以下文字为博主翻译并添加了自己的理解,斜体为博主自己的想法,若有出错请指出。
摘要
暗光图像增强需要同时有效地处理颜色、亮度、对比度、伪影和噪声等多种因素。本文提出了一种新颖的注意力引导增强方案,并在此基础上构建了 端到端多分支(multi-branches) CNN。该方法的关键是计算两个注意力图来分别指导曝光增强和去噪任务。第一个注意力图区分曝光不足的区域和光照较好的区域,而第二个注意力图区分噪音和真实纹理。本论文的方法还能增强暗光图像缺失的对比度。论文还提出了一种创建合成暗光图像的数据集的方法。
Introduction
暗光图像质量退化严重,相比正常曝光图像,细节丢失严重,颜色失真,噪点多,对于现实中的高级视觉任务性能有严重影响。基于HE(直方图均衡)的方法和基于RETINEX的传统方法都不能很好地解决暗光增强的问题,而且这些方法常常忽视去噪。
在之前的研究中,有先去噪,再增强的流程;也有先增强,再去噪的流程。但是前者导致图像变得模糊,后者会放大噪点。而本文的方法,将增强和去噪同时进行,能够有效地避免以上问题。
本文最主要的贡献列为三点:
- 设计了注意力图为引导的多分支融合网络,能够同时进行去噪和增强
- 设计了一套高质量的暗光图像训练流程,创建了一个大规模的成对的合成的暗光图像数据集
- 研究成果表明,方法达到了SOTA
related work
- 一些基于HE(直方图均衡)的方法单纯扩大了图片的动态范围,但是并没有考虑光照因素,只是关注图片的对比度,会导致增强过多或者增强不足的问题。
- 一些传统的基于RETINEX的方法,依赖人工调整参数,同时噪声处理方面不尽人意。
- 一些基于现有深度学习(deep learning)的方法,已经在性能上相比传统方法提升很多,但是很多没有仍旧没有考虑去噪,或者依赖的是传统方法的去噪,这与本文不同,本文特别考虑了去噪这一任务,这是对现有基于深度学习方法的重要补充。
- 本文还介绍了一些现今流行的去噪方法,同时指出只有同时进行增强和去噪,才能最好地提升图片质量,避免模糊等情况发生。
datasets
作者在一些已有的大型数据集中,以darkness estimation、blur estimation和color estimation三个指标来选择一些符合要求的高质量图像,这些图像一部分中的965张,作为测试集和ground truth,并使用包含22656张图像的数据平衡子集(data-balanced subset)作为训练集。
然后,作者通过线性伽马变换,将正常曝光图像有效地、近似的合成为暗光图像,之后对训练集进行gamma线性变换得到合成的暗光图像,同时模拟相机处理图像程序,利用高斯泊松混合模型生成噪声,得到最终的合成的有噪声的成对的暗光训练集。详细方法请见论文。
值得一提的是,如果单纯使用高质量的图像作为GT来回归,得到的输出图像对比度会降低,具体参见:MBLLEN:Low-light ImageVideo Enhancement Using CNNs,所以作者提出要使用多分支的融合方式来增强图像,恢复其对比度。
我自己感觉,本文的多分支融合,实际上类似通道加权,将学习到的特征全都考虑进去。
