Progress&Compress:一个可扩展的持续学习框架
- Abstract
- 1. Introduction
- 2. The Progress and Compress Framework
- 2.1. Learning a new task
- 2.2. Distillation and knowledge preservation
- 3. Related Work
- 4. Online EWC

Abstract
我们介绍了一个概念上简单且可扩展的框架,用于连续学习领域,其中任务是按顺序学习的。我们的方法保持了参数的数量,并被设计为在加速后续问题的学习进程的同时保持先前遇到的任务的性能。这是通过训练一个包含两个组件的网络来实现的:知识库,能够解决以前遇到的问题,这个数据库连接到一个活动列,用来有效地学习当前任务。在学习了一个新任务后,活动列将其分解到知识库中,并注意保护之前获得的技能。主动学习(渐进式)和整合(压缩)的循环不需要架构增长,不需要访问或存储以前的数据或任务,也不需要任务特定的参数。我们演示了对手写字母顺序分类的进度和压缩方法,以及两个增强学习领域:Atari游戏和3D迷宫导航。
1. Introduction
神经网络的标准学习过程由于假设训练样本是从某个固定分布中提取而受到限制的。在许多情况下,这种限制并不重要。然而,它可能被证明是一个重要的局限性,特别是当一个系统需要不断地适应不断变化的环境时,例如在强化学习和其他交互的主体,如机器人或对话系统中经常出现。这种连续完成任务而不忘记如何完成之前训练过的问题的能力被称为持续学习。
大量的文献都承认了持续学习问题的重要性,最近人们对这个话题的兴趣越来越浓厚。挑战的一部分源于这样一个事实:对于持续学习,存在着多种需求,通常是相互竞争的:
- 一种持续的学习方法不应该遭受灾难性遗忘。也就是说,它应该能够在先前学习的任务上表现出色。
- 它应该能够学习新的任务,同时利用从以前的任务中提取的知识,从而表现出积极的前向转移,以实现更快的学习和/或更好的最终表现。
- 它应该是可修改的,也就是说,该方法应该是可在大量任务上进行训练的。
- 它还应该实现正向的反向转移,这意味着在学习了一项类似或相关的新任务后,在先前的任务上的表现会立即得到改善。
- 最后,它应该能够在不需要任务标签的情况下学习,实际上它甚至应该在没有明确任务边界的情况下适用。
许多方法解决了其中一些问题,却损害了另一些问题。
例如:朴素的精调常常导致成功的正向迁移,但会遭遇灾难性的遗忘;弹性重量巩固(EWC)专注于克服灾难性遗忘,但Fisher调节器的积累会过度限制网络参数,导致对新任务的学习受损。
渐进式网络(Rusu et al.,2016a)通过完全重构避免了灾难性遗忘,但是由于网络规模在任务数量上呈二次方扩展,它会因缺乏可扩展性而受到阻碍。
本文提出了一个步骤,通过利用它们的互补优势,同时最小化它们的弱点,来统一这些技术在一个框架中,以满足多个需求。
该方法实现了基于知识基的神经网络和一个主动列网络,并将其分为两个不同的、交替的训练阶段。
在 progress 阶段,网络会出现一个新的学习问题,并且只对活动列中的参数进行优化。
与渐进网络的架构类似(Rusu等人,2016a),知识库和活动列之间的分层连接被添加,以便于重用知识库中编码的特征,从而实现从先前学习任务的正向转移。
在进度阶段完成时,活动列被提取到知识库中,从而形成压缩阶段。在提炼过程中,必须保护知识基础,防止灾难性遗忘,这样就可以保留以前学到的所有技能。我们提出了弹性重量整合(Elastic Weight consolidation)(Kirk-patrick et al., 2017)的改进版本,以减轻知识库中的遗忘。
Progress&Compress(P&C)算法交替使用这两个阶段,允许遇到新的任务,主动学习,然后小心地将其存入内存。这种方法有目的地让人想起白天和晚上,以及睡眠在巩固人类记忆方面所起的作用,使白天掌握的重要技能在夜间得以保留。由于P&C使用两列固定大小的列,所以它可以扩展到大量任务。在实验中,我们观察到了正迁移,在不同的领域中减少了遗忘。
2. The Progress and Compress Framework
P&C体系结构由两个组件组成:一个知识库和活动列。这两个组件都可以可视化为网络层的列,这些列计算预测的类概率(在监督学习的情况下)或策略/值(在强化学习的情况下)。这两个组件都可以可视化为网络层的列,这些列计算预测的类概率(在监督学习的情况下)或策略/值(在强化学习的情况下)。这两个部分在交替阶段学习(进步/白天和压缩/夜间)。
图1展示了P&C应用于强化学习时的体系结构和两个阶段的学习。
2.1. Learning a new task
将体系结构分为两个部分,这使得P&C在引入新任务时将重点放在正向转移上。如图1所示,知识库(浅蓝色)是固定的,而活动列中的参数(绿色)是在没有约束或规则的情况下优化的,允许对新任务进行有效的学习。此外,P&C通过简单的基于知识库的适配器(横向箭头)实现了对过去信息的重用,这是一个借鉴自Progressive Nets的想法。

