一、前言
- 由于Lua语言强调可移植性和嵌入型,所以Lua本身并没有提供太多与外部交互的机制。在真实的Lua程序中,从图形、数据库到网络的访问等大多数I/O操作,要么由宿主机实现,要么通过不包括在发行版中的外部库实现
- 单就Lua语言而言,只提供了ISO C语言标准支持的功能,即基本的文件操作等
- 对于文件操作来说,I/O库提供了两种不同的模型:
- io库中的所有函数在遇到错误时都会返回nil外加一条错误信息和一个错误码
一、简单I/O模型
- 简单I/O模型虚拟了一个当前输入流和一个当前输出流,其I/O操作是通过这些流实现的
- I/O库把当前输入流初始化为进程的标准输入(C语言中的stdin),将当前输出流初始化为进程的标准输出(C语言中的stdout)
- 简单I/O模型提供的接口有:
- io.input():io.read()默认从标准输入读取内容,该函数用来设置I/O的输入流(例如从文件中读取)
- io.output():io.write()默认将内容输出到标准输出中,该函数用来设置I/O的输出流(例如输出到文件中)
- io.write():向打开的输出流中写入内容(如果没有用io.output()设置,默认将内容输出到标准输出)
- io.read():从打开的输入流中读取内容(如果没有用io.input()设置,默认从标准输入读取内容)
io.input()
- io.read()默认从标准输入读取内容,该函数用来设置I/O的输入流(例如从文件中读取)
- 例如,本地有一个文件test.txt,调用下面的函数就可以将程序的输入流定向到test.txt文件中
io.input("test.txt")
- 调用io.input()之后,程序后面的所有输入都来自己该函数指定的输入流;如果想要改变当前的输入流,再次调用io.input()即可
io.output()
- io.output()与io.input()的原理式样的。io.write()默认将内容输出到标准输出中,该函数用来设置I/O的输出流(例如输出到文件中)
- 例如,本地有一个文件test.txt,调用下面的函数就可以将程序的输出流定向到test.txt文件中
io.output("test.txt")
- 调用io.output()之后,程序后面的所有的内容都输出到该函数指定的输出流中;如果想要改变当前的输出流,再次调用io.output()即可
io.write()
- 该函数可以将任意数量的字符串(或者数字)写入到输出流中
- io.write(args)是io.output():write(args)的简写,即函数write使用在当前输出流上的
- 格式如下:参数为任意数量,所有的内容会拼接在一起输出
io.write(a, b, c...)
- 与print的区别:
- print应该用在“用后即弃”或者调试代码中;并且;当需要完全控制输出时,应该使用io.write
- print会在输出的内容后面默认添加注入制表符或者换行符这样的额外内容;io.write不会在输出内容后面添加任何额外的内容
- print只能使用标准输出;io.write可以重定向到别的输出流中(例如到文件)
- print会自动为其参数调用tostring,这一点对于调试非常便利,但也容易导致一些诡异的bug
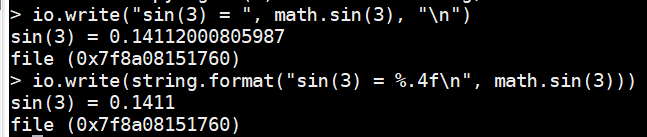
- io.wirte()在将数值转换为字符串时遵循一般的转换规则;如果想要完全地控制这种转换,应该使用string.format()函数:
io.write("sin(3) = ", math.sin(3), "\n")io.write(string.format("sin(3) = %.4f\n", math.sin(3)))
io.read()
- io.read()可以从输入流中读取字符串,其参数决定了要读取的数据

- io.read(args)实际上是io.input():read(args)的简写,即函数read使用在当前输入流上的
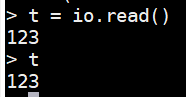
- ①如果不带任何参数时,io.read()的行为等同于io.read("l"),也就是读取一行的内容(丢弃换行符)。例如:
t = io.read()t
- ②参数a:io.read("a")可以从当前位置开始读取当前输入文件的全部内容。如果当前位置处于文件的末尾或文件为空,那么该函数返回一个空字符串
- 例如,Lua语言可以高效地处理长字符串,所以在Lua中编写过滤器的一种简单技巧就是将整个文件读取到一个字符串中,然后对字符串进行处理,最后输出结果:
-- 读取所有内容
t = io.read("a")-- 进行字符串处理, 此处以string.gsub()为例, 将字符串中所有的"bad"替换为"good"
t = string.gsub(t, "bad", "good")-- 再重新输出
io.write(t)