methodology
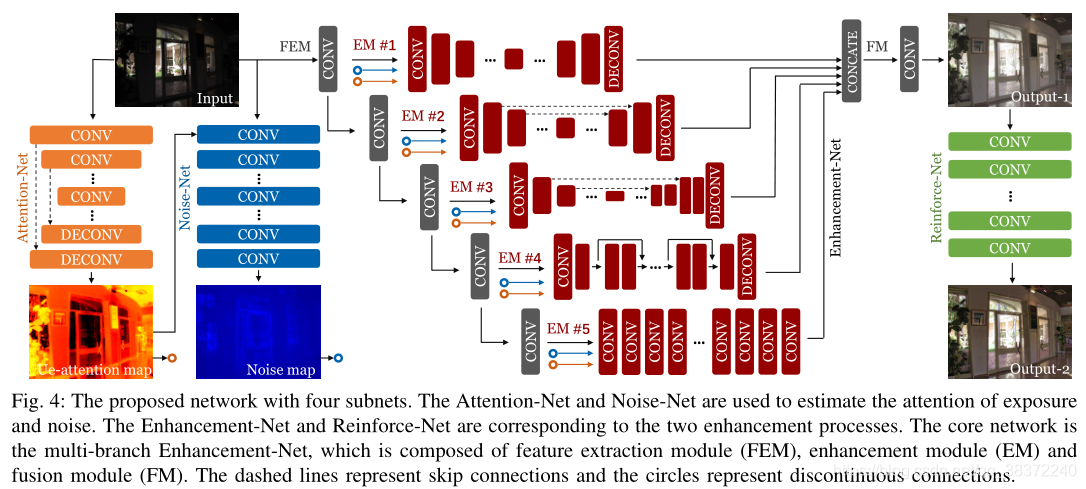
论文设计了四大模块:Attention-Net,Noise-Net,Enhancement-Net以及Reinforce-Net
-
Attention-Net
输入为原始暗光图像,采用U-Net结构,输出一张ue-attention map(ue:underexposed),其数值越高,代表区域越亮,反之亦然,范围在[0,1]。
结构如论文图4左小角,计算如下:
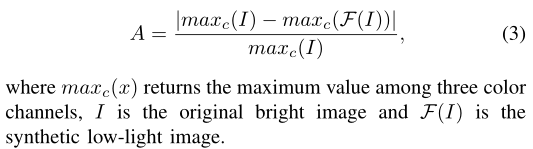
另外,论文还指出,ue-attention map实际有点类似RETINEX理论中illumination map,相同的是两者都能指出光照亮度信息。不同的是作者称,反向的ue-attention map的信息质量比illumination map更高,因为illumination map在感知图像中大量黑色的区域会将噪音放大。
如下图:

p.s. 作者这里提出ue-attention map和illumination map的对比非常聪明和科学,因为暗光增强任务中的一大经典且有效的理论就是RETINEX理论,如果能直观地、科学地表明自己的方法更加优秀,则增加了作者方法的科学可信度。
p.s. 为什么是反向的ue-attention map,因为正的ue-attention maps是越亮数值越低,与illumination map相反 -
Noise-Net
作者称,图像噪点应该是和亮度分布息息相关的,所以注意力机制的ue-attention map可以更好地指导如何进行去噪;同时Noise-Net由dilated convolutional layers(膨胀卷积)构成,增大了感受野,有利于噪声估计。增大感受野,有点类似关注全局content信息。
输入是ue-attention map,输入为noise map。 -
Enhancement-Net
实际上这里的Enhancement-Net,与MBLLEN非常相似,毕竟本论文就是MBLLEN的升级版。
部分为论文核心结构,分为特征提取模块FEM(feature extraction module)、增强模块EM(enhancement module) 和 融合模块(fusion module)。
原始暗光图像作为input送入带relu的几个直连conv layers组成的FEM后,得到的特征图与之前得到的ue-attention map,noise-map一同作为输入送进EM模块中;同时上一层得到的特征图,作为下一层的FEM的输入。
另外,每一层的EM模块都不相同,EM-1是一组具有较大核尺寸的卷积/反卷积层;EM-2和EM-3具有类似U-Net的结构,不同之处在于skip connection的实现和特征图的大小;EM-4具有网状结构,论文中去掉了BN批归一化,只使用了几个re块来减少模型参数;EM-5由输出尺寸与输入尺寸相同的膨胀卷积层组成。值得一提的是,EM网络中并不共享网络参数!
