�Ķ�����֮ǰ�����˽���JAVA�е�BIO,NIO,AIOģ�ͣ����Բο��ҵ�һƪ���ģ�
https://blog.csdn.net/qq_38905818/article/details/100931441
ע�⣺�������۵ı�����Linux�����µ�network IOģ�͡�
IOģʽ
����һ��IO���ʣ���read�����������ݻ��ȱ�����������ϵͳ�ں˵Ļ������У�Ȼ��Ż�Ӳ���ϵͳ�ں˵Ļ�����������Ӧ�ó���ĵ�ַ�ռ䡣����˵����һ��read��������ʱ�����ᾭ�������Σ�
��һ�Σ��ȴ������� (Waiting for the data to be ready)��
�ڶ��Σ������ݴ��ں˿����������� (Copying the data from the kernel to the process)��
����socket�����ԣ�
��һ����ͨ���漰�ȴ������ϵ����ݷ��鵽�Ȼ���Ƶ��ں˵�ij����������
�ڶ����������ݴ��ں˻��������Ƶ�Ӧ�ý��̻�������
����Ӧ����Ҫ�������Ǿ������������⣬����IO�����ݼ��㡣����ں��ߣ�����IO���ӳ٣���Ӧ�ô���������ƿ�����ں��ߡ�����IO��ģ�ʹ��������¼��֣�
ͬ��IO��synchronous IO��
- ����IO��bloking IO��
- ������IO��non-blocking IO��
- ��·����IO��multiplexing IO��
- �ź�����ʽIO��signal-driven IO��
�첽IO��asynchronous IO��
ע������signal driven IO��ʵ���в������ã���������ֻ�ἰʣ�µ�����IO Model��
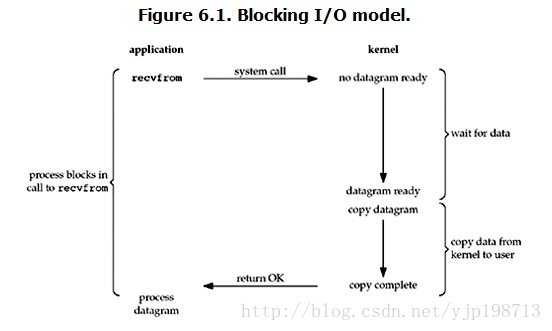
���� I/O��blocking IO��
��linux�У�Ĭ����������е�socket����blocking��һ�����͵Ķ��������̴����������
���û����̵�����recvfrom���ϵͳ���ã�kernel�Ϳ�ʼ��IO�ĵ�һ���Σ������ݣ���������IO��˵���ܶ�ʱ��������һ��ʼ��û�е�����磬��û���յ�һ��������UDP�������ʱ��kernel��Ҫ�ȴ��㹻�����ݵ����������������Ҫ�ȴ���Ҳ����˵���ݱ�����������ϵͳ�ں˵Ļ�����������Ҫһ�����̵ġ������û�������ߣ��������̻ᱻ��������Ȼ���ǽ����Լ�ѡ�������������kernelһֱ�ȵ����������ˣ����ͻὫ���ݴ�kernel�п������û��ڴ棬Ȼ��kernel���ؽ�����û����̲Ž��block��״̬�������������������ԣ�blocking IO���ص������IOִ�е������ζ���block�ˡ�
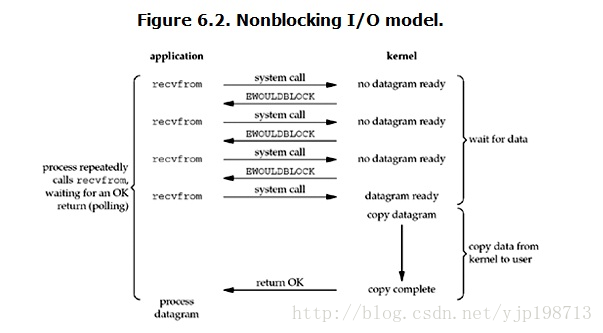
������ I/O��nonblocking IO��
linux�£�����ͨ������socketʹ���Ϊnon-blocking������һ��non-blocking socketִ�ж�����ʱ��������������ӣ�
���û����̷���read����ʱ�����kernel�е����ݻ�û�����ã���ô��������block�û����̣��������̷���һ��error�����û����̽ǶȽ� ��������һ��read����������Ҫ�ȴ����������Ͼ͵õ���һ��������û������жϽ����һ��errorʱ������֪�����ݻ�û�����ã������������ٴη���read������һ��kernel�е����������ˣ��������ٴ��յ����û����̵�system call����ô�����Ͼͽ����ݿ��������û��ڴ棬Ȼ�ء����ԣ�nonblocking IO���ص����û�������Ҫ���ϵ�����ѯ��kernel���ݺ���û�С�
I/O ��·���ã� IO multiplexing��
IO multiplexing��������˵��select��poll��epoll����Щ�ط�Ҳ������IO��ʽΪevent driven IO��select/epoll�ĺô������ڵ���process�Ϳ���ͬʱ��������������ӵ�IO�����Ļ���ԭ������select��poll��epoll���function��ϵ���ѯ�����������socket����ij��socket�����ݵ����ˣ���֪ͨ�û����̡�
���û����̵�����select����ô�������̻ᱻblock����ͬʱ��kernel�ᡰ���ӡ�����select�����socket�����κ�һ��socket�е����������ˣ�select�ͻ᷵�ء����ʱ���û������ٵ���read�����������ݴ�kernel�������û����̡�
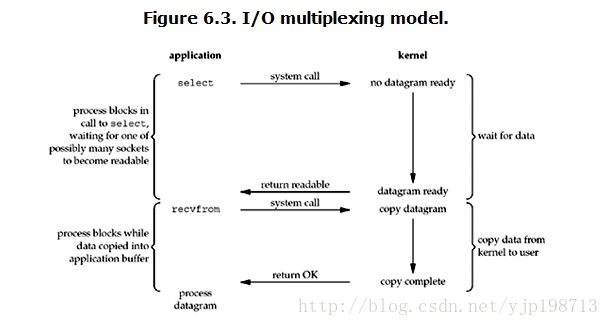
���ԣ�I/O ��·���õ��ص���ͨ��һ�ֻ���һ��������ͬʱ�ȴ�����ļ�������������Щ�ļ������������������������е�����һ�����������״̬��select()�����Ϳ��Է��ء�
���ͼ��blocking IO��ͼ��ʵ��û��̫��IJ�ͬ����ʵ�ϣ�������һЩ����Ϊ������Ҫʹ������system call (select �� recvfrom)����blocking IOֻ������һ��system call (recvfrom)�����ǣ���select����������������ͬʱ�������connection��
���ԣ�������������������ǺܸߵĻ���ʹ��select/epoll��web server��һ����ʹ��multi-threading + blocking IO��web server���ܸ��ã������ӳٻ�����select/epoll�����Ʋ����Ƕ��ڵ��������ܴ����ø��죬���������ܴ�����������ӡ���
��IO multiplexing Model�У�ʵ���У�����ÿһ��socket��һ�㶼���ó�Ϊnon-blocking�����ǣ�����ͼ��ʾ�������û���process��ʵ��һֱ��block�ġ�ֻ����process�DZ�select�������block�������DZ�socket IO��block��
�첽 I/O��asynchronous IO��
linux�µ�asynchronous IO��ʵ�õú��١��ȿ�һ���������̣�
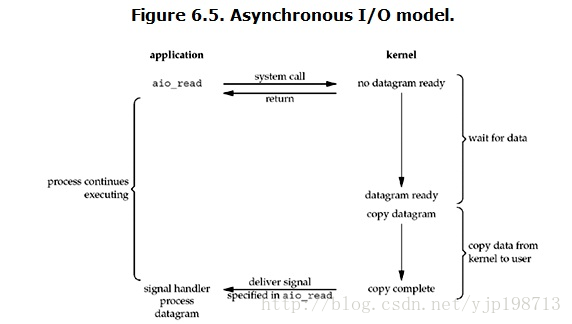
�û����̷���read����֮�����̾Ϳ��Կ�ʼȥ���������¡�����һ���棬��kernel�ĽǶȣ������ܵ�һ��asynchronous read֮�������������̷��أ����Բ�����û����̲����κ�block��Ȼ��kernel��ȴ���������ɣ�Ȼ�����ݿ������û��ڴ棬����һ�ж����֮��kernel����û����̷���һ��signal��������read��������ˡ�
I/O ��·����֮select��poll��epoll
select��poll��epoll����IO��·���õĻ�����I/O��·���þ�ͨ��һ�ֻ��ƣ����Լ��Ӷ����������һ��ij��������������һ���Ƕ���������д���������ܹ�֪ͨ���������Ӧ�Ķ�д��������select��poll��epoll�����϶���ͬ��I/O����Ϊ���Ƕ���Ҫ�ڶ�д�¼��������Լ�������ж�д��Ҳ����˵�����д�����������ģ����첽I/O�������Լ�������ж�д���첽I/O��ʵ�ֻḺ������ݴ��ں˿������û��ռ䡣
���䣺�ļ�������fd
�ļ���������File descriptor���Ǽ������ѧ�е�һ�������һ�����ڱ���ָ���ļ������õij����
�ļ�����������ʽ����һ���Ǹ�������ʵ���ϣ�����һ������ֵ��ָ���ں�Ϊÿһ��������ά���ĸý��̴��ļ��ļ�¼�����������һ�������ļ����ߴ���һ�����ļ�ʱ���ں�����̷���һ���ļ����������ڳ�������У�һЩ�漰�ײ�ij����д������Χ�����ļ�������չ���������ļ���������һ��������ֻ������UNIX��Linux�����IJ���ϵͳ��
select
int select (int n, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);select��������ͨ�����û������fd��־λ�����ݽṹ��������һ��������������������ȱ���ǣ�
1�� �������̿ɼ��ӵ�fd���������ƣ����ܼ����˿ڵĴ�С���ޡ�
һ����˵�����Ŀ��ϵͳ�ڴ��ϵ�ܴ�����Ŀ����cat /proc/sys/fs/file-max�쿴��32λ��Ĭ����1024����64λ��Ĭ����2048.
2�� ��socket����ɨ��ʱ������ɨ�裬��������ѯ�ķ�����Ч�ʽϵͣ�
�����ֱȽ϶��ʱ��ÿ��select()��Ҫͨ������FD_SETSIZE��Socket����ɵ���,�����ĸ�Socket�ǻ�Ծ��,������һ�顣����˷Ѻܶ�CPUʱ�䡣����ܸ�����ע��ij���ص������������ǻ�Ծʱ���Զ������ز������Ǿͱ�������ѯ��������epoll��kqueue���ġ�
3����Ҫά��һ��������Ŵ���fd�����ݽṹ��������ʹ���û��ռ���ں˿ռ��ڴ��ݸýṹʱ���ƿ�����
poll
int poll (struct pollfd *fds, unsigned int nfds, int timeout);poll�����Ϻ�selectû�����������û���������鿽�����ں˿ռ䣬Ȼ���ѯÿ��fd��Ӧ���豸״̬������豸���������豸�ȴ������м���һ������������������������fd��û�з��־����豸�������ǰ���̣�ֱ���豸��������������ʱ�������Ѻ�����Ҫ�ٴα���fd��������̾����˶����ν�ı�����
��û�������������������ԭ�������ǻ����������洢�ģ�����ͬ����һ��ȱ�㣺
1��������fd�����鱻���帴�����û�̬���ں˵�ַ�ռ�֮�䣬�����������ĸ����Dz��������塣
2��poll����һ���ص��ǡ�ˮƽ�����������������fd��û�б���������ô�´�pollʱ���ٴα����fd��
epoll
//����һ��epoll�ľ����size���������ں������������Ŀһ���ж��
int epoll_create(int size)��
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)��
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
epoll����2.6�ں�������ģ���֮ǰ��select��poll����ǿ�汾�������select��poll��˵��epoll������û�����������ơ�epollʹ��һ���ļ�������������������������û���ϵ���ļ����������¼���ŵ��ں˵�һ���¼����У��������û��ռ���ں˿ռ��copyֻ��һ�Ρ�
epoll��EPOLLLT��EPOLLET���ִ���ģʽ��LT��Ĭ�ϵ�ģʽ��ET�ǡ����١�ģʽ��LTģʽ�£�ֻҪ���fd�������ݿɶ���ÿ�� epoll_wait���᷵�������¼��������û�����ȥ����������ET����Ե������ģʽ�У���ֻ����ʾһ�Σ�ֱ���´�������������֮ǰ����������ʾ�ˣ��� ��fd���Ƿ������ݿɶ���������ETģʽ�£�readһ��fd��ʱ��һ��Ҫ������buffer���⣬Ҳ����˵һֱ����read�ķ���ֵС������ֵ������ ����EAGAIN������һ���ص��ǣ�epollʹ�á��¼����ľ���֪ͨ��ʽ��ͨ��epoll_ctlע��fd��һ����fd�������ں˾ͻ��������callback�Ļص������������fd��epoll_wait������յ�֪ͨ��
epoll���ŵ㣺
1��û��������ӵ����ƣ��ܴ�FD������Զ����1024��1G���ڴ����ܼ���Լ10����˿ڣ���
2��Ч��������������ѯ�ķ�ʽ����������FD��Ŀ������Ч���½���ֻ�л�Ծ���õ�FD�Ż����callback������
��Epoll�����ŵ��������ֻ���㡰��Ծ�������ӣ��������������أ������ʵ�ʵ����绷���У�Epoll��Ч�ʾͻ�ԶԶ����select��poll��
�ܽ�
1.java������ʹ��IO��ÿһ�����Ӷ���Ҫһ���������̣߳���java��˵���̣߳�����û��ͨ��ʱ�߳�������
2.selectģʽ��һ���߳̿���Ϊ������ӷ���·���ã���a.�������Ӷ�û�����ݴ���ʱ���߳̽���������������ӣ��ļ�����������������ϵͳ�����������û��ռ临�Ƶ��ں˿ռ䣩���ɲ���ϵͳ���;����������b.��������һ�����������ݴ���ʱ������ϵͳ֪ͨ�̣߳����������ں˿ռ临�Ƶ��û��ռ䣩c.�̱߳����������ӣ��ļ����������ҵ���Ҫ���������ӣ�
2.1.��Ҫȱ�㣺a.�����߳��ܼ�ص����ӣ��ļ�������������Ϊ1024��b.��Ҫά��һ����������������ݽṹ���ں����û��ռ临�ƿ�����c.����������ʱ����ɨ��(��ѯ)��
3.polla.�����select��ȡ����1024���ƣ�������ȱ����Ȼ���ڣ�
4.epolla.ȡ��1024���ƣ�b.Ч��������������ѯ�ķ�ʽ����������FD��Ŀ������Ч���½���ֻ�л�Ծ���õ�FD�Ż����callback������
��Epoll�����ŵ��������ֻ���㡰��Ծ�������ӣ��������������أ������ʵ�ʵ����绷���У�Epoll��Ч�ʾͻ�ԶԶ����select��poll