应用场景
新闻推荐
提出背景
- 新闻因具有实时性因而不适用于传统的CF技术推荐。DKN[2018]中,物品通过新闻标题和知识图谱中对应实体和实体上下文表示,用户通过用户历史推荐序列进行表示,但是新闻标题可能是语义模糊的,历史行为可能是数据稀疏的。
- GNN在推荐系统中的应用越来越多,目前GNN模型利用节点属性和图结构来表示用户和物品,虽然利用节点关系,视觉特征,知识图谱中传播信号增强了语义信息,但是文本内容却没有充分利用。
本文贡献
- 我们利用transformer结构对新闻标题的文本内容进行建模,通过文本意识的新闻表示来提高了节点嵌入。
- 引入GERL,Graph EnhancedRepresentation Learning (GERL)。
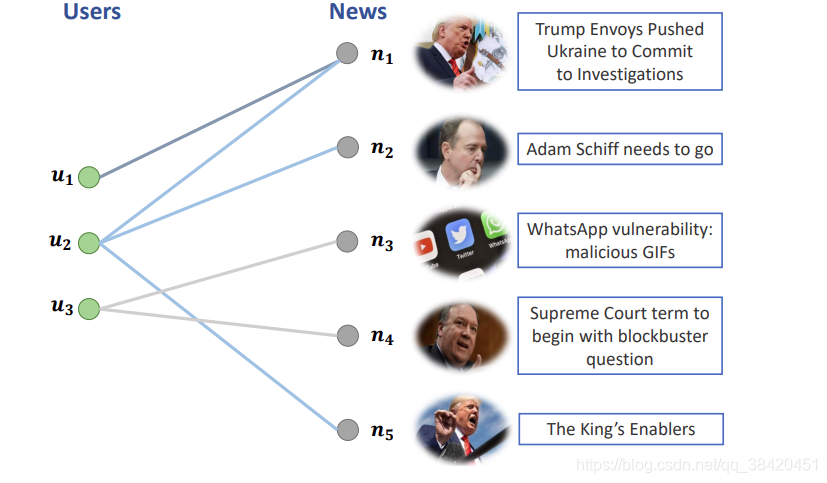
如图所示是用户-物品二部图,定义如下概念:
- 邻居新闻:被同一用户浏览过的新闻
- 邻居用户:浏览过同一新闻的用户
- 新闻可以通过邻居新闻增强表示
- 用户可以通过邻居用户增强表示
基础架构
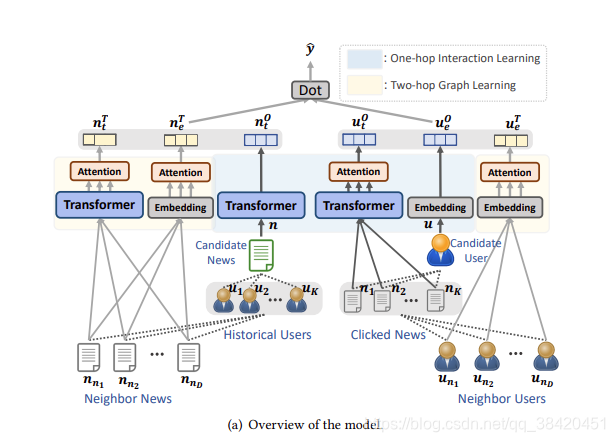
模型由两部分组成,第一部分是one hop交互,依据用户历史点击来表示用户和基于文本内容表示候选新闻;第二部分是two hop graph learning方法,通过学习知识图谱中邻居节点来增强用户物品表示。
Transformer for Context Understanding
- 将新闻标题嵌入到低维空间
[e1,e2,…,eM]\left[\mathbf{e}_{1}, \mathbf{e}_{2}, \ldots, \mathbf{e}_{M}\right] [e1?,e2?,…,eM?] - multi-head self-attention network,单词之间的交互对于表示学习是重要的,采用多头自注意力机制形成文本的单词向量表示
- αi,jk=exp?(eiTWskej)∑m=1Mexp?(eiTWskem)hik=Wvk(∑j=1Mαi,jkej)\begin{aligned} \alpha_{i, j}^{k} &=\frac{\exp \left(\mathbf{e}_{i}^{T} \mathbf{W}_{s}^{k} \mathbf{e}_{j}\right)}{\sum_{m=1}^{M} \exp \left(\mathbf{e}_{i}^{T} \mathbf{W}_{s}^{k} \mathbf{e}_{m}\right)} \\ & \mathbf{h}_{i}^{k}=\mathbf{W}_{v}^{k}\left(\sum_{j=1}^{M} \alpha_{i, j}^{k} \mathbf{e}_{j}\right) \end{aligned} αi,jk??=∑m=1M?exp(eiT?Wsk?em?)exp(eiT?Wsk?ej?)?hik?=Wvk?(j=1∑M?αi,jk?ej?)?
