSTM)作为编码器来转换输入,x={x1,x2,.,xm},转换为其矢量表示。形式上,编码器的隐藏状态计算如下:

其中i=1,2,.,M,![]() 和
和![]() 分别是前向和后向LSTM的第i个隐藏状态。
分别是前向和后向LSTM的第i个隐藏状态。![]() 是xi的词嵌入,d是词嵌入的维数。我们将前向和后向LSTM对应的隐藏状态连接起来,即
是xi的词嵌入,d是词嵌入的维数。我们将前向和后向LSTM对应的隐藏状态连接起来,即![]() ,作为这两个LSTM产生的第i个隐藏状态。最后的隐状态hm作为其初始化被馈送到解码器。
,作为这两个LSTM产生的第i个隐藏状态。最后的隐状态hm作为其初始化被馈送到解码器。
解码器模块包含了基于词典的注意机制增强的单独的LSTM。LSTM解码器将先前预测的词yj?1和情感矢量ej作为输入以更新其隐状态Sj,如下所示:
![]()
其中j=1,2,.,N,s0=hm。Emb(yj?1)是yj?1的词嵌入,[·;·]表示用分号分隔的特征向量的连接操作。情感矢量ej为给定类别z的![]() 中词嵌入的加权和计算所得:
中词嵌入的加权和计算所得:

其中![]() 表示
表示![]() 中的第k个词,Tz是情感类别z的词数,α,β和γ是可训练参数。我们使用Luong等人提出的全局注意力模型来计算注意力分数。对于
中的第k个词,Tz是情感类别z的词数,α,β和γ是可训练参数。我们使用Luong等人提出的全局注意力模型来计算注意力分数。对于![]() 中每个情感词
中每个情感词![]() ,在时间步长j的注意力分数ajk由三个部分确定:解码器的先前隐状态Sj?1,输入的编码表示hm,以及
,在时间步长j的注意力分数ajk由三个部分确定:解码器的先前隐状态Sj?1,输入的编码表示hm,以及![]() 中第k个单词的嵌入
中第k个单词的嵌入![]() 。因此,给定部分生成的回复和输入,情感词越相关,它对当前时间步长的情感特征向量的影响就越大。这样,基于词汇的注意力会给当前语境更相关的情感词更高的概率。
。因此,给定部分生成的回复和输入,情感词越相关,它对当前时间步长的情感特征向量的影响就越大。这样,基于词汇的注意力会给当前语境更相关的情感词更高的概率。
为了将情感词插入到回复中,对于给定的情感类型z,我们估计![]() 中的所有情感词we的概率分布Pe(Yj=we),和Vg中所有通用词wg的概率分布Pg(yj=wg),如下:
中的所有情感词we的概率分布Pe(Yj=we),和Vg中所有通用词wg的概率分布Pg(yj=wg),如下:

其中δj∈(0,1)是控制生成情感或通用词的权重的类型选择器,而We、Wg和υ是可训练的参数。基于词汇的注意力机制有助于在正确的时间步长将期望的情感词放入回复中,这使得在生成的文本中表达预期的情感成为可能。通过最小化交叉熵误差来定义每个样本的损失函数,其中目标分布t是具有除基本事实之外的所有元素为零的二进制向量:
![]()
3.3 情感分类
感觉可以通过显式地使用与特定类别相关的强烈情感词表达,或者通过以不同的方式将中性词组合到一个序列中来隐式地表达。因此,我们使用序列级情感分类器来指导生成过程,这有助于识别表达某种情感但不包含任何情感词的回复。引入这种分类器的一种直接方法是构建句子级情感鉴别器,如下所示:
![]()
其中W∈Rk×d是权重矩阵,K表示情感类别的数量。然而,枚举所有可能的序列是不可行的,因为搜索空间与词汇表的大小成指数关系,并且Y的长度事先是未知的。此外,如果按照概率抽样较少的序列来近似生成过程,则是不可微的。
遵循Koˇcisk‘y(2016)等人的观点,我们使用期望词嵌入的思想来近似Q(E|Y)。具体地说,期望词嵌入是在每个时间步长的所有可能词嵌入的加权和:
![]()
其中,在每个时间步长j,我们枚举Vg和![]() 的并集中的所有可能的词。每个样例的分类损失定义为:
的并集中的所有可能的词。每个样例的分类损失定义为:
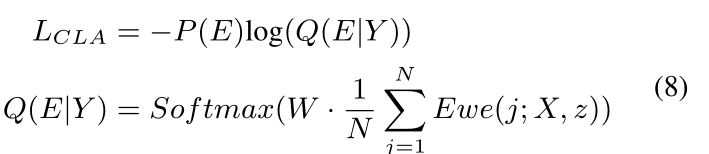
其中P(E)是表示实例的期望情感分布的独热向量。
引入的情感分类器不仅增加了情感表达的强度,而且有助于识别不含任何情感词的情感回复。请注意,情感分类器仅在训练过程中使用,可以作为情感表达的全局指导。
3.4 训练目标
总体训练目标分为两部分:生成损失和分类,可写为:
![]()
其中超参数λ管理生成损失与分类项相比的相对重要性。生成损失LMCE确保解码器可以产生具有连贯且有意义的回复,而情感分类项指导生成过程,保证在生成的回复中适当地表达特定的情感。
3.5 多样化编码算法
Li等人(2016c)发现传统集束搜索产生的N个最佳结果中的大多数都非常相似,因此我们提出了一种多样化的解码算法来促进回复生成的多样性。我们强制N个候选的中心词应该是不同的,然后在确定这些中心词之后,模型继续通过贪婪解码策略生成回复。最后,我们从最好的N个候选中选择情感得分最高的回复。候选由在自动标注的数据集上预先训练的情感分类器评分(参见4.1节)。因此,我们的模型可以产生具有更好的多样性的N个最佳候选,其中情感得分最高的作为最终结果。
3.6 情感词库构建
在这一部分中,我们描述了如何从由带有情感类别的句子组成的语料库中,以半监督的方式构建所需的情感词典。词义根据许多不同的两极形容词等级进行评级。例如,等级的范围可能从“强”到“弱”。我们只收集每个情感类别中被评为“强”的词,并将其放入情感词典中。
受Vo和Zhang(2016)的启发,每个单词都表示为w=(pw,nw),对于情感类别(例,“快乐”),其中pw表示被分配给该类别的概率,而nw表示相反的概率。给定一个句子s,该句子s是n个单词的序列,预估的情感概率被简单地计算为![]()
![]()
如果句子s表示情感,则将其标记为二维情感向量z=(1,0);如果不是,z=(0,1)。每个词由小的随机值初始化,并通过最小化![]() 的交叉熵误差进行训练。其中m是语料库中的句子数。
的交叉熵误差进行训练。其中m是语料库中的句子数。
我们删除句子中的所有停用词,并将识别的“数字”、“电子邮件”、“URL”、“日期”和“外来词”映射为特殊符号。否定后面的词被转换成(?Pw,?Nw),然后再用它们来产生句子的情感向量。如果单词被最高级或比较级形容词(或副词)修饰,则用于更新其表示的学习率值将相应地变为双倍或三倍。训练过程可以分为两个阶段。在第一阶段,采用标准的反向传播。当预测精度大于给定阈值(例如90%)时,第二阶段开始使用最大边际学习策略,直到收敛。训练停止后,我们计算平均值![]() 及其方差σ。词的值为
及其方差σ。词的值为![]() 大于某一阈值将被识别为情感词。
大于某一阈值将被识别为情感词。
4 实验
4.1 数据准备
由于没有大规模现成的情感会话数据,因此我们在短文本会话(STC)数据集的基础上构建了自己的实验数据集。追随周(2018)等人的研,我们首先在NLPCC数据集上训练情感分类器然后用这个分类器标注了STC数据集。更具体地说,我们在NLPCC数据集上训练了一个双向LSTM(Bi-LSTM)分类器用于情感分类,与其他分类器相比(周等人,2018年),它达到了最高的分类精度。表4显示了几种基于神经网络的分类器的精度。