得到多张不同的EM输出最终进入FM层中,在这里所有EM输出在color channel上进行concat,并用1*1的卷积将其进行融合得到对比度未被增强的输出。 -
Reinforce-Net
使用膨胀卷积,将Enhancement-Net的输出进行进一步对比度增强,得到最终的增强图像。
loss function
总loss为四个网络结构的loss结合而成:
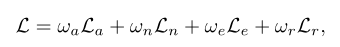
权重分别为{100,10,10,1}
- ** Attention-Net loss**
输入为原始低光图像,计算 L2 loss:
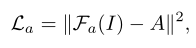
- Noise-Net loss
输入为ue-attention map,计算 L1 loss:
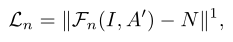
- Enhancement-Net loss
作者称,单纯使用MSE,MAE等通用loss,会导致模糊和伪影,所以这里专门设计了一系列loss来限制:
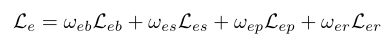
从左到右分别为bright loss、structure loss、perceptual loss和regional loss,权重分别为{1,1,0.35,5} -
- bright loss可以保证图像拥有足够的亮度,
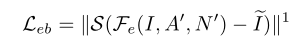
- bright loss可以保证图像拥有足够的亮度,
-
- structural loss用来保证图像结构的完整并且防止模糊,使用的是SSIM(结构相似度)方法来创建loss,
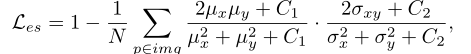
- structural loss用来保证图像结构的完整并且防止模糊,使用的是SSIM(结构相似度)方法来创建loss,
-
- perceptual loss可以提升增强图像的视觉质量,使用已经预训好的VGG19(第三个block中第四个卷积层的输出)作为perceptual loss提取层,来比较高层信息中的一致性
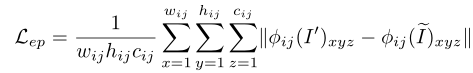
- perceptual loss可以提升增强图像的视觉质量,使用已经预训好的VGG19(第三个block中第四个卷积层的输出)作为perceptual loss提取层,来比较高层信息中的一致性
-
- regional loss用来平衡暗光区域和正常曝光区域的增强强度,
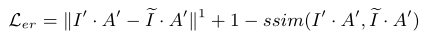
ssim()代表计算SSIM值
- regional loss用来平衡暗光区域和正常曝光区域的增强强度,
- Reinforce-Net loss
类似Enhancement-Net loss,
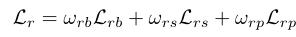
从左到右分别为bright loss、structure loss和perceptual loss,权重为{1,1,0.35}
p.s. 具体loss符号代表含义与实施细节请参考论文
Experimental Evaluation
论文使用了图像增强中常用的PSNR(峰值信噪比) 和 SSIM(结构相似性作为图像质量测试指标,同时还加入了平均亮度Average Brightness (AB) , 视觉信息保真度Visual Information Fidelity (VIF) ,亮度循序误差Lightness Order Error (LOE) ,色调映射图像质量指数Tone Mapped Image Quality Index (TMQI) 和 感知图像块相似性度量Learned Perceptual Image Patch Similarity Metric (LPIPS)。