Wsk\mathbf{W}_{s}^{k}Wsk? and Wvk\mathbf{W}_{v}^{k}Wvk?是第k个自注意力头的投影矩阵,αi,jk\alpha_{i, j}^{k}αi,jk?表示第i和j单词之间的相关性,第i个单词的多头表示为[hi1;hi2;…;hiN]\left[\mathbf{h}_{i}^{1} ; \mathbf{h}_{i}^{2} ; \ldots ; \mathbf{h}_{i}^{N}\right][hi1?;hi2?;…;hiN?] - 通过dropout层防止过拟合
- 通过一个attention网络对不同单词的重要性进行建模
βiw=exp?(qwTtanh?(Uw×hi+uw))∑j=1Mexp?(qwTtanh?(Uw×hj+uw))\beta_{i}^{w}=\frac{\exp \left(\mathbf{q}_{w}^{T} \tanh \left(\mathrm{U}_{w} \times \mathbf{h}_{i}+\mathbf{u}_{w}\right)\right)}{\sum_{j=1}^{M} \exp \left(\mathbf{q}_{w}^{T} \tanh \left(\mathbf{U}_{w} \times \mathbf{h}_{j}+\mathbf{u}_{w}\right)\right)} βiw?=∑j=1M?exp(qwT?tanh(Uw?×hj?+uw?))exp(qwT?tanh(Uw?×hi?+uw?))? - 新闻的话题也可以揭示用户的偏好,所以对话题通过一个嵌入网络进行建模,得到vp\bold {v_p}vp?,最终得到新闻的表示为
v=[vt;vp]\mathbf{v}=\left[\mathbf{v}_{t} ; \mathbf{v}_{p}\right]v=[vt?;vp?]

One-hop Interaction Learning
候选新闻语义表示
候选新闻采用transformer建模表示。
目标用户语义表示
目标用户的偏好可以通过历史点击揭示,因此,对用户历史点击的新闻的内容进行建模,不同的新闻重要度不同,采用一个注意力网络,假设用户u的历史点击新闻列表为[n1,n2,…,nK]\left[n_{1}, n_{2}, \ldots, n_{K}\right][n1?,n2?,…,nK?],经过transformer后编码为[v1,v2,…,vK]\left[\mathbf{v}_{1}, \mathbf{v}_{2}, \ldots, \mathbf{v}_{K}\right][v1?,v2?,…,vK?],注意力网络权重表示为
βin=exp?(qnTtanh?(Un×vi+un))∑q=1Kexp?(qnTtanh?(Un×vq+un))\beta_{i}^{n}=\frac{\exp \left(\mathbf{q}_{n}^{T} \tanh \left(\mathbf{U}_{n} \times \mathbf{v}_{i}+\mathbf{u}_{n}\right)\right)}{\sum_{q=1}^{K} \exp \left(\mathbf{q}_{n}^{T} \tanh \left(\mathbf{U}_{n} \times \mathbf{v}_{q}+\mathbf{u}_{n}\right)\right)} βin?=∑q=1K?exp(qnT?tanh(Un?×vq?+un?))exp(qnT?tanh(Un?×vi?+un?))?