NLPCC数据集由NLPCC2013和NLPCC2014中的情感分类数据组成。这个数据集中有八种情绪类别,包括愤怒(7.9%)、厌恶(11.9%)、满足(11.4%)、喜悦(19.1%)、悲伤(11.7%)、恐惧(1.5%)、惊讶(3.3%)和中立(33.2%)。除去不常见的类别(恐惧和惊讶)后,我们最终得到了六种情绪类别:愤怒、厌恶、满足、快乐、悲伤和中性。接下来,我们使用训练良好的Bi-LSTM分类器对STC数据集进行了6个情感标签的标注,从而得到了标注了情感的对话数据集。最后,我们将带情感标签的STC数据集随机分成训练/验证/测试集,比例为9:0.5:0.5。详细的统计数字如表3所示。

4.2 训练细节
我们用TensorFlow实现EmoDS。具体地说,我们将一层双向LSTM用于编码器,另一层单向LSTM用于解码,在编码器和解码器中都将LSTM隐状态的大小设置为256。将单词嵌入的维度设置为100,并使用Glove嵌入对其进行初始化。大量的实验结果表明,这种预训练的词表示可以增强各种自然语言处理任务上的监督模型。通用词汇表建立在最频繁的3万个单词上,每个类别的情感词典由我们的半监督方法构建,大小设为200。剩下的所有单词都被一个特殊的令牌<unk>所取代。通过[?3.0/n,3.0/n]内的均匀分布随机初始化参数,其中n表示参数的维度。多样化解码的大小设置为20。我们调整了{1e-1,1e-2,1e-3,1e-4}中唯一的超参数λ,发现1e-2效果最好。
我们采用小批量随机梯度下降(SGD)(Robbins and Monro,1985)算法进行优化。小批次大小和学习率分别设置为64和0.5。我们运行了20个epoch,训练阶段在Titan X GPU卡上大约花了5个小时。我们的代码很快就会发布。
4.3 基准模型
我们进行了广泛的实验,将EmoDS与以下具有代表性的基线进行比较:(1)Seq2Seq:我们实现了与Vinyals和Le(2015)中一样的Seq2Seq模型;(2)EmoEmb:受Li等人(2016b)的启发,我们将每个情感类别表示为一个向量,并在每个时间步长将其反馈给解码器。我们称之为情感嵌入对话系统(EmoEmb)。(3)ECM:我们使用了周等人(2018)发布的代码实现ECM。
此外,为了更好地分析模型中不同组件的影响,我们还进行了以下消融试验:(4)EmoDSMLE:EmoDS只针对MLE目标进行优化,没有情感分类项。(5)EmoDS-EV:EmoDS使用外部情绪词典,而不是生成内部情绪词典。6)EmoDS-BS:EmoDS采用原始集束搜索,而不是我们的多样化解码。
4.4 自动评估
4.4.1 指标
我们使用以下指标来评估我们的EmoDS的性能:(1)嵌入得分:我们采用了三个基于嵌入的指标(平均、贪婪和极端),将回复映射到向量空间,并计算余弦相似度。基于嵌入的指标可以在很大程度上捕捉生成的响应与基本事实之间的语义级相似性。(2)BLEU得分:BLEU(Papineni等人,2002年)是一种流行的度量标准,它计算生成的回答相对于标准回答的单词重叠分数。本文中的BLEU指的是默认的BLEU4。(3)多样性:DISTINCT-1/DISTINCT-2分别是不同单字/双字在所有生成的符号中所占的比例。多样性指标用来评估回复的多样性。(4)情感评测:我们设计了两个基于情感的度量标准,emotion-a和emotion-w,来测试情感在生成的回复中的表达情况。emotion-a是在数据准备过程中通过Bi-LSTM分类器预测的标签与真实标签之间的一致性。Emotion-w是包含相应情感词的生成回复的百分比。
4.4.2 结果
结果如表5所示。