- 例如,下面是一段将某个文件的内容使用MIME可打印字符引用编码进行编码的代码。这种编码方式将所有非ASCII字符编码为=xx,其中xx是这个字符的十六进制。为保证编码的一致性,等号也会被编码(关于匹配的内容可参阅后面的“模式匹配”文章):
t = io.read("all")-- string.gsub会匹配所有的等号及非ASCII字符(从128到255),并调用指定的函数完成替换
t = string.gsub(t, "([\128-\255=])", function(c) return string.format("=%02X", string.byte(c)))io.write(t)
- ③参数l、参数L:
- io.read("l")会读取输入流中的一行(不包括换行符在内);io.read("L")会读取输入流中的一行(会包括换行符在内)
- 参数l是io.read()的默认参数
- 当达到文件末尾时,由于已经没有内容可以返回,该函数会返回nil
- 例如,下面会将当前输入复制到当前输出中的同时对每行进行编号:
for count = 1, math.huge dolocal line = io.read("L")if line == nil then break endio.write(string.format("%6d", count), line)
end
- io.lines():如果想要逐行迭代一个文件,使用io.lines()迭代器会更简单:
local count = 0
for line in io.lines() docount = count + 1io.write(string.format("%6d ", count), line, "\n")
end
local lines = {}-- 将所有行读取到表'lines'中
for line in io.lines() dolines[#lines + 1] = line
end-- 排序
table.sort(lines)-- 输出所有的行
for _, l int ipairs(lines) doio.write(l, "\n")
end
- ④参数n:io.read("n")会从当前输入流中读取一个数值。如果在跳过了空格后,函数io.read()仍然不能从当前位置读取到数值(由于错误的格式问题或到了文件末尾),则返回nil
- ⑤num参数:io.read(num)函数允许用一个数字num作为参数
- 在这种情况下,io.read()会从输入流中读取num个字符。如果无法读取到任何字符(处于文件末尾)则返回nil;否则,则返回一个由流中最多n个字符组成的字符串
- 下面的代码展示了将文件从stdin复制到stdout的高效方法:
while true dolocal block = io.read(2^13) -- 块的大小是8KBif not block then break endio.write(block)
end
- io.read(0)是一个特例,它常用于检测是否到达了文件末尾。如果仍然有数据可供读取,它会返回一个空字符串;否则,返回nil
- ⑥指定多个选项:io.read()函数可以指定多个选项,函数会根据每个参数返回相应记的结果
- 例如,现在有一个文件,每一行由3个数字组成

- 如果想打印每一行的最大值,可以通过调用下面的代码来一次性地同时读取每行中的3个数字:
while true dolocal n1, n2, n3 = io.read("n", "n", "n")if not n1 then break endprint(math.max(n1, n2, n3))
end
二、完整I/O模型
- 上面介绍的简单I/O模型对简单的需求而言还算适用,但对于诸如同时读写多个文件等更高级的文件操作来说就不够了。对于这些文件操作,我们需要用到完整I/O模型
io.open()
- io.open()用来打开一个文件,该函数仿造了C语言中的fopen()函数
- 这个函数有两个参数:
- 参数1:打开的文件名
- 参数2:文件打开模式,与C语言类似,r表示只读,w表示只写(同时删除源文件的所有内容)、a表示追加、b表示以二进制的形式打开文件。详情可参阅C语言的fopen()函数:https://blog.csdn.net/qq_41453285/article/details/88891550
- 返回值:
- 正确:返回打开文件的文件流
- 失败:返回nil,同时返回一条错误消息以及一个系统相关的错误码
- 例如:下面是一些打开文件失败的例子
print(io.open("non-existent-file", "r"))print(io.open("/etc/passwd", "w"))

- 检查错误的一种典型方法是使用函数assert(),如下所示,如果io.open()执行失败,错误信息会作为函数assert()的第二个参数被传入,之后函数assert()会将错误信息展示出来
local f = assert(io.open(filename, mode))