p.s. 在其他工作中,用的最多也就是PSNR和SSIM两个,我这是第一次见到测试了这么多指标的
论文基于自创建的合成数据集和两个公开可用的真实微光数据集(LOL,SID)进行定性和定量的比较,还进行了现实自然图片的实验。
1. 自创建的合成数据集的实验
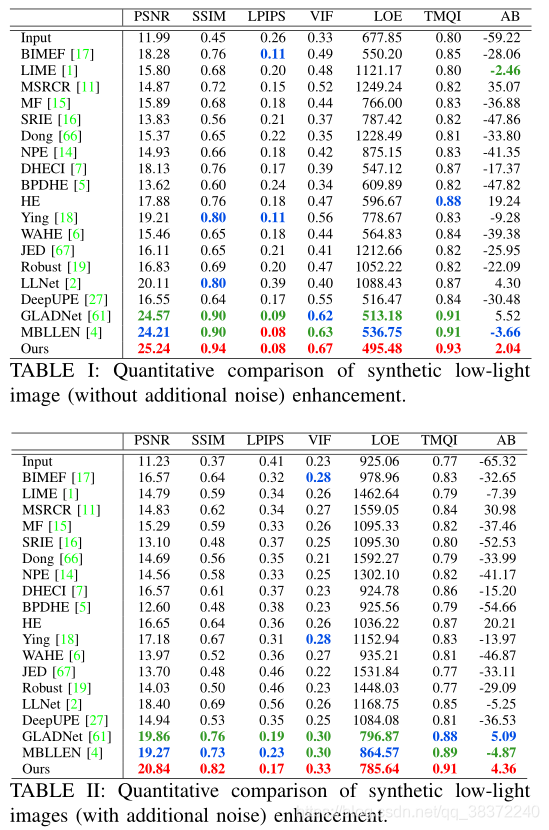
论文称,之前大多数方法没有去噪功能,所以通过给那些没有去噪的方法加入CBDnet去噪,再进行比较。分为不添加噪声和额外添加噪声两个实验,在两个实验中论文的方法都取得了最好的成绩。红色最好,绿色第二,蓝色第三。

论文还称,好的网络不仅增强结果质量优秀,网络效率也非常重要,所以做了值得学习训练速度与结果质量的直角坐标对比图,直观、清晰地展示方法的优势,这样的做图方法值得学习:
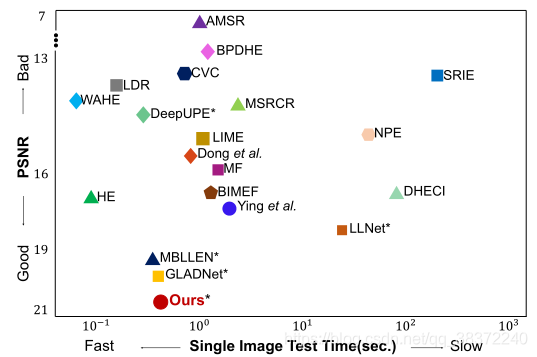
2. 现实数据集的实验
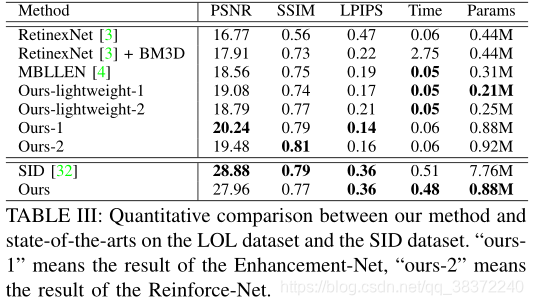
通过在LOL数据集上与RetinexNet的对比实验、在SID上的控制变量改变网络结构(单纯使用论文的Enhancement-Net或Reinforce-Net),证明了论文的方法具有更好的性能。

3. 现实自然图片的实验
现实自然图片就是现实中随便取的图片,
在这种数据上得到优秀的增强结果能够证明网络的泛化性更强,实验证明相比其他方法,论文的方法在对比度、颜色保真和色彩饱和度上具有更好的表现。

4. 观者调查
论文还进行了用户调查,论文的方法有最多的第一排名的选票,第三方来证明论文方法能够输出高质量的输出图像。

5. 泛化研究
为证明论文的鲁棒性和有效性,论文在一些特定领域,例如单色监控、游戏夜景中进行了实验,同时证明了对于如目标检测、实例分割也能提高其网络性能(用在预处理阶段)。
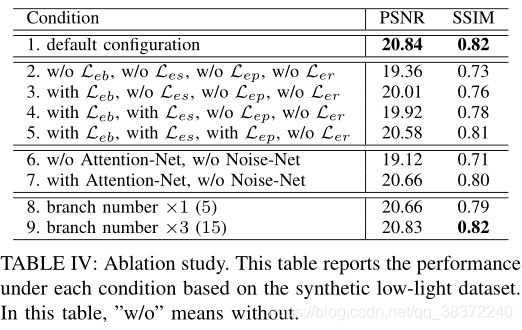
6. 消融实验
论文做了loss function、network structure和numbers of branches的消融实验。
证明了设计的loss确实对性能有提升;证明了使用Attention-Net能够提升质量;证明了并不是分支branches越多或者越少最好,选取为10时效果最好。
博主总结
- 注意力机制ue-attention map可以指导网络正确地有的放矢地进行提亮和去噪
- Enhancement-Net中的多分支融合机制,因为不共享网络参数,有点类似加权学习,能够关注到原有图像不同层次的信息
- 在Noise-Net和Reinforce-Net中使用了一般用在语义分割上的膨胀卷积(也称空洞卷积)。因为增大了感受野,能够关注到比较全面的信息
- 设计了一种创建合成低光图像数据集的方法
- 在多类型的数据上,设计了非常多且全面的实验,很多实验方法和做图技巧都可以进行参考,用在自己的工作中
- low light enhance最关注的的是什么?是噪点、颜色失真和模糊等等指标。论文针对这些最关注的点专门设计网络,并设计实验来验证,同时在论文中表述的非常清楚。例如文中说到以前的增强方法很少关注去噪,而本文专门设计了Attention-Net和Noise-Net来解决这些问题,并通过控制变量的是否额外增加噪点的实验来验证。
- 善用控制变量法进行实验,如是否添加额外噪声的实验以及单独拿出Enhancement-Net与其他方法对比的实验