请注意,在引入一个新任务时,不重置活动列或适配器,可以使这个阶段类似于对先前任务进行训练的网络的原始优化。经验上,我们发现当任务非常相似时,这可以改善正向转换。对于更加多样化的任务,我们建议重新初始化这些参数,这样可以使学习更加成功。
2.2. Distillation and knowledge preservation
在压缩阶段,新学习到的行为被整合到知识库中。这也是防止灾难性遗忘的方法被引入的地方,巩固是通过蒸馏过程完成的(Hinton et al., 2015;Rusu et al., 2015),它是将知识从主动库转移到知识库的有效机制。在RL的设置中,它还有一个额外的优势,那就是蒸馏损失的规模不依赖于奖励方案的规模,而奖励方案对于不同的任务可能会有很大的不同。我们将教师(活动专栏)和学生(知识库)的预测/政策之间的交叉熵最小化。作为知识保存的一种选择方法,我们重新考虑了弹性权重合并(EWC)(Kirkpatrick等人,2017),这是一种最近引入的方法,为持续学习提供了近似的贝叶斯解决方案。其主要观点是,与不同任务相关的信息可以依次合并到后端,而不会产生灾难性遗忘,因为结果后端不依赖于任务排序。然而,精确的后验函数对于神经网络来说是困难的,EWC采用了不可伸缩的高斯近似。这就产生了一个正则化项,每个先前的任务都有一个,约束参数不要偏离那些被优化的参数。然而,正则化项的数量随着任务的数量呈线性增长,这意味着EWC算法无法扩展到大量任务。在第4节中,我们详细说明了一个我们提到的online EWC的修改,它在计算需求中不表现出这种线性增长。

3. Related Work
现在,我们对持续学习领域的工作做一个简短的调查,根据在第1节中介绍的需求来描述每种方法。请注意,持续学习有不同的名称(尽管焦点有所不同),如终身学习(Thrun,1996)和永无休止的学习。与持续学习略有不同,inTaylor & Stone(2011)讨论并比较了迁移学习在强化学习中的不同方面。
一种常见的选择方法是在目标域中对预训练的模型进行微调,因此引入了一种可选的初始化方法。这种方法由于其简单而被广泛使用,并且已经被证明是一种成功的正迁移方法,只要有足够的任务相似性。早期成功的应用包括无监督到监督的迁移学习(Bengio,2012)和视觉领域的各种结果。当考虑一系列的任务时,这通常是通过精心设计课程来完成的,引入越来越复杂的任务。由于灾难性遗忘是一个重要的问题,这样的方法通常不能组合在以前的任务中学到的技能,除非这些技能一直被重用。这项技术的例子包括从深度Q网络或课程学习记忆模型(Graveset al., 2016).
第二类方法引入了特定于任务的参数,允许更大集合中的组件学习特定于给定任务的数据表示。这种模型的转换可以通过共享一个子功能集或在这些特定于任务的模块之间引入连接来实现。这些方法的一个明显的问题是它们缺乏可伸缩性,常常使应用程序在处理大量任务时计算繁琐且不稳定。此外,必须在测试时提供或推断任务标签,这样才能确定正确的模块。
渐进式网络(Rusu等人,2016a)是这一类别中为持续学习而设计的一种方法。作者提出了一种为每个任务引入相同的神经网络列的架构,允许转移适配器连接到专门用于解决预先出现的问题的列。这种方法有特别的吸引力,特别是它对灾难性遗忘的免疫力,这是因为在学习了一个任务后会冻结参数。不幸的是,这不允许正向 backward transfer。
Learning Without Forgetting (Li & Hoiem, 2017)主要关注于提高应对灾难性遗忘的韧性。
这是通过在共享参数更新之前将旧任务模块的输出记录在当前任务的数据上来实现的,从而允许在训练期间对这些值加正则化。

这种方法的一个问题是,它不能立即适用于强化学习。其他的例子包括
其中(Rozantseve et al.,2016)引入了柱之间的选通机制,他们制定了另一个正则化目标,以保持列的权重不变。
另一类工作是基于情节记忆的思想,即储存先前任务中的例子,以便有效地回忆过去遇到的经验(Robins,1995)。利用这一观点的例子有(Reffi等人,2016年;Schmidhuber,2013年;Thrun,1996年)。LopezPaz等人提出了类似的方法。(2017),然而,不是存储示例,而是存储前一个任务的梯度,以便在任何时间点,除当前任务外的所有任务的梯度都可以用来形成一个防止遗忘的信任区域。这些方法可以有效地对抗灾难性遗忘,并为相关经验的选择提供了一个良好的机制。内在问题是对存储在内存中的经验量的限制,这可能很快成为大规模问题的一个限制因素。最近的方法试图通过从生成模型中采样合成数据来克服这一点(Shin等人,2017年;Silver等人,2013年)这就把灾难性的遗忘问题转移到了生成模型的培养上。重复过去的经验可以被看作是更接近于多任务学习(Caruana, 1998),它不同于持续学习,因为所有任务的数据都是可用的,并且共同用于训练。在最简单的情况下,这是通过共享参数来实现的,类似于前面提到的方法。Distral (Teh et al., 2017)通过共享一个捕获和转移跨多个任务行为的倾斜策略,明确关注积极转移。
蒸馏还被Ghosh等人(2017)用于复合多种低水平的RL技能,并被Furlanello等人(2016)用于通过迁移学习范式来维持在多个连续监督任务上的绩效。另一种方法是通过正则化学习来避免灾难性遗忘。其中一个突出的例子是弹性重量固固(Kirkpatrick et al.,2017)。突触智能(Zenke et al., 2017)类似于弹性重量巩固,但可以沿着整个学习轨迹在线计算重要的计算量。最近,he & Jaeger(2018)提出了一种不同的机制,它使用梯度的投影,这样与上一个任务相关的方向不会受到影响。
PLAiD (Berseth等人,2018)与我们的方法相似。然而,这种方法并不是为了持续学习而设计的,而是为了最大限度地提高迁移率,因为它假设在任何时间点都可以访问所有任务。这种方法和我们的方法一样,分为两个阶段。在一个阶段,一个新的任务被学习,从以前学过的任务转移过来。在第二阶段,从所有之前看到的任务中提炼出的多任务整合学习到的策略。
4. Online EWC
弹性权重整合(EWC)的起点(Kirkpatrick等人,2017)是对持续学习的近似贝叶斯处理。


注意,在上面的公式中,需要为每个任务保留一个平均值和一个费雪函数,这使得计算成本在任务数量中呈线性。我们可以通过完成(6)中fisher正则化项的平方来将成本降低到一个常数。或者,正如(Husz?ar,2017)所指出的,我们可以将拉普拉斯近似法应用于整个后部(4),而不是可能性条件。这个导致以下损失。

请注意,目前尚不清楚这种重新确定中心对非线性神经网络的影响(Husz?ar,2017)未显示任何实验验证)。将平均值移动到最新的映射值将意味着旧任务的记忆将会变差,因为将不会有任何规则条款约束参数以接近旧任务学到的。我们在附录中展示了这种效果。
在一个持续或终身学习的制度中,当模型被应用于许多任务时,一个有趣的方面发生了。(Husz ar, 2017)提出采用期望传播(EP) (Minka, 2001)方法对每个可能性保持一个明确的近似项。这样,当一个任务被重新访问时,它的似然近似值可以被删除并重新计算。然而,这意味着回归到原始EWC的线性缩放。我们将采用一种随机EP (Li et al., 2015)方法,该方法不对每个因子保持显式逼近。相反,在重新访问任务时,会维护和部分更新单个的总体近似项。

这种方法的好处是避免了标识任务标签的需要,因为该方法同等对待所有任务(与EWC/EP相反)。识别任务边界要比识别任务ID容易得多,因为检测低水平统计信息的变化通常就足够了。例如,在强化学习的情况下,可以使用正向统计的变化,这与由于多巴胺水平的变化而导致的大脑记忆巩固有直接的联系。另一个有趣的副作用是,通过γ向下加权,该方法可以以一种优雅和受控(而不是灾难性)的方式显式地执行遗忘任务。这是有用的,例如,如果学习没有集中在一个较老的任务,它是最好优雅地忘记它对近似值的影响。优雅的遗忘也是持续学习的一个重要组成部分,因为遗忘旧的任务对于为学习新任务腾出空间是必要的,因为我们的模型能力是固定的。没有忘记,EWC在模型容量不足时表现不当,如(Kirkpatrick et al., 2017)所述。我们在网上查阅了我们的修改方法。最后,我们观察到的一个重要现象是,不管任务的奖励方案是什么,每个EWC惩罚都在状态空间中保护了预期的策略。

简单总结:
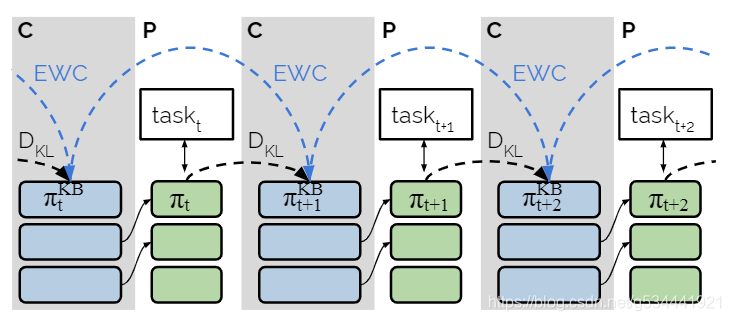

将知识蒸馏到知识基中完成压缩,用EWC方法缓解灾难性遗忘。避免了像Progress Net那样需要保存每一个中间模型。 也是一种trade off。