read()、write()
- 当使用io.open()打开文件之后,我们就可以使用read()和write()来读写流,与C语言的read()和write()类似
- 例如,下面打开一个文件读取其中的所有内容
-- 打开流
local f = assert(io.open("filename", "r"))-- 读取流中的所有内容
local t = f:read("a")-- 关闭流
f:close()
内置句柄
- I/O库提供了3个预定义的C语言流的句柄:io.stdin、io.stdout、io.stderr
- 例如,可以使用下面的代码将信息直接写到标准错误流中
io.stderr:write("Error", "\n")
io.input()、io.output()
- 在上面的简单I/O模型中我们介绍过了这两个函数,在完整I/O模型中也可以使用这两个函数
- 调用无参数的io.input()可以获得当前输入流,调用io.input(handle)可以设置当前输入流。如下所示
-- 保存当前的输入流
local temp = io.input()-- 打开一个新的输入流
io.input("newinput")-- 对新的输入流进行一系列操作-- 操作完成之后关闭输入流
io.input():close()-- 恢复之前的输入流
io.input("temp")
io.read()、io/write()
- 在上面的简单I/O模型中我们介绍过了这两个函数,在完整I/O模型中也可以使用这两个函数
io.lines()
- 在上面的简单I/O模型中我们介绍过了这个函数,在完整I/O模型中也可以使用这个函数
- 该函数返回一个可以从流中不断读取内容的迭代器
- 给函数io.lines()提供一个文件名,它就会以只读方式打开对应流文件的输入流,并在到达文件末尾后关闭该输入流
- 若调用时不带参数,函数io.lines()就从当前输入流读取
- 我们可以把函数lines当做句柄的一个方法
- 此外,从Lua 5.2开始,io.read()的参数也可以在io.lines()中使用。例如,下面的代码会以在8KB为块迭代,将当前输入流中的内容复制到当前输出流中:
for block in io.input()::lines(2^13) doio.write(block)
end
三、其他文件操作
io.tmpfile()
- 该函数返回一个操作临时文件的句柄,该句柄是以读/写模式打开的
- 当程序运行结束后,该临时文件会被自动移除(删除)
flush()
- 函数flush将所有缓冲数据写入文件
- 与函数write类似,我们也可以把它当做io.flush()使用,以刷新当前输出流
- 或者把它当做方法f:flush()使用,以刷新流f
setvbuf()
- 该函数用于设置流的穿冲模式
- 参数:
- 参数1:是一个字符串。"no"表示无缓冲;"full"表示在缓冲区满时或者显式地刷新文件时才写入数据;"line"表示输出一直被缓冲直到遇到换行符或从一些特定文件(例如终端设备)中读取到了数据
- 参数2:如果参数1位"full"或"line",则可以设置参数2,参数2代表缓冲区的大小
- 在大多数系统中,标准错误流(io.stderr)是不被缓冲的,而标准输出流(io.stdout)按行缓冲区。因此,当向标准输出中写入了不完整的行(例如进度条)时,可能需要刷新这个输出流才能看到输出结果
seek()
- 该函数用来获取和设置文件的当前位置,常常使用f:seek(whence, offset)的形式来调用
- 函数参数:
- whence参数:该参数是一个指定如何使用偏移的字符串,可以设置的值如下
- set:表示相对于文件开头的偏移,以字节为单位
- cur:表示相对于文件当前位置的偏移,以字节为单位
- end:表示相对于文件尾部的偏移,以字节为单位
- offset参数:根据参数whence,设置偏移值
- 返回值:返回当前新位置在流中相对于文件开头的偏移
- whence的默认值为"cur",offset的默认值为0。因此:
- 调用f:seek():不以任何参数调用该函数,该函数返回流在文件中的当前位置
- 调用f:seek("set"):会将位置重置到文件开头并返回0
- 调用f:seek("end"):会将位置重置到文件结尾并返回文件的大小
- 下面是一些演示案例:
function fsize(file)local current = file:seek() -- 保存当前流偏移位置local size = file:seek("end") -- 获取文件大小file:seek("set", current) -- 恢复当前位置return size
end
os.rename()
- 该函数用于文件重命名
- 这个函数处理的是真实文件而非流,所以它们位于os库而非io库
os.remove()
- 该函数用于移除(删除)文件
- 这个函数处理的是真实文件而非流,所以它们位于os库而非io库