目标用户ID表示
用户IDs代表独一无二的用户,我们为每一个用户学习一个向量ueO\mathbf{u}_{e}^{O}ueO?
Two-hop Graph Learning
该模块主要利用二部图中的用户邻居和物品邻居关系,对于一个用户,他和他的邻居用户有相似的偏好;新闻也是如此。
目标用户的邻居用户ID表示
目标用户u的邻居用户为[un1,un2,…,unD]\left[u_{n_{1}}, u_{n_{2}}, \ldots, u_{n_{D}}\right][un1??,un2??,…,unD??],ID嵌入为[mu1,mu2,…,muD]\left[\mathbf{m}_{u_{1}}, \mathbf{m}_{u_{2}}, \ldots, \mathbf{m}_{u_{D}}\right][mu1??,mu2??,…,muD??],注意力权重为
βiu=exp?(quTtanh?(Uu×mui+uu))∑q=1Dexp?(quTtanh?(Uu×muq+uu))\beta_{i}^{u}=\frac{\exp \left(\mathbf{q}_{u}^{T} \tanh \left(\mathbf{U}_{u} \times \mathbf{m}_{u_{i}}+\mathbf{u}_{u}\right)\right)}{\sum_{q=1}^{D} \exp \left(\mathbf{q}_{u}^{T} \tanh \left(\mathbf{U}_{u} \times \mathbf{m}_{u_{q}}+\mathbf{u}_{u}\right)\right)} βiu?=∑q=1D?exp(quT?tanh(Uu?×muq??+uu?))exp(quT?tanh(Uu?×mui??+uu?))?
最终two-hop邻居用户ID示为
ueT=Σi=1Dβiumui\mathbf{u}_{e}^{T}=\Sigma_{i=1}^{D} \beta_{i}^{u} \mathbf{m}_{u_{i}} ueT?=Σi=1D?βiu?mui??
候选新闻的邻居新闻ID表示
候选新闻n的邻居新闻为[nn1,nn2,…,nnD]\left[n_{n_{1}}, n_{n_{2}}, \ldots, n_{n_{D}}\right][nn1??,nn2??,…,nnD??],ID嵌入为[mn1,mn2,…,mnD]\left[\mathbf{m}_{n_{1}}, \mathbf{m}_{n_{2}}, \ldots, \mathbf{m}_{n_{D}}\right][mn1??,mn2??,…,mnD??],同上述相同注意力机制,最终获取邻居新闻表示为neT\mathbf{n}_{e}^{T}neT?。
候选新闻的邻居新闻语义表示
利用邻居新闻的文本内容经过transformer,attention建模学习ntT\mathbf{n}_{t}^{T}ntT?。
推荐模块
目标用户用u=[utO;ueO;ueT]\mathbf{u}=\left[\mathbf{u}_{t}^{O} ; \mathbf{u}_{e}^{O} ; \mathbf{u}_{e}^{T}\right]u=[utO?;ueO?;ueT?],候选新闻用n=[ntT;neT;ntO]\mathbf{n}=\left[\mathbf{n}_{t}^{T} ; \mathbf{n}_{e}^{T} ; \mathbf{n}_{t}^{O}\right]n=[ntT?;neT?;ntO?]
评分函数
y^=uTn\hat{y}=\mathbf{u}^{T} \mathbf{n} y^?=uTn
损失函数
L=?∑ilog?(exp?(y^i+)exp?(y^i+)+∑j=1λexp?(y^i,j?))\mathcal{L}=-\sum_{i} \log \left(\frac{\exp \left(\hat{y}_{i}^{+}\right)}{\exp \left(\hat{y}_{i}^{+}\right)+\sum_{j=1}^{\lambda} \exp \left(\hat{y}_{i, j}^{-}\right)}\right) L=?i∑?log(exp(y^?i+?)+∑j=1λ?exp(y^?i,j??)exp(y^?i+?)?)
数据集
MSN News