上半部分是所有基线模型的结果,我们可以看到EmoDS在所有情况下都优于竞争对手。值得注意的是,与EmoEmb和ECM相比,EmoDS在emotion-a和emotion-w方面取得了显著的改善,表明我们的EmoDS可以产生具有更好的情感表达能力de 连贯的回复。Seq2Seq模型在几乎所有指标上都表现得相当差,主要是因为它没有考虑任何情感因素,而且往往会产生简短的一般性反应。同时以显性和隐性方式表达情感的能力使EmoDS产生更多的情感反应。
表5的下半部分显示了消融实验的结果。可见,去掉情感分类项(EmoDS-MLE)后,性能下降最为明显。我们的解释是,在没有情感分类项的情况下,该模型只能在生成的回复中显式地表达期望的情感,而不能捕获不包含任何情感词的情感序列。使用外部情感词典(EmoDS-EV)也会导致性能下降,尤其是在emotion-w上。这是说得通的,因为外部情感词典与语料库共享的单词较少,导致生成过程将重点放在通用词汇上,并生成更多常见的回复。另外,在使用原始集束搜索(EmoDS-BS)时,DISTINCT-1/DISTINCT-2的下降幅度最大,这表明多样化解码可以促进回复生成的多样性。
4.5 人工评估
4.5.1 评估设定
遵循(周等人,2018年)中定义的协议,我们采用了从内容和情感水平设计的人工评估方法,以更好地理解生成的回复的质量。首先,从测试集中随机抽取了200个输入,对于每个输入,除了Seq2Seq之外,所有的模型都为六个情感类别产生了六个回答。取而代之的是,Seq2Seq模型在每个输入的BEAM搜索中生成了前6个回复。然后,(输入、回复、情感)的三元组被秩序被打乱呈现给三名人类评委。他们用3个量表评分(0,1,2)从内容层面评估每个反应,用2个量表评分(0,1)评估情感水平。从内容级别进行评估是评估回复上下文来说是否连贯且有意义。从情感层面进行的评估决定了回复是否显示了所需的情感属性。
计算了Fleiss‘s kappa(Fleiss and Cohen,1973)来衡量三个评分者直接一致性。最后,内容和情感的Fleiss‘s kappa分别为0.513和0.811,分别表示“适度认同”和“非常认同”。
4.5.2 结果
表6显示EmoDS在大多数情况下实现了最高性能(Sign Test,p值<0.05)。

具体地说,在内容连贯性方面,大多数模型之间没有明显的差异,但在情感表达方面,EmoDS产生了显著的性能提升。正如我们从表6中看到的,EmoDS在所有类别上都表现良好,总体情绪得分为0.608,而EmoEmb和ECM在训练数据较少的类别上表现不佳,例如厌恶、愤怒和悲伤。注意,Seq2Seq的所有情感得分都是最低的,这表明Seq2Seq在产生回复时不善于表达情感。综上所述,由于EmoDS能够显式或隐式地表达所需的情感,因此EmoDS可以产生具有更好的情感表达的有意义的回复。
为了更好地分析在内容和情感级别生成的回复的总体质量,我们还在表7中报告了内容和情感得分的组合分布。

结果表明,在EmoDS生成的回复中,31.7%的回复被标注为内容得分为2,情感得分为1,高于其他三种模型。这表明EmoDS在内容和情感方面都更善于产生高质量的回复。此外,偏好测试的结果如表8所示。

可以看出,EmoDS明显优于其他模型(Sign Test,p值<0.05)。显然,我们的EmoDS产生的各种情感回复比Seq2Seq产生的普通回复对用户更有吸引力。
4.6 案例研究
为了深入了解情感在生成的回复中的表达情况,我们在表9中提供了一些示例。

它表明,EmoDS可以通过将特定的情感以显性或隐性的方式放入词语中,产生具有任何所需情感的有意义的回复。例如,“难看(ugly)”是一个强烈的情感词,用来明确描述厌恶的情感状态,而“好/想/去/看看/.(I really want to see the scenery.)”中的词都是中性的,但它们的组合可以表达满足的情感状态。
5 结论
鉴于情感状态可以通过显式使用强情感词或以不同模式形成中性词来用语言表达,我们提出了一种新颖的情感对话系统(EmoDS),它可以用任何一种方式表达期望的情感,同时产生连贯且有意义的回复。序列到序列的框架扩展了基于词典的注意力机制,它通过在正确的时间步长增加情感词的概率来无缝地将情感词“插入”到文本中。情感分类器还用于指导回复生成过程,以确保特定的情感在生成的文本中得到适当的表达。据我们所知,这项研究是首批建造能够以显性(如果可能)或隐性(必要时)方式表达特定情绪的互动性机器。自动评测和人工评测的实验结果表明,EmoDS在BLEU、情感表达的多样性和情感表达质量上都明显优于基线,突出了所提出的体系结构在实用对话系统中的潜力。