����С����ͼ��ָ����������������ǿ���磨PFENet��
���ĵ�ַ
Github��Դ����
Ŀǰ���ڵ�����
���е�Few-Shot Segmentation�����ձ���ڵ�������������������õ��µķ�����ʧ�Լ���ѯ������֧������֮��Ŀռ䲻һ�¡�
������
(1)һ������ѵ����������ģ���ɷ���������������ģ�͵ķ������������������ģ�͵����ܡ�
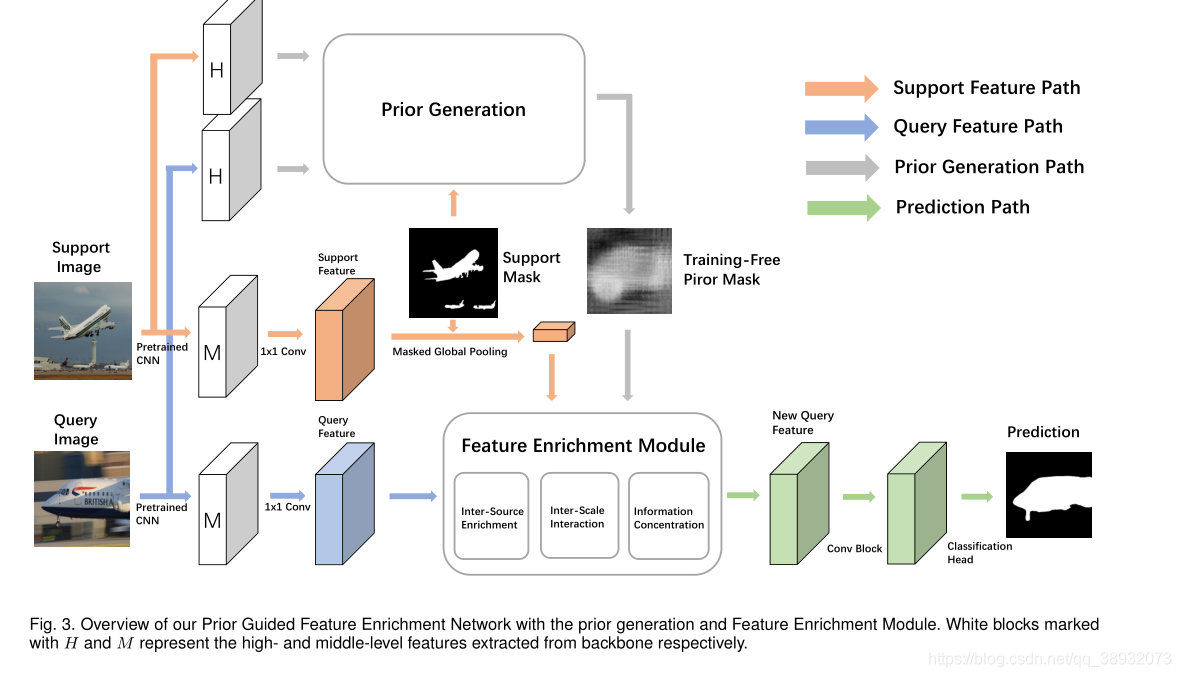
(2)������ǿģ�飬һ��ʹ��֧��������support feature�����������루prior mask��������Ӧ��ǿ��ѯ������query feature���Կ˷��ռ䲻���������ģ�顣
��Ҫ�Ĺ۲죨Ϊ��Ҫʹ��������������
��CANet��ʵ���з����˸߲�����������ResNet50�е�conv5_x���ᵼ�����ձ����½����е����Դ�����Ľ������в��������ָ��õ�ԭ�����ⲿ������unseen classes�������IJ�����ɵģ������������ﲻ���ǹ�����è�����۾����ӣ��������ĸ����Ľ����ǰ����ڸ������е�������Ϣ�Ȱ������м������е�������Ϣ���ض���ij���࣬��������������п��ܶ�ģ�ͶԲ��ɼ���ķ���������������Ӱ��
ֵ��ע����ǣ��뷢�ָ߲��������few shot�ָ�����ܲ�������Ӱ���෴��֮ǰ�ķָ���������Щ����Ϊ����Ԥ���ṩ������������һì�ܴ�ʹ����Ѱ��һ����training-class-insensitive�ķ�ʽ���ø���Ϣ�ķ������������few shot�ָ��е����ܡ�
����
���Ƚ�ImageNet[32]Ԥ��ѵ���İ���������Ϣ�ĸ�����ת��Ϊһ���������룬�����������������Ŀ����ĸ��ʣ���ͼ��

Backbone����ʹ�õ���PANet��CANet�����������
IQI_QIQ?��ʾ����IJ�ѯͼ��ISI_SIS?��ʾ�����֧��ͼ��MSM_SMS?��ʾ��ֵ֧�����룬F\mathcal{F}F��ʾbackbone���磬XQX_QXQ?��XSX_SXS?�ֱ��ʾ�߲��ѯͼ�������߲�֧��ͼ���������й�ʽ���£�
XQ=F(IQ),XS=F(IS)��MSX_Q=\mathcal{F}\left( I_Q \right) ,X_S=\mathcal{F}\left( I_S \right) \odot M_SXQ?=F(IQ?),XS?=F(IS?)��MS?
��\odot����ʾ����Hadamard��������������ͨ����0�ķ�ʽ��֧��ͼ��ı��������Ƴ���
�ٶ���ΪXQX_QXQ?���������YQY_QYQ?�ܹ���ʾXQX_QXQ?��XSX_SXS?֮������ض�Ӧ��ϵ��XQX_QXQ?�о��и�ֵ��������ζ�����������֧������XSX_SXS?��������һ��������֮���и߶�Ӧ�ԡ�������ܿ����ڲ�ѯͼ���Ŀ��������ͨ����֧�������ı�������Ϊ�㣬��ѯ������������֧�������ı���û�ж�Ӧ��ϵ������ֻ��ǰ��Ŀ��������ء�
��λ�ȡ��������YQY_QYQ?������XQX_QXQ?��XSX_SXS?ÿ�����ؼ���������ƶ�cos(xq,xS)cos(x_q,x_S)cos(xq?,xS?)��
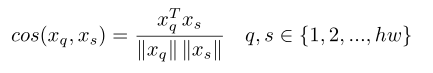
������֧�����ؼ��������ƶ���Ϊ��Ӧֵcqc_qcq?��
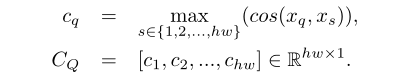
��CQC_QCQ?ת��Ϊh��wh��wh��w����ʽ������������һ���������õ���������YQY_QYQ?
��һ�����Ĺؼ��������ù̶��ĸ����������������룬�Ӵ�СΪhw��hwhw �� hwhw��hw�����ƾ�����ȡ���ֵ��
������ǿģ�飺
���з������ʹ��ȫ��ƽ���ػ�����֧��ͼ������ȡ��������Ȼ�������ڲ�ѯĿ���������ܱ�֧��������ö��С�ö֧࣬��ͼ���ϵ�ȫ��ƽ���ػ��ᵼ�¿ռ���Ϣ��һ�¡���ˣ�ʹ��ȫ�ֳػ�֧������ֱ��ƥ���ѯ���Ե�ÿ�����ز������롣
PPM��ASPP����Ϊ�����ṩ��߶ȵĿռ���Ϣ���������Dz�������õģ�ԭ���ж���1��������Ϊ���ϲ��������ṩ�ռ���Ϣ��û����ÿ���ض��ij߶��Ͻ���ϸ��������2�������˲�ͬ�߶ȵIJ�ι�ϵ
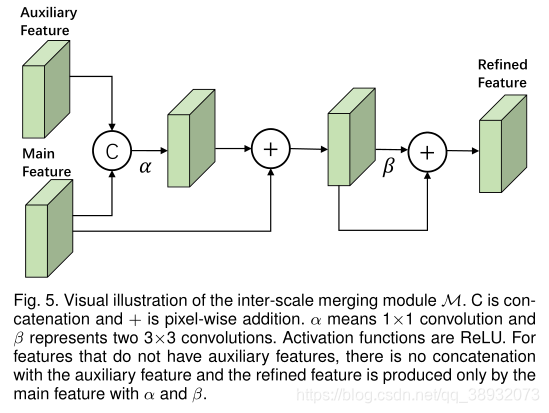
Ϊ�˽���������⣬���ĶԶ�߶Ƚ���зֽ⣬�����һ��������ǿģ�飨FEM������Ҫ˼·��1����ÿ���߶��ϣ���ѯ������֧�������������������ˮƽ������2����ֱ���ò�ι�ϵ��ͨ���Զ����µ���Ϣ·����ϸ������������ȡ������Ϣ���ḻ�������������ں���������Ż����ռ�ͶӰ�ɲ�ͬ�߶ȵ��������γ��µIJ�ѯ������
FEM�ľ���ʵ�ֹ��̣�
FEM��Ҫ��Ϊ��������ģ�飺1��Inter-Source Enrichment-----���ȶԲ�ͬ��ģ��ͶӰ�������룬Ȼ����ÿ����ģ�ж����ؽ���ѯ������֧�����Ժ�����������н�����2��Inter-scale interaction-----��ѡ����ڲ�ͬ��ģ�ĺϲ��IJ�ѯ�C֧������֮�䴫�ݻ�����Ϣ��3��Information concentration------�ϲ���ͬ�߶ȵ����������ղ���ϸ���IJ�ѯ������
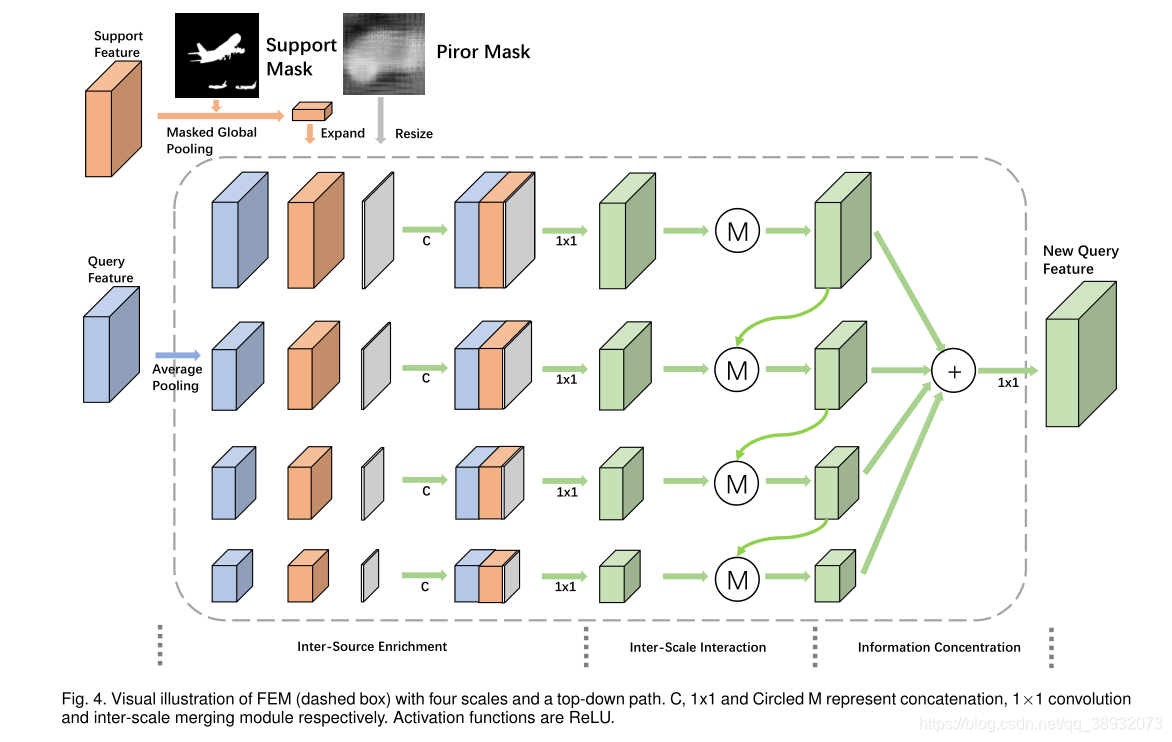
Inter-Source Enrichment������ƽ���ػ�������ͬ�߶ȵ�����ͼ���ٽ��кϲ���
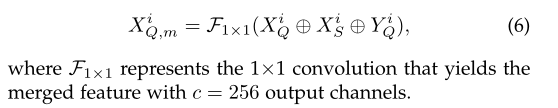
Inter-Scale Interaction����Ҫע���һ�����²�������ӳ����ܵ���С������ʧ������Ӧ�شӽ�ϸ��������ϴֵ�����������Ϣ���Զ�����·�������������ǵ������ḻģ���н�����ι�ϵ��������������ÿ���߶ȵIJ�ѯ��֧������֮��(ˮƽ)���������ڲ�ͬ�߶ȵĺϲ�����֮��(��ֱ)�����������������ܡ�
��ʧ������ƣ�
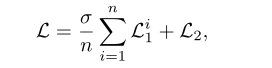
����L1i(i��{1,2,...,n})\mathcal{L}_{1}^{i}\left( i\in \left\{ 1,2,...,n \right\} \right)L1i?(i��{
1,2,...,n})��ʾ�м�ļල��ʧ��Ҳ����Inter-Scale Interaction������ֵ���ʧ��L2\mathcal{L}_{2}L2?��ʾ����������Ԥ��������ʧ����\sigma������ƽ���м�ල��Ȩ�ء�
ʵ����
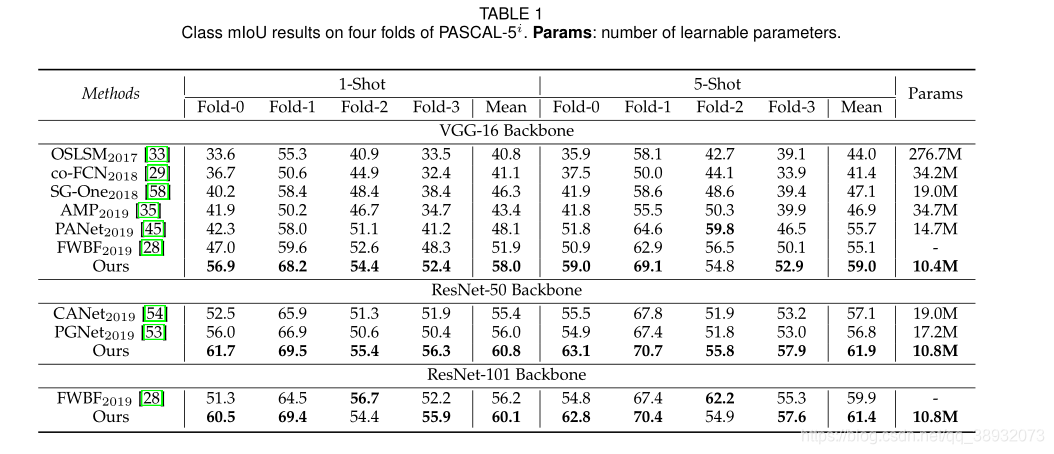
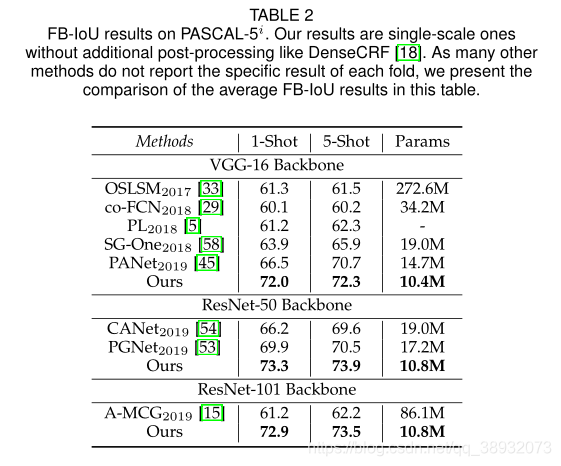
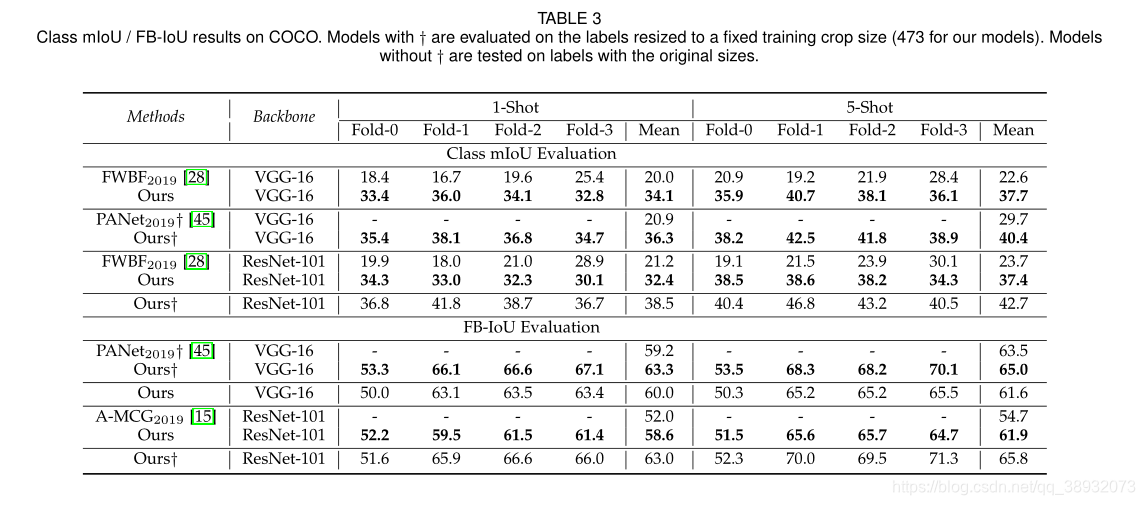
PFENet��PASCAL-5i���ݼ��ϴﵽ���µ�SOTAˮƽ����COCO���ݼ���mIoU���������Ƚ�������Ҫ�߳�10���㡣��PANet��ȣ���FB-IoU�ϵ��������������COCO�ϵ�mIoUҪСһЩ����ΪFB-IoUƫ���ڱ������࣬���า���˺ܴ�һ����ǰ������ֵ��ע����ǣ�PFENet�����ٵĿ�ѧϰ����(����VGG��ģ��Ϊ10.4M������ResNet��ģ��Ϊ10.8M)�����������ܡ�

����ʵ��
���Inter-Scale Interactionʵ����������ʹ�ý�ϸ������(��������)Ϊ������(��Ҫ����)�ṩ������Ϣ��ʹ�ô�����(��������)ϸ����ϸ������(��Ҫ����)����Ч��������Ϊ����Ϣ���еĺ��ڣ����Ŀ�������С��Χ����ʧ���������Ͳ�������Բ�ѯ�࣬Ҳ��������һ�����Զ��������ӵķ���Ҫ���������ķ�����
ͬʱ����ʵ����������������ɵ���Ч�Խ����˷����������ķ���������PANet��SG-One�����������ɹ����а�����ѧϰ�������������ɵ�������ѵ��������ƫ���ڻ��ࣨ����һ��ͼ�кܶ��ƿ�ӣ�������ֻ�������������Ե��Ǹ�ƿ�ӣ�������ܲ�����������Ҫ�Ľ��������Σ�����֧������������ص���Ϣ�ڳػ������п��ܻᱻ����ص���Ϣ��û�����֧������������ƽ���ػ��ᵼ���б���ʧ�����磬��è����������������Ҫ��ͷ������������������Ƶ�����(���磬��β���㶯��)����ʹ������ȫ��ƽ���ػ���masked GAP���������ı�ʾʧȥ��֧�������а������б�����Ϣ��
����
����������������������ɷ�����������ǿģ�飬�������������������ǿ����(PFENet)���������ɷ���ͨ�����ö�Ԥ��ѵ���õĸ��������������ƶȼ�����������ܡ������������ģ���õضԲ�ѯĿ����ж�λ��������ʧȥ����������FEMͨ���м�ල����������ѡ������Ӧ���ں϶�߶ȵIJ�ѯ��֧������������˿ռ䲻һ�������⡣ͨ����Щģ�飬PFENet��PASCAL-5i��COCO���ݼ��ϻ�������µĽ������û������̫���ģ�ͳߴ��������Ч����ʧ��zero shot ������ʵ���һ��֤�������ǹ�����³���ԡ�δ�����ܵĹ��������������������չ���پ�ͷĿ������پ�ͷʵ���ָ