���Ľ����� Alexa Prize Socialbot Challenge 2019 �ı�������Լ� Topical-Chat ���ݼ�
Aelxa Prize ����
Alexa ��Ϊ Amazon Echo �ṩ֧�ֵ�����������ʹ�ͻ���ʹ�����������Ը�ֱ�۵ķ�ʽ����Χ�����绥����
Alexa Prize Socialbot Grand Challenge ��һ��ּ�ڴٽ��Ի� AI ��չ�Ĵ�ѧ��������������Ҫ��������鿪��һ���罻������������Ϊ Alexa ��һ��ܣ������������Ż���������¼����������������ͳ����Ļ���������
����������������֪ʶ��ȡ����Ȼ�������⣬��Ȼ�������ɣ������Ľ�ģ����ʶ�����ͶԻ�������������˵����������Ҫ�߱�������������1����Ȼ�Ļ����л���2��������ѡ��֪ʶ��3���ܹ�����ʵ�۵㣨֪ʶ�����뵽�Ի��С�
��������Ļ����˽���ȫ�� Alexa �û����жԻ������� Alexa �û����Խ�����ֺͷ���������������������Ľ��㷨��
���ջ�ʤ�Ķ��齫���50������Ĵ�
Alexa Prize 2019
Alexa Prize �� 2017 �꿪ʼ��Ŀǰ�Ѿ��ٰ����죬�����죨�� Alexa Prize 2019���ڲ���ǰ������2020��7�£���
ʱ�䰲��
Alexa Prize 2019 ������������һ��࣬����ʱ�䰲�����£�
| ʱ�� | �¼� |
|---|---|
| 2019��3��-5�� | ��������� |
| 2019��6�� | �����������飨10֧�� |
| 2019��12�� | ��Alexa�û����� |
| 2020��2��-3�� | �ķ�֮һ������9֧�� |
| 2020��3��-4�� | �������5֧�� |
| 2020��5��-7�� | ������3֧�� |
| 2020��7�� | ר�������� |
�������
������ڼ䣬���ж����ƽ���÷֣�Alexa �û����֣����5�֣�Ϊ 3.47 ��
| year | average score |
|---|---|
| 2017 | 2.91 |
| 2018 | 3.19 |
| 2019 | 3.47 |
����Ĭ���ѧ�Ĺھ�����ƽ���Ի�ʱ��Ϊ 7��37��
| award | final score | team | school | last |
|---|---|---|---|---|
| $500,000 | 3.81 | Emora | The Emory University | #4 |
| $100,000 | 3.17 | Chirpy Cardinal | Stanford University | - |
| $50,000 | 3.14 | Alquist | Czech Technical University | #2 |
Alexa �û������Ȥ�Ļ��⣨��ɫ��������Ӱ���Ƽ������֣����� Other Ϊ�������⣬COVID-19 �¹ڲ���ռ���ؽϴ�

���������У��������齫��� Amazon �ٷ�֧�֣����� �о����ѣ�Alexa �豸��AWS ����ȡ��������⣬���α������ṩ�˶Ի������˹��߰���CoBot���Լ�����Ի����ݼ���Topical-Chat����
Conversaton Bot (CoBot)
Advancing the State of the Art in Open Domain Dialog Systems through the Alexa Prize
ϵͳͼ
CoBot ��һ���Ի�ʽ�����˹��߰����ṩһϵ�еĻ���ģ���Ԥѵ��ģ����������ʹ�ã��������̶��ϼ��ٲ��������ڻ����ܹ��������չ�Ϻķѵľ�����
CoBot ��ϵͳͼ�����������£�
- Alexa Skill Kit �ṩ�����������������ܣ���������Զ�����ʶ��ASR��automatic speech recognize���Լ���ͼʶ��ȹ���
- AWS lambda �� AWS ���������ӿڣ������߿��Զ����������Ӧ�¼��������ú����Ĵ���ģ��
- AWS ECS �� Amazon ���Ʒ������й�Ԥѵ����ģ��
- TTS ���ı�תΪ������text-to-speech��

�ܹ�ͼ
CoBot ����Ĭ�ϵĴ������̣�����������ࡢ���ʶ���NER�� NLU ģ�鹦�ܣ�Evi QA �����Լ�ȫ�ֵ�״̬���������� key-value ��ʽ������ DynamoDB �У��������߿����ڴ˻����Ͽ����Զ��幦�ܼ�ģ�顣

-
Dialog Act and Topic Classification
-
ʹ�û��� ���RNN��HRNN�����������ͼ���Ϸ���ģ�ͣ����� GRU��

-
-
Neural Response Generation
-
���� GPT-2 �� Topical-Chat ���ݼ���ѵ������֪ʶ������ģ��
-
����ʱ������ʹ�õ�֪ʶ�Լ��Ի���ʷ���������֪ʶ�Ļظ�

-
Topical Chat ���ݼ�
Topical-Chat : Towards Knowledge-Grounded Open-Domain Conversations
��������
Topical-Chat ��һ������֪ʶ�����˶Ի����ݼ��������֪ʶ����8���������������֪ʶ��Դ��Washington Post Articles��Reddit fun facts��Wikipedia articles about entities����
ÿ�ֶԻ���ע��˵��������Լ��ظ����������ܹ����� 10,000 ���Ự��conversation����230, 000 �ֶԻ���utterance����
�Ի���û����ȷ��������ߵĽ�ɫ��Wizard of Wikipedia�� WoW �д���һ�� Wizard ���жԻ��������������Ͽ�������ʵ�Ի��ص㡣
�������⼰��Ӧ��ʵ��������£�
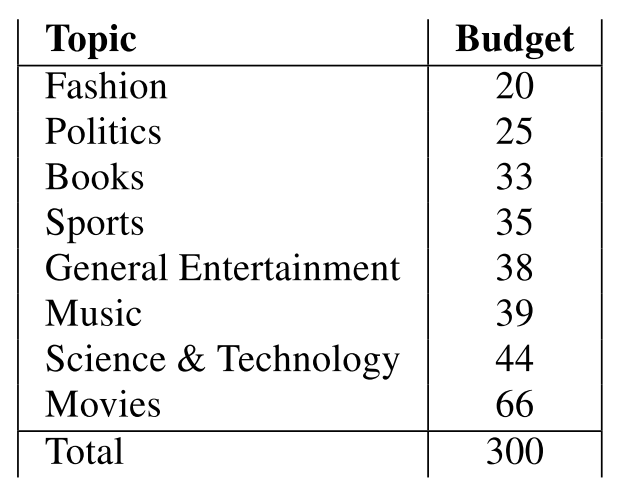
֪ʶ��Դ
֪ʶ��������ԭ�ﹹ�ɣ�ʵ�壨entity������ʵ��fact�������£�article������ȡ��������
- ʵ��ѡ��Entities Selection��
- ��ǰ��������û��Ļظ�ѡ�����ܻ�ӭ�� 8 �����300��ʵ��
- ��ʵѡ��Fact Selection��
- ��ȡ 300��ʵ��� Wikipedia ���Բ��֣�Ȼ��ʹ�� Reddit �ڰ�Ϊÿ��ʵ�幹�� 8-10 ����Ȥ����ʵ������ Wikipedia ���Թ��죩
- ����ÿ��ʵ�壬���������汾�� Wikipedia �������֣���һ���ǰ����������ֵ�һ�仰�Ķ̰汾��50�ʣ����ڶ�����ʹ�� TextRank �����������ֵ�ժҪ���ܣ�150 �ʣ�
- ����ѡ��Article Selection��
- ��ȡ Washington Post ��2018�����������£�600-1000�ʣ����ܹ� 3088ƪ���£�ÿƪ�������ٰ�������������ʵ��
֪ʶ�������У���article��Ϊ���������ҹ��������Ϣ���ԳƵ�֪ʶ�������ṩ���Ի�˫��ʹ�ã�˫��֪ʶ�����ܲ��Գƣ�ģ����ʵ�������
�Ի���������У�ÿ��ʵ����� wikipedia �Ķ̽��ܻ���ժҪ�����Լ���Ȥ����ʵ�������жԵ�ǰ�ظ�������б�ע��Angry, Disgusted, Fearful, Sad, Happy, Surprised, Curious to Dive Deeper, Neutral�����Լ��ԶԻ���һ���ظ���֪ʶʹ�ý�������������Poor��Not Good��Passable��Good and Excellent����
���ݻ�ȡ
�� GitHub alexa/Topical-Chat ���أ���Ҫ����֪ʶԴ���ݣ���������
-
reddit ƫ������ ���� API Key
�ο� Instructions for getting Reddit API keys? #1

-
��������
# Ensure that your Python Interpreter >= 3.7 git clone https://github.com/alexa/Topical-Chat.git cd Topical-Chat/src pip install -r requirements.txt# Building the data requires Reddit credentials. # Please create your own Reddit API keys: https://www.reddit.com python3 build.py --reddit_client_id CLIENT_ID --reddit_client_secret CLIENT_SECRET --reddit_user_agent USER_AGENT -
������̣���ѧ��������ʱ2��Сʱ��

����ʾ��
���ݼ��а��� frequent �� rare ������֤����ǰ���е�ʵ����ѵ������Ƶ�����֣�������ѵ�����н�������û�г��ֹ�
| Train | Valid Freq. | Valid Rare | Test Freq. | Test Rare | All | |
|---|---|---|---|---|---|---|
| # conversations | 8628 | 539 | 539 | 539 | 539 | 10784 |
| # utterances | 188378 | 11681 | 11692 | 11760 | 11770 | 235434 |
| average # turns per conversation | 21.8 | 21.6 | 21.7 | 21.8 | 21.8 | 21.8 |
| average length of utterance | 19.5 | 19.8 | 19.8 | 19.5 | 19.5 | 19.6 |
-
�Ի��ļ�
{ <conversation_id>: {"article_url": <article url>,"config": <config>, # one of A,B,C, D"content": [ # ordered list of conversation turns{ "agent": "agent_1", # or ��agent_2��,"message" : <message text>,# Angry, Disgusted, Fearful, Sad, Happy, Surprised, Curious to Dive Deeper, Neutral"sentiment": <text>, # Factual Section 1-3, Article Section 1-4 and/or Personal Knowledge"knowledge_source" : ["AS1", "Personal Knowledge",...], "turn_rating": "Poor", # Note: changed from number to actual annotated text},��],"conversation_rating": {"agent_1": "Good", # Poor, Not Good, Passable, Good and Excellent"agent_2": "Excellent"}},...... } -
֪ʶ����
{ <conversation_id> : {"config" : <config>,"agent_1": {"FS1": {"entity": <entity name>,"shortened_wiki_lead_section": <section text>,"fun_facts": [ <fact1_text>, <fact2_text>,...]},"FS2": {...}},"agent_2": {"FS1": {"entity": <entity name>,"shortened_wiki_lead_section": <section text>,"fun_facts": [ <fact1_text>, <fact2_text>,...],},"FS2": {...}},"article": {"url": <url>,"headline" : <headline text>,"AS1": <section 1 text>,"AS2": <section 2 text>,"AS3": <section 3 text>,"AS4": <section 4 text>}} ... }