������
���ģ�Ѽ��������������ѧϰ��������ص���˽���⡣
���������⣺
1.�ռ���Щ���ݵĹ�˾����Զ������Щ���ݣ������ռ����ݵ��û�������ɾ����Щ���ݣ�Ҳ���ܿ������ʹ����Щ���ݣ�Ҳ���ܿ��ƴ����ǵ�������ѧϰ���Ķ��١�
2.ͼ���������¼�����������Ⲷ����������Ʒ�沿�����ơ�������Ļ������˵���������ͻ��������ȡ�
3.��˾������û�����Ҫ���ܴ�Ʊ���Ѳ������Լ����Ұ�ȫ���鱨��������������
4.��������ͷ�Դ��������û��ռ��ġ������ݡ���¢�����������ǶԴ���Щ������ѧϰ�����˹�����ģ�͵�¢����
��ƪ���ĵ���Ҫ���µ�������ѡ��Ĺ���ģ�͵IJ�����
���ֲ��������ķ�����ʹ�ü�ʹû�ж���ı������Ѿ�ʵ���˱��κ����еķ�������ǿ�����˽��ϵͳ��Ψһ��й©����ֱ����ʾ����ѵ�����ݣ�����ͨ��һС����������������й©��Ϊ�˾�����������й©������չʾ�����ʹ��ϡ������������������˽Ӧ���ڲ������£��Ӷ��������ڲ���ѡ����ѡ��Ҫ�����IJ�������������ֵ��ɵ���˽��ʧ��
�����������ѧϰϵͳ�ļܹ���
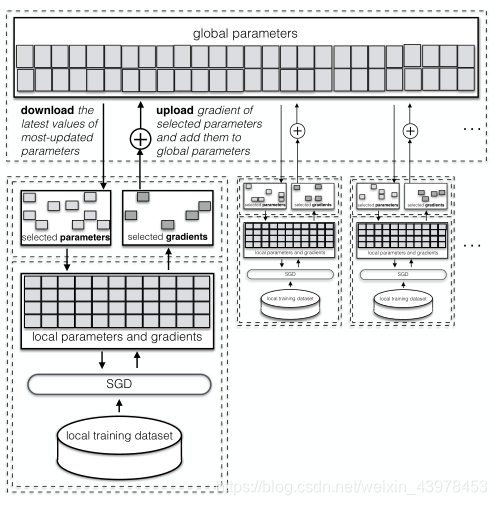 DSSGD������������������ͬʱ����ѵ������ÿһ��local training֮��ÿ�����뷽�������첽ѡ���ݶȽ��й������ϴ�����ÿ�����뷽���Կ�����Ҫ�ϴ����ݶȵĸ����Լ�������Ƶ�ʡ����ķ��������Ը����ϴ����ݶȸ�����Ӧ�IJ�����
DSSGD������������������ͬʱ����ѵ������ÿһ��local training֮��ÿ�����뷽�������첽ѡ���ݶȽ��й������ϴ�����ÿ�����뷽���Կ�����Ҫ�ϴ����ݶȵĸ����Լ�������Ƶ�ʡ����ķ��������Ը����ϴ����ݶȸ�����Ӧ�IJ�����
Ԫ������

DSSGD�ڸ������뷽�еĹ���

ѡ���ʼ������
��ѧϰ�ʦ�
repeated��
��1����server������
x
�IJ������滻��Ӧ�ı��ز�����
��2���ڱ������ݼ�����SGD��������
.
�����SGDһ�����mini-batch SGD�����ѡ��һ���СΪM��batch������Ȼ��Ҳ����ʹ��SGD��
��3���������е�parameters�������ݶ�
��4���ϴ�
��server.
��ô������Ӧ������ϴ��أ��ϴ������أ�
�������ᵽ�������ϴ��ݶȵķ�����
��1��ѡȡ��ģ��������
���ݶȽ����ϴ�����S=
.
��2�����ݶ�ֵ������ֵ�ӵ��ϴ�
ע�⣺���ϴ�
֮ǰ�����ǵ�ֵ���ض���[-�ã���]֮�䣬����Ϊ�˷�ֹ��˽й¶�ö࣬�������ϴ�֮ǰ������������ʵҲ������֮��һ����Χ[
,��]֮�䣬���Ҽ�������֮�����ϴ���
����������
�����ϴ����������������ϴ����ݶ���Ӧ�ĸ���global parameters�ͼ���������Ϊ��ʹ��������µIJ�����Ȩ�ظ����������ԵĽ���������˥�����Ӧ£���stat*�£�
˼����Ϊʲô�ֲ�ʽ����ݶ��½����Դﵽһ���õ�Ч���أ�
ԭ������ݶ��½���Ƚ������ݶ��½�������ͬ��֮����
ѵ����������ȫ�ֲ����Ӽ����¾ֲ�����������˾ֲ�SGD������ԣ��������ֹ����SGD���������С�ͱ������ݼ�����������Ҫ�����á�����ѵ��ʱ��ÿ�������߶���������ֲ����š�������������ѧϰ��ֵ���DZ���ѧϰ�IJ�������Щ�������ڲ�ͬ�����ݼ��Ͻ���ѵ����������ÿ�������߱ܿ������Ż�����ʹ�����ܹ�̽������ֵ���Ӷ��õ�����ȷ��ģ�͡�
DSSGD�в����������Ĺ���

��ʼ��
����������������0
�¼����ϴ�
������Ӧ�IJ�����������+1������
�¼���download
�Լ�����������������stat_j�������е�
��������ȥ��
��������ʹ�õ����ݼ���
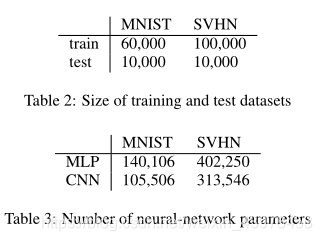
1��MNIST����д���ݼ�����3232��ͼ��60000��ѵ������10000�����Լ���
2��SVHN���ȸ�־����ݼ�����3232��ͼ����600000�����ݣ�������ʹ��100000����ѵ����10000�����������ԡ�
�淶�����ݣ�
��ȥѵ�������е�ƽ��ֵ�����������淶�����ݡ�
�����ж��������ݼ���������������ֱ���1024��3072��
������ʹ��������������ṹ�����в��ԣ�
1��MLP������֪����
2��CNN�����������磩
ͼ5��MLP����ͼ6��ͼ7��CNN�����ṩ�����ǵ�����ܹ��ľ�ȷ�淶��


�ڸ����ĵ�ʵ���У�ʵ��������ѡ��Ҫ�����������������ݶȵı���
1�������ֵ������£�ÿ���������ϴ���һ������ѵ��ʱ������ֵ�����ݶ���
2���������ϴ�ֵ������ֵ���ݶ����������
����������ÿ�������߶���ѡ�����������µIJ�����
�����ĵ�ʵ���У�ѡ�����صIJ�������Ϊ1��Ҳ���ǽ�����ȫ������������
��ͬԪ����ֵ��С������С�����ݶȵķ�������SGD��SSGD
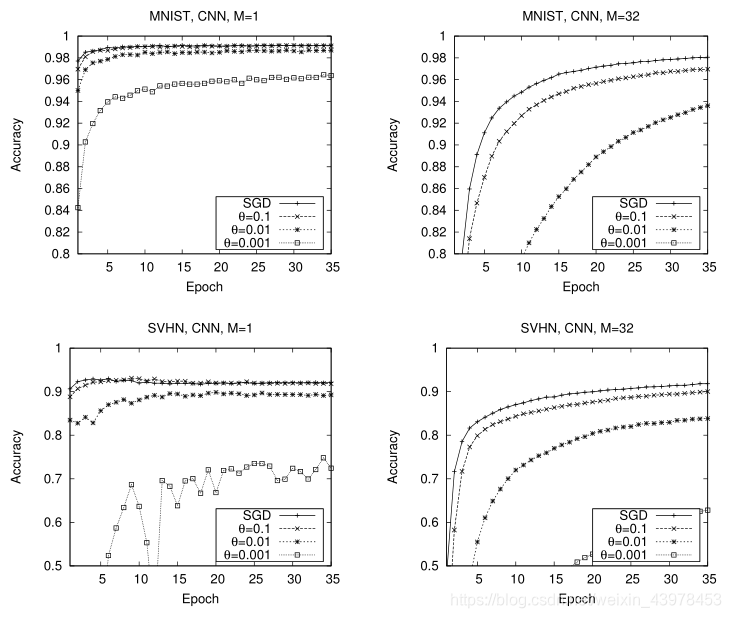
�������ͼ���Է��֣�
��mini-batch ��size����Ϊ1������ѵ��������ʵ���˺ܸߵ�����ԣ������ٶȷdz��죬��Ҳ�ᵼ��һЩ���ߵIJ�������mini batch ��size����Ϊ32ʱ���������ݶ��½��ڼ������ѵ�����ݵ�Ӧ���ݶ�ƽ��ֵ�������ٶȽ�������ƽ����
SSGD��CNN��MLP����ܹ��Ͳ�ͬ������������ʵ�ֵ���ȡ������������Ƚ����˱Ƚϡ���С������СΪ1��
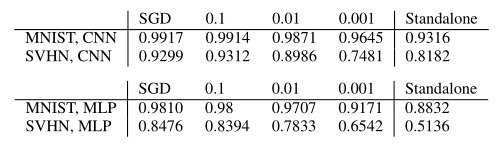
���ϱ����Է��֣�
ͨ����ÿ���ݶ��½����蹲��һС�����ݶȣ��������Ի�ñȶ���SGD���õľ�������Ҳ���˵���˸�����������ķ��������ơ�

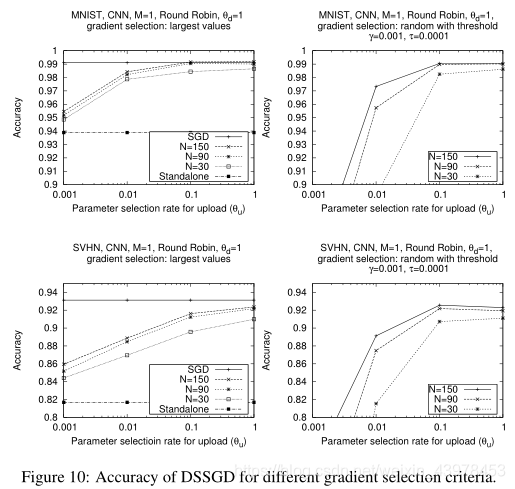
ͨ����������ͼ���Է��֣������ߵ�������ȷ�Ե�Ӱ����ڹ��������İٷֱ���������ֲ�ʽSSGD����Ҫ�ܶ�����������ȷ�ԡ�
ע�⣺��������������Ǽ���ÿ�������������������߹���������ݶȶ���õġ�����Ϊ��������һ�ֹ����ݶȵ�ѡ����������ֵ�ӵ��ݶȣ�
��ͼ��ʾ�˲�ͬ���ݼ���ѧϰ�ʺͲ�����������DSSGD��������
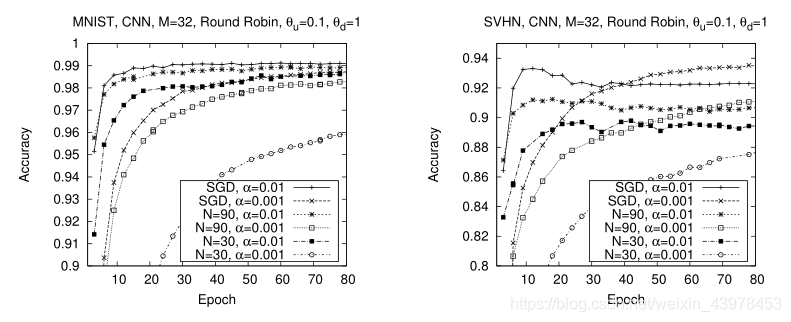 ����ͼ���Է��֣�
����ͼ���Է��֣�
���۲������������٣��ϸߵ�ѧϰ��ȷʵ�ᵼ�¸�����������������ˣ�DSSGD�ķֲ��Ժ�ѡ���Բ���ı��ݶ��½��㷨���������ܡ�
������Ļ��ᵽ��˽��������������Ҫʹ�������˽��������ֹ��˽��й¶��
��ͳ���ѧϰ�еļ�����˽���⣺
��1�����е�ѵ�����ݶ���¶��������������ӵ����û�ж����ݵĿ���Ȩ��
��2������������������ѧϰĿ�꣨������ѵ���ĸ�ģ�ͣ������������������֪�����������ƶϳ�ʲô�����磬һ���˿���Ը���������ͼ����������ʶ�𣬵���Ը��ӱ��������ƶ�����λ�á�
��3���ڴ�ͳ�����ѧϰ�У�ѧϰģ�Ͳ���ֱ���ṩ�����������������������ʹ���������DZ��������ģ�͵Ĺ�˾¶���ǵ����룬�Ӷ�ʹ������������ѵ������ͬ����˽���ա�
�����ķ�ֹ��ֱ��й¶�ͼ��й¶�����������
��1��ֱ��й¶
��ѵ��ģ�͵�ʱ�� �����߲������κ���¶���ǵ���ѵ���ݼ����Ӷ�ȷ�����ǵ����ݾ��к�ǿ����˽�ԡ��������ݼ�����С�Ͷ�̬�DZ����ģ�������ÿһ��SSGD�п���ʹ�ò�ͬ������������������������ʱɾ������ѵ���ݡ�
��ʹ��ģ�͵�ʱ�� ���в������ڱ��غ�˽��ʹ��ģ�ͣ����������������߽����κ�ͨ����Ҳ�������κ���¶�������ݻ�ģ�͵����.
��2�����й¶
�����߿���ͨ����������һС�����������������ӵؽ�ʾһЩ��������ѵ�����ݼ�����Ϣ�����Ը�������ʹ��������˽��ȷ���������²���й¶����ѵ�����ݼ����κε������̫����Ϣ��
�����˽
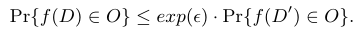
�ڸ������У�f��������ݶ���ѡ��Ҫ�����������������IJ����ݶ��� DZ��й©��������Դ�� ���ѡ��ѡ��˭��
Ϊ�˻������������͵�й©����һ�µIJ����˽�����£�����ʹ�� ϡ���������������ѡ��һС�����ݶ�ֵ������ֵ���ݶȣ����ҹ�����ѡ�ݶȵ��Ŷ�ֵ��

���ȣ�ÿ��������j��ÿ��epoch������˽Ԥ�㶼��Ϊ��===�����ŷֳ�c���֣�����c=�����ϴ����ݶȵ�����������
��������ÿһ�������ߵ�ÿһ�����ϴ��IJ���j���ݶȣ���Ԥ��Ϊ
===����ÿ���ϴ�ֵ��Ԥ���Ϊ�����֣�1���������������j���ݶ�
�Ƿ������ֵ�ӣ���������Ԥ��Ϊ
��2������release���ݶȣ���Ԥ�����Ϊ
ʹ��������˹������ѡ�����ϴ�ʱ���ݷ����Ԥ��������������
����ȡ����Ԥ����ÿ�������ݶȵ����ж�
�ڸ������У��������в������ݶȵ����жȶ�����ͬ�ģ���ô�����Ĵ�С�ͽ���ȡ�����������Ԥ